s◎last◎rm
5.9K posts


s◎last◎rm
@__solastorm__
Retired algo & HFT engineer. Nerd. Degen. Lazy. 🤖 🇺🇸🇪🇺🇺🇦🇬🇧🏴🇨🇦


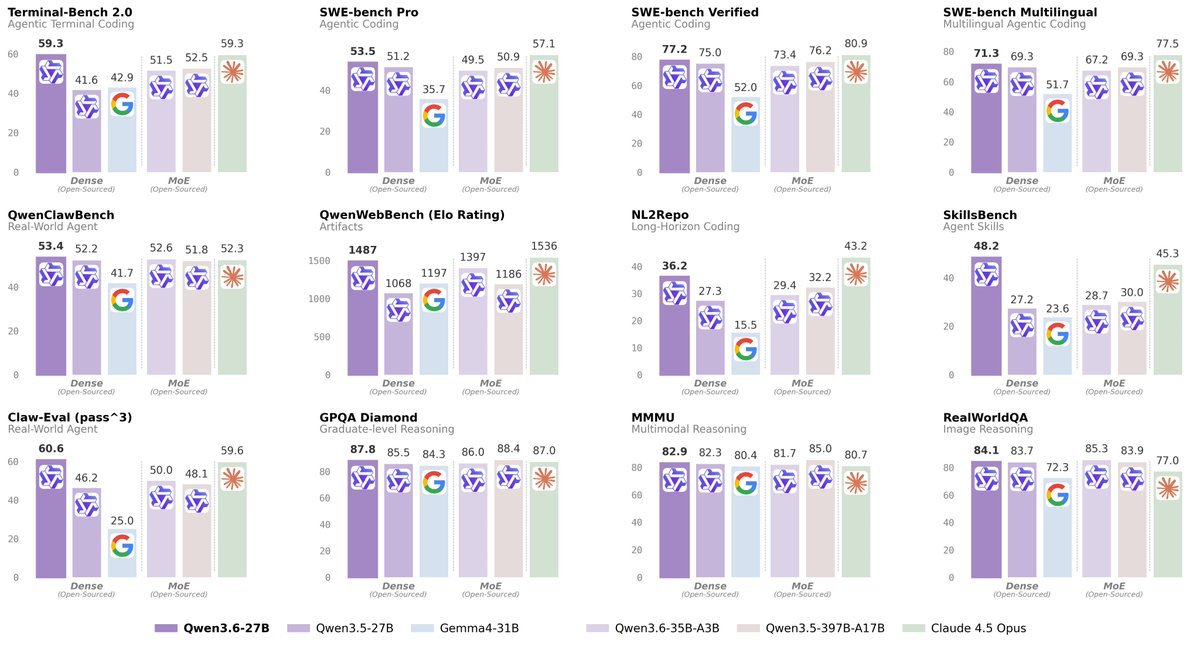
Local LLM Cheat Sheet Master Collection: All Tiers (April 2026) Bookmark this thread to access the top LLMs for your exact hardware and use case 🧵




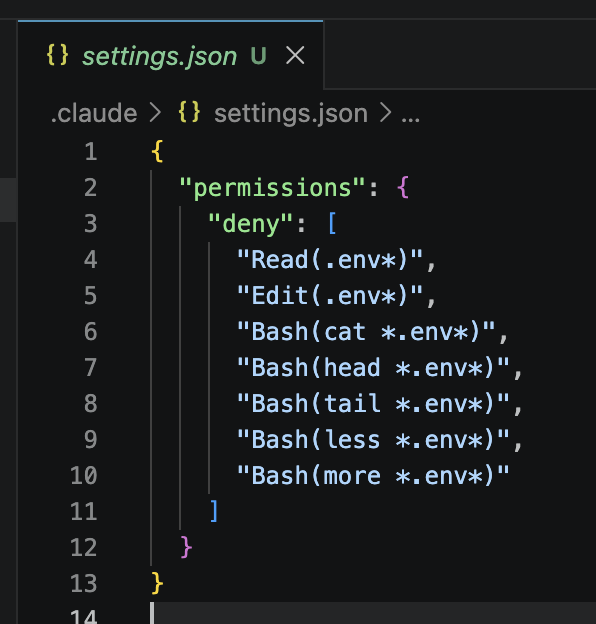
DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE DON’T LET CLAUDE READ YOUR ENV FILE









🚨🚨WAR CRIME ALERT!!🚨🚨- Trump on Iran: "A whole civilization will die tonight, never to be brought back again. The definition of genocide is destroying an entire civilization/people! Trump literally sounds like an unhinged super villain from a Marvel comic movie. This IS NOT WHAT WE VOTED FOR!!!

