orkun
202 posts






life changing



JUST IN: Strait of Hormuz traffic reaches highest level since war began



the expectations for DeepSeek-V4 might be higher than for GPT-5 they should just ship it and iterate with 4.1, 4.2, ...


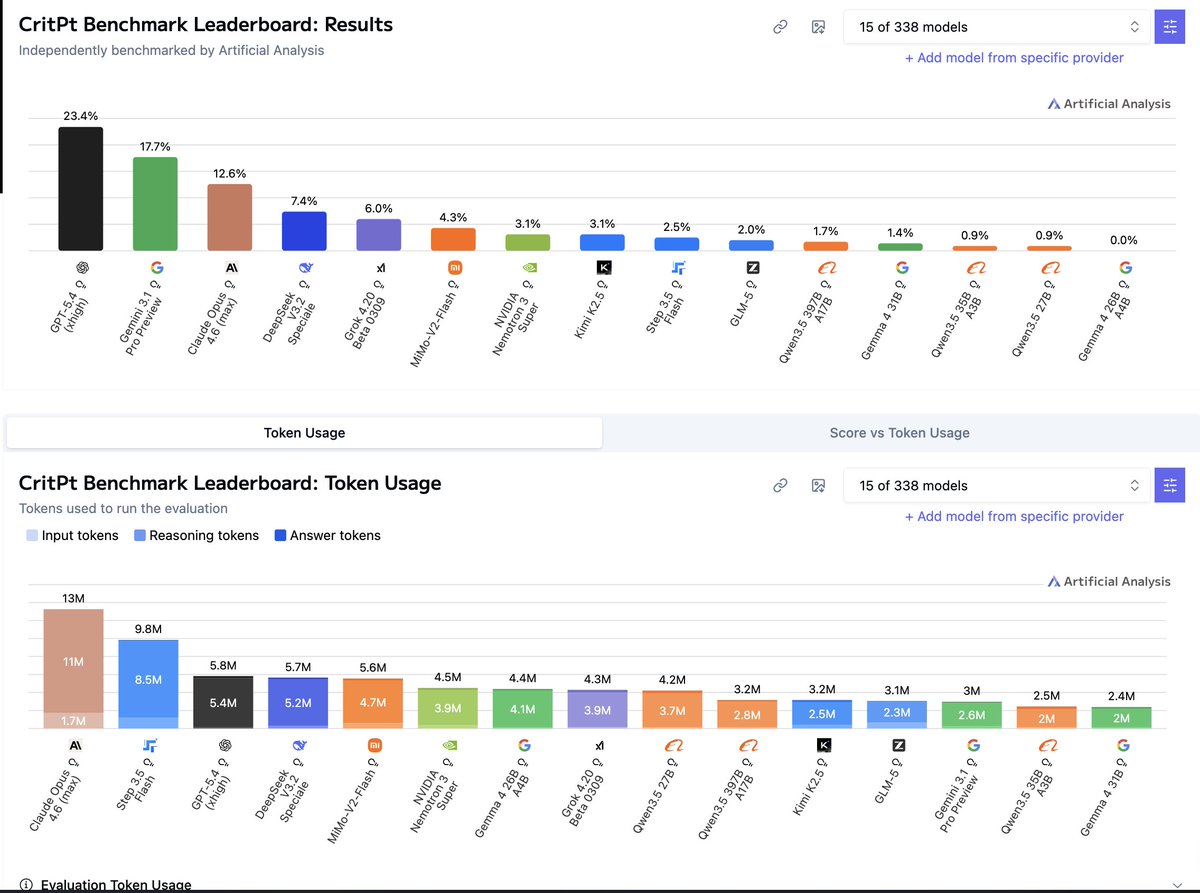
Google has released Gemma 4, four open weights models with multimodality support. The flagship 31B model (39 on the Intelligence Index) uses ~2.5x fewer output tokens than Qwen3.5 27B (Reasoning, 42) but trails it by 3 points on intelligence @GoogleDeepMind's Gemma 4 includes four sizes: Gemma 4 31B (dense, 39 on the Intelligence Index), Gemma 4 26B A4B (MoE, 4B active, 31), Gemma 4 E4B (8B, 19), and Gemma 4 E2B (5.1B total, 2.3B active, 15). Gemma 3 was instruct-only at 27B, 12B, 4B, 1B, and 270M; Gemma 4 adds reasoning mode, native video and image support across all sizes (with audio input for Gemma 4 E2B and E4B), doubled context windows, and Apache 2.0 licensing. The nearest open weights models by intelligence to the 31B are Qwen3.5 27B (Reasoning, 42), GLM-4.7 (Reasoning, 42), MiniMax-M2.5 (42), and DeepSeek V3.2 (Reasoning, 42). Qwen3.5 also supports images and video natively; DeepSeek V3.2 and MiniMax-M2.5 are text-only. Key benchmarking results for the reasoning variants: ➤ Gemma 4 represents a large intelligence jump over Gemma 3. Gemma 4 31B (Reasoning, 39) is +29 points over Gemma 3 27B Instruct (10), Gemma 4 E4B (19) is +13 points over Gemma 3n E4B Instruct (6), and Gemma 4 E2B (15) is +10 points over Gemma 3n E2B Instruct (5). Context windows also doubled from 128K to 256K for the larger models, and increased 4x from 32K to 128K for E2B and E4B ➤ Gemma 4 31B (Reasoning, 39) trails Qwen3.5 27B (Reasoning, 42) by 3 points, primarily due to weaker agentic performance. On non-agentic evaluations, the models are more competitive: Gemma 4 31B leads on SciCode (43% vs 40%) and TerminalBench Hard (36% vs 33%), while scoring similarly on GPQA Diamond (86% vs 86%), IFBench (76% vs 76%), and HLE (23% vs 22%) ➤ Gemma 4 31B is notably token efficient, using 39M output tokens to run the Intelligence Index vs 98M for Qwen3.5 27B (Reasoning). This is ~2.5x fewer output tokens for a model scoring 3 points lower. For context, the other models at the 42-point intelligence level also use significantly more tokens: MiniMax-M2.5 (56M), DeepSeek V3.2 (Reasoning, 61M), and GLM-4.7 (Reasoning, 167M) ➤ Gemma 4 26B A4B (Reasoning, 31) activates just 4B of its 27B total parameters and is ahead of select peers in the ~3-4B active parameter range. Qwen3.5 35B A3B (Reasoning, 37) leads models with ~3B active parameters and is 6 points ahead of Gemma 4 26B A4B, with notably stronger agentic capabilities (Agentic Index 44 vs 32). GLM-4.7-Flash (Reasoning, 30) scores slightly lower than Gemma 4 26B A4B with 3B active parameters ➤ The smaller Gemma 4 E4B and E2B models perform better on AA-Omniscience than the larger Gemma 4 variants. Gemma 4 E4B scores -20 on AA-Omniscience and Gemma 4 E2B scores -24, both substantially better than Gemma 4 31B (-45) and comparable to or better than much larger models like DeepSeek V3.2 (Reasoning, -21). The larger Gemma 4 models' AA-Omniscience scores are in line with Qwen3.5 27B (-42) and Gemma 4 26B A4B (-48) ➤ Gemma 4 E2B has 2.3B active parameters and 5.1B total, designed for on-device deployment. In 4-bit quantization, the model weights fit in under 3GB of RAM, making it suitable for background tasks, basic function calling, and multimodal understanding on mobile and edge hardware Key model details: ➤ Context window: 256K tokens (31B, 26B A4B), 128K tokens (E4B, E2B). ➤ Multimodality: All models support text, images, and video input. E2B and E4B also support native audio input ➤ License: Apache 2.0. Gemma 3 models are available under a "Gemma Terms of Use" license ➤ Size/Parameters: 31B dense, 27B total/4B active (26B A4B MoE), 8B (E4B), 5.1B total/2.3B active (E2B) ➤ API availability: The two larger models are available for free on Google AI Studio. There are several third-party providers hosting the larger Gemma 4 variants such as @novita_labs, @LightningAI, and @parasailnetwork


.@GoogleGemma 4 31B is up to 2.7X faster on RTX using llama.cpp. Thanks to @ggerganov for working with us to make this model fast.