تغريدة مثبتة

Sourya Kakarla
1.2K posts

@curious_queue
building something open. inspired by: unix philosophy, etymology. led ML @tryskylink (YC W22; acq. by @AmadeusITGroup). ex-@microsoft | @columbia @iitkgp

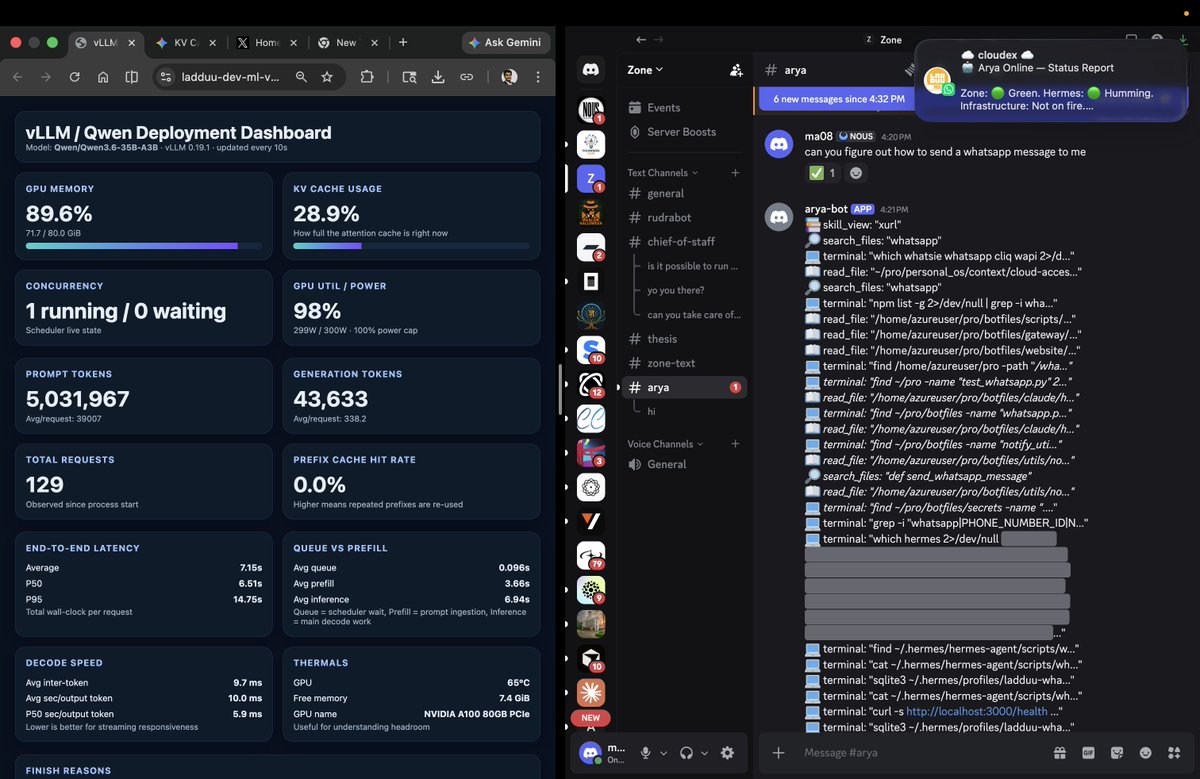
just had a magical open experience - deployed Qwen3.6-35B-A3B on a VM (with an A100 GPU) - set up a hermes agent profile to use this self-hosted model - gave it a task of sending me a whatsapp message (as i wanted to see if it was able to figure out how from my existing stack without receiving any explicit instructions of what was present where) ✅ it took 2-3 interventions from me to guide it in ambiguous situations but got the job done!! - this is the first time i got an openweights model whose inference I was managing end to end to execute a complex task using non-trivial amount of chained tool calls - seeing the reasoning and the trajectory of tool usage definitely felt impressive!! especially considering the baseline i was used to was gpt-5.4 xhigh in codex - tried gemma 4 recently for a similar experiment but its tool usage wasn't polished enough for this kind of open ended procedural discovery + execution (could be just model-tool-harness plumbing issues tbh) - though i've been tracking the general openweights capability progress over last few months passively, actually witnessing the agentic actions run with end-to-end control of the stack was surreal this was my "hello world" of implementing ~sovereign complex agentic actions. long way to go ofc. amped to to dig deep into self-hosted/openweights inference and tuning models/harnesses to be reliable enough to daily drive more. gg @TheAhmadOsman @NousResearch. amazing work on pushing forward the community discourse on open weights/harnesses.
> 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge) true! also, the actual act of fleshing out the verification artifact that the model can run in a loop (like your autoresearch and @GeoffreyHuntley's ralph loop) takes a very high bar when you consider the overall distribution of LLM/agent use if i want any work to be done by an agent reliably (not just wing/vibe it), my job is now to have a mental model of how to elicit that verification artifact verification by human senses is a bottle neck for the agents to leverage their actual superpower (relative to humans) of running stuff in a loop fast and checking (can be ofc scaled with parallel like in the recent claude mythos-glasswing project) while the actual implementation act of eliciting the verification artifact is made easy by the agents by taking care of the grunt work of writing code, knowing how to elicit that is still a lot of skillful mental work that acts as a filter for people feeling the AGI autonomous task execution by agents needs to be powered by verification engineering by humans like all the previous transitions (punch cards -> assembly -> C -> Java/Python -> Agents), feels like we are moving higher up in the abstractions and there is always *something* to be done by humans feel free to roast me if i got anything wrong :p would love to learn from the sensei :)

A neat thing we’ve been experimenting with: Codex workout sessions. Getting Codex to close the loop and validate its work is critical for higher complexity changes. To do that we want skills for high level workflows: “log in”, “upload file attachments and start a chat”, “grant this group access to a Workplace Agent”. To do this reliably, we’ve been getting Codex to iterate on its own skills by planting “flags” CTF-style in the UI and ralphing Codex using automations in the app, making commits to iteratively refine the skills after self reflection on each attempt. Capturing the flag is the win condition and from there codex optimized for reliability, wall clock time, and keeping up to the changing codebase. Put in the reps with your agents!


New best local model for y'all 16GB-64GB rejoice, the chosen one has arrived. huggingface.co/Qwen/Qwen3.6-2…



Stronger Across Languages ChatGPT Images 2.0 can produce images with non-English text that’s not only rendered correctly but with language that flows coherently. This makes the model more globally useful and helps people create visuals that work in the languages they actually use.

mfers that bookmark a post but don't like it are a special breed



@0xSero @steipete's oracle CLI has been working great for me in consulting gpt-5.4-pro: github.com/steipete/oracle here's the skill I use to make codex play well with it: github.com/ma08/botfiles/…
definitely, right now i've resorted to using the traditional cascade pipeline to be able to use the gpt-5.4 model i was okay with the increased latency to be able to chat with gpt-5.4 (cached inputs and its dynamic reasoning depth make it reasonably fast tbh) the discord voice channel experience in hermes is pretty good for this: #voice-messages" target="_blank" rel="nofollow noopener">hermes-agent.nousresearch.com/docs/user-guid…
i had to fork it to add support for the STT provider i wanted though (kudos to @NousResearch's hermes agent that it was able modify its own code to make this happen) we can do much better than the cascade of STT->LLM->TTS by using some novel architectures like the oracle/supervisor that can bridge realtime audio experience with deep reasoning horsepower