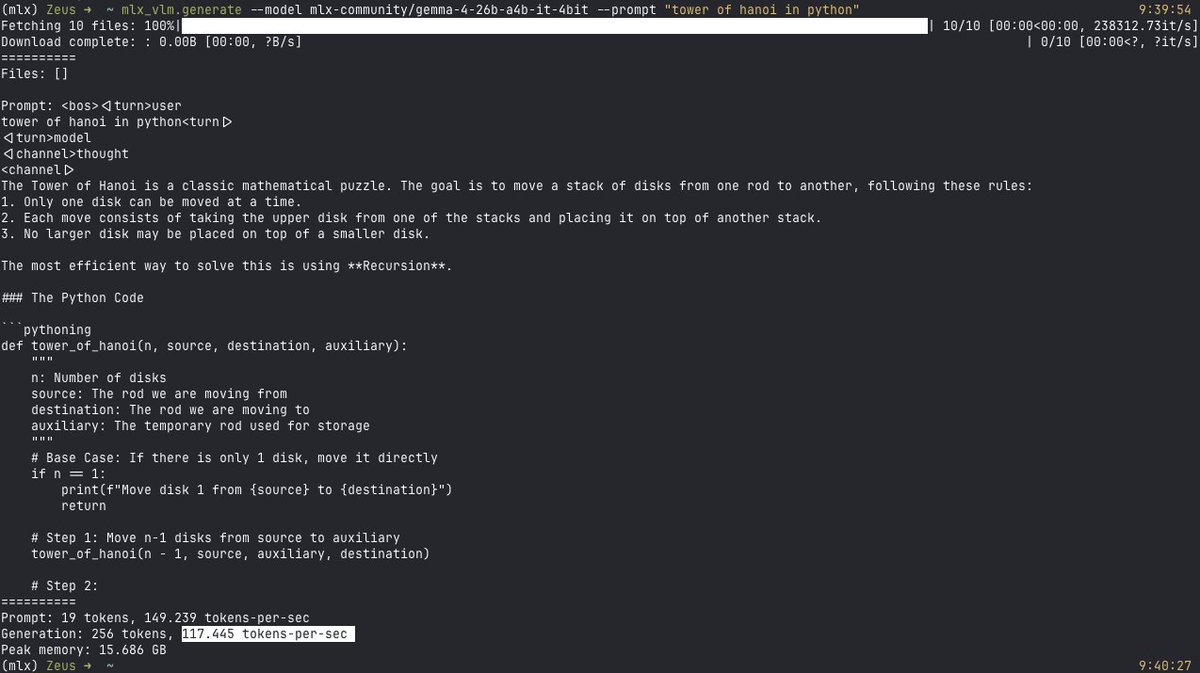
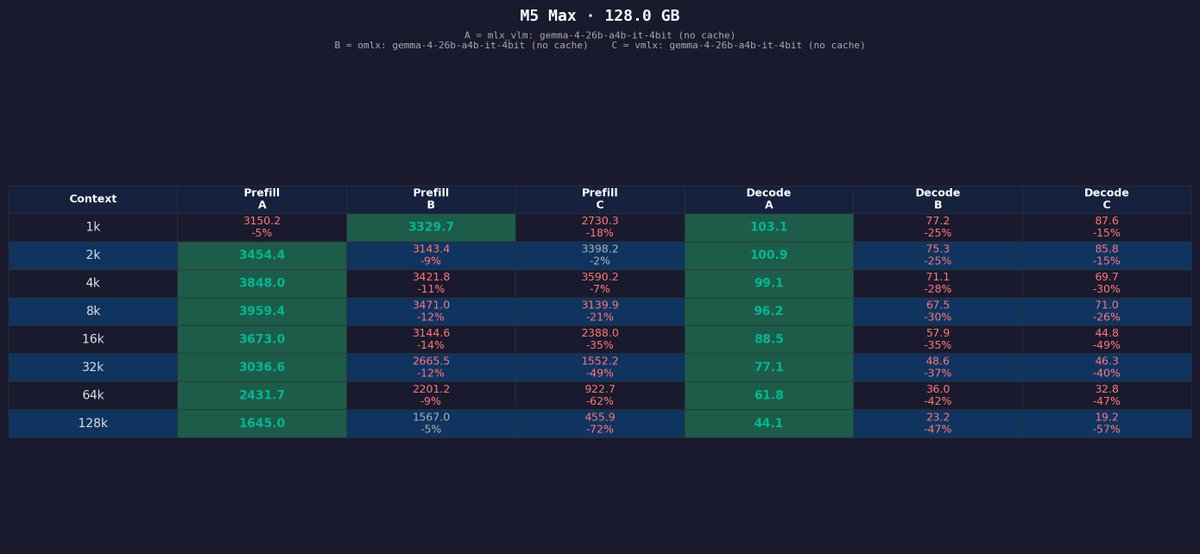
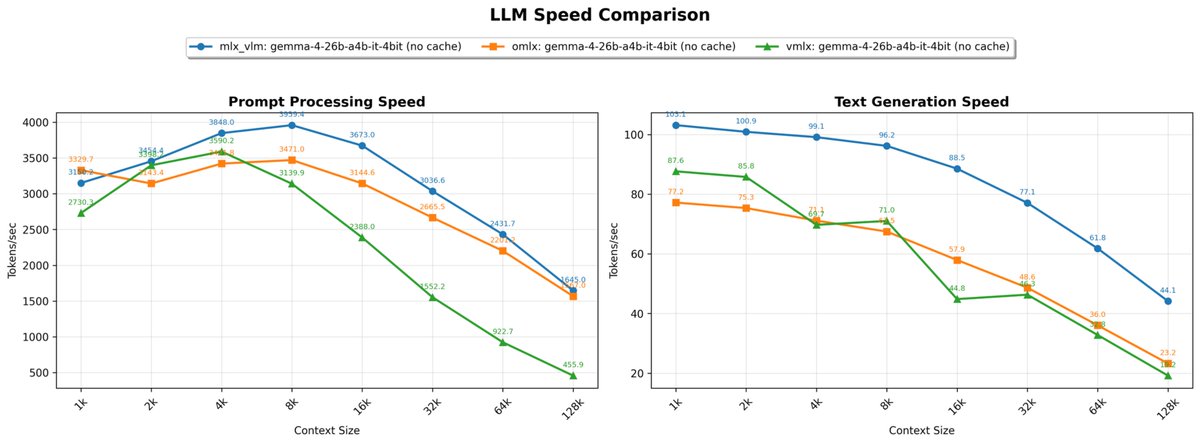
first Gemma 4 test on the M5 Max MBP Gemma 4 31B it 4bit running locally at ~28 tok/s via mlx-vlm



Theo is all of us rn