
Jon Deaton
44 posts

Jon Deaton
@deaton_jon
Research Scientist at @GoogleDeepMind
San Francisco, CA انضم Kasım 2012
178 يتبع100 المتابعون

is there a variant of bayesian inference where evidence that is aligned with the prior is weighted non linearly more than evidence that contradicts it?
English

@mrkocnnll @longstosee I think the lack of violence in the modern world is weirder than the instincts to defend your kin tbh
English





@kvfrans pallas is the way to get what you want when xla doesn't do it
English

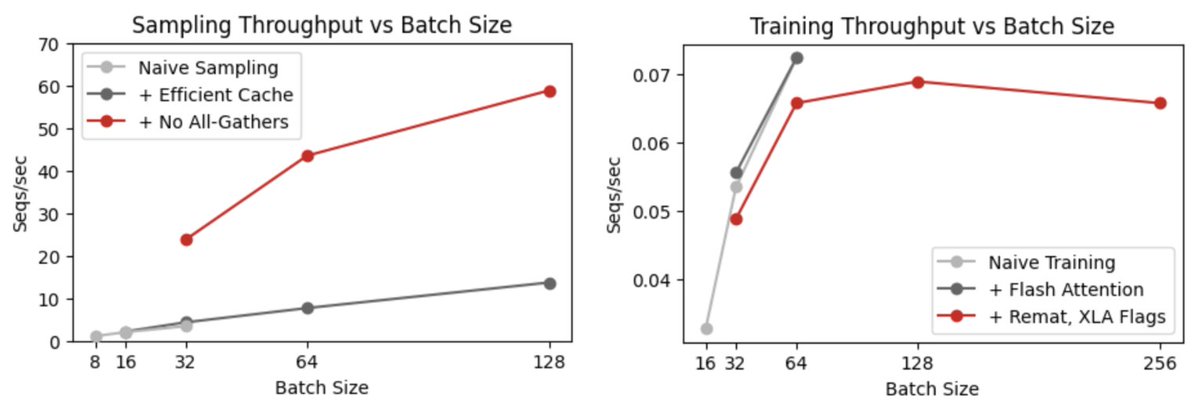
New notes: We've been building a research-friendly LLM-RL repo in JAX, and I recently took the time to optimize the sampling/training pipeline.
We're able to match vLLM sampling and get decent training batchsizes now!
notes.kvfrans.com/7-misc/rl-infr…
English
@francoisfleuret vae is an adversarial training dynamic are you expecting different curves
English

Weirdest graph ever, but this thing is robust. The recovery on Human Eval + is spectacular.
Anway version +1 already running, we'll see.


François Fleuret@francoisfleuret
English

Wife: <problem>
Me: <solution>?
Wife: I don’t want <solution>!
How do you get past this dynamic?
English

just out of vain curiousity ; what happens if you increase the complexity of attention? like, has anyone tried cubic attention lol
Lucas Beyer (bl16)@giffmana
> There’s no free lunch. > When you reduce the complexity of attention, you pay a price. > The question is, where? This is *exactly* how I typically end my Transformer tutorial. This slide is already 4 years old, I've never updated it, but it still holds:
English
@francoisfleuret I thought this was going to be a big problem especially in your sigma gpt but I found it doesn't matter
English
I really don't like that in the first layers X_t should be the representation of token t and gradually becomes that of token t+1 in the last layer. It makes absolutely no sense, it is objectively repugnant.
English


Ever wondered what CAN'T be transformed by Transformers? 🪨
I wrote a fun blog post on finding "fixed points" of your LLMs. If you prompt it with a fixed point token, the LLM is gonna decode it repeatedly forever, guaranteed.
There's some connection with LLMs' repetition issue.

English
uhhh if there is a value that should not be too large, I clamp it because otherwise it explodes. If it hits the clamping value, then when times come to make it smaller, the gradient does not propagate to reduce it?
English

Happy Pythagorean Triple Square Day!
Today’s date is made of 3 perfect squares and they form a Pythagorean triple: 3² + 4² = 5²
This only happens once a century.

English

You're absolutely right...
You're absolutely right...
You're absolutely right...
You're absolutely right, I shouldn't have run rm -rf on your home directory.
English

If after a week of profound reflexions you finally reinvent E-M, is it a
English
@thisismadani thats a neat trick you did to preserve the token positions of the span while doing fill-in-the middle. seems effective
English

What could scaling unlock for biology?
Introducing ProGen3- our next AI foundation models for protein generation. We develop compute-optimal scaling laws up to 46B parameters on 1.5T tokens with real evidence in the wet lab.
+we solve a new set of challenges for drug discovery
English

> wake up
> launch yet another YOLO run (600M H100 hours, powered by 16 suns)
> spend entire day anxiously refreshing wandb
> fuck, learning rate too high again
> beg manager for just one more YOLO run tomorrow
> go to bed and repeat
English

Drop the best documentary that you’ve seen. One that blew your mind and you couldn’t stop thinking about for weeks. I want something that will break my brain.
English
This is an incredibly cool plot - it shows how protein language models form internal representations of physical structure when trained only on amino acid sequences selected by evolution.
The representation fidelity scales with compute.
Alex Rives@alexrives
Information about protein structure in ESM C representations improves predictably with increasing training compute, demonstrating linear scaling across multiple orders of magnitude. (We overtrained the 300M and 600M models past the predicted point of compute optimality).
English