Ksenia_TuringPost أُعيد تغريده

NVIDIA's Nemotron 3 is an architectural response to the 2 pressures:
- Long-context cost as agentic interactions scale
- Repeated reasoning cost from invoking full models for small subtasks
Nemotron 3 proposes several design decisions to solve this:
▪️ Hybrid architecture: Transformer + Mamba 2 layers for efficient long-context processing
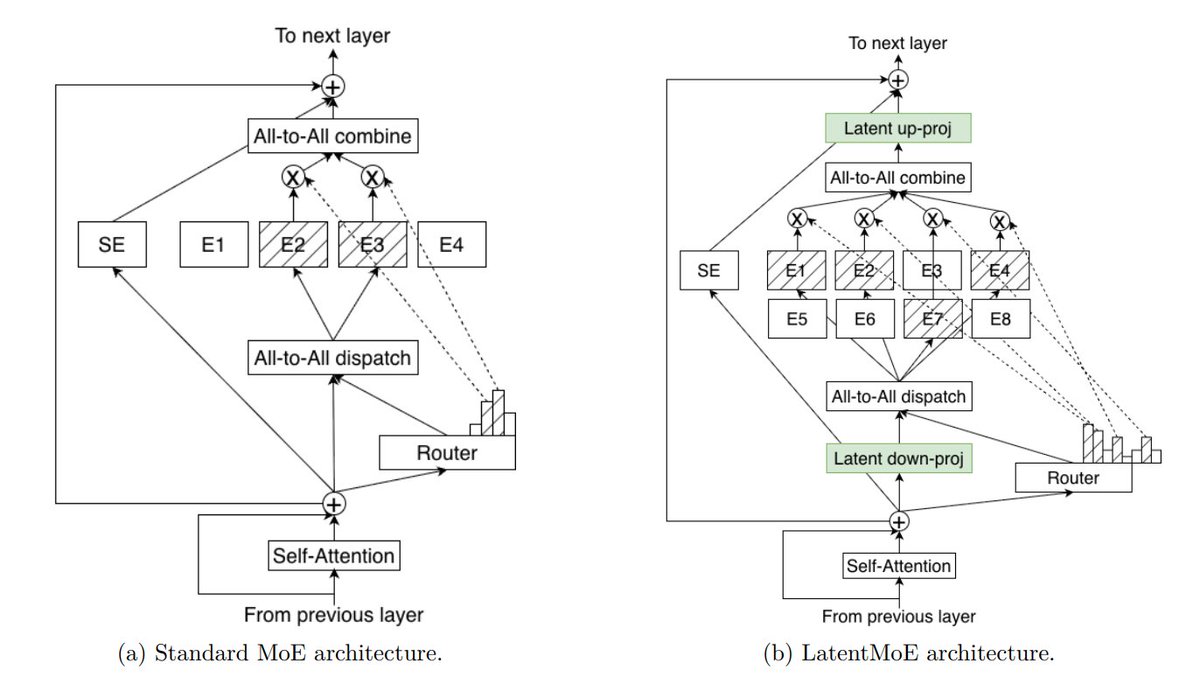
▪️ Mixture-of-Experts (MoE) and LatentMoE on top of it to get cheaper experts
▪️ Multi-token prediction
▪️ NVFP4 precision = 4.75 bits used for inference and pre-training, allowing Nemotron pre-training dataset achieve up to 4× faster convergence than standard open web datasets.
This is all about one key idea – "Acceleration is intelligence"
Here is the tech stack explained and what the Nemotron Coalition is – NVIDIA has just announced that this alliance of leading players like Cursor, Mistral, Black Forest Labs, etc., is gathering to develop the Nemotron family of open models → turingpost.com/p/nemotroncoal…
English