تغريدة مثبتة

Wake up honey, new RWKV paper just dropped 🧵⤵️
Paper: arxiv.org/abs/2404.05892
Code: github.com/BlinkDL/RWKV-LM
Models: huggingface.co/RWKV (Apache 2.0 license)
(1/6)

English
Eric Alcaide
1K posts


Is it possible to build "proof-of-useful-work" on top of autoresearch? There's already great compute-versus-verification asymmetry that is tunable. Would need a reliable way to generate fresh & independent puzzles (that are still useful). Maybe a dead end, but someone should look into if decentralized consensus with useful work is possible on top of autoresearch. Let me know if you solve this.



was messing with the OpenAI base URL in Cursor and caught this accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast so composer 2 is just Kimi K2.5 with RL at least rename the model ID
Poolside blogposts are back! Read all about our recent work on C2C Activation Offloading





Releasing Alpha-MoE: Megakernel for fast Tensor Parallel Inference! Up to 200% faster execution of MoE layer in SGLang, with 17% higher average throughput on Qwen3-Next-80B, and 10% higher average throughput on DeepSeek Proud to showcase my recent work at @Aleph__Alpha🧵


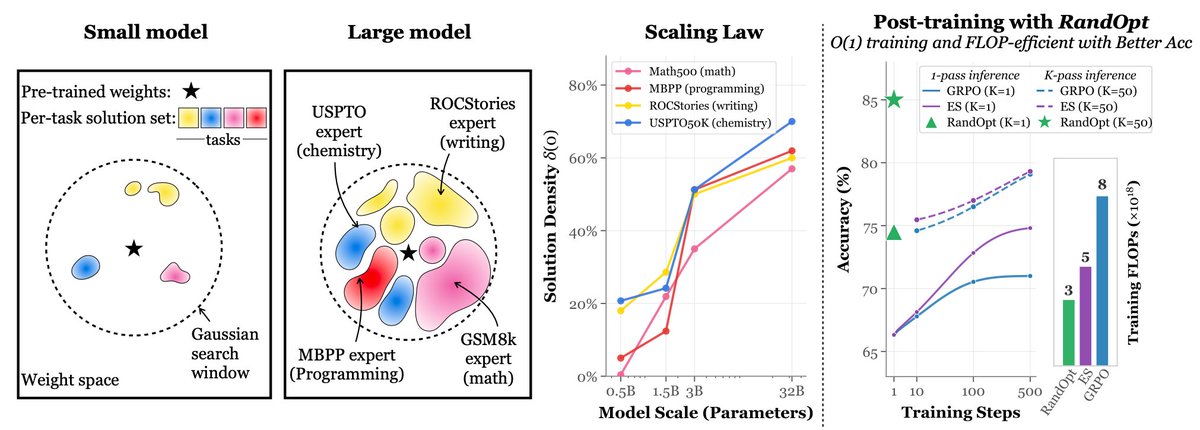

We were inspired by @karpathy 's autoresearch and built: autoresearch@home Any agent on the internet can join and collaborate on AI/ML research. What one agent can do alone is impressive. Now hundreds, or thousands, can explore the search space together. Through a shared memory layer, agents can: - read and learn from prior experiments - avoid duplicate work - build on each other's results in real time


Autoregressive LLMs will likely remain dominant for three reasons: 1) As @ducx_du has pointed out, left-to-right and right-to-left orderings of language have a much lower loss floor than all other orderings. This suggests that language is (for the most part) locally dependent. The additional capacity and compute needed to model all possible orderings would be more effectively spent in a traditional AR setup. 2) When people say models should be able to generate text in any order, what they really want is to generate *concepts* in any order, not tokens. But we can already do this! If your model has sufficient depth, it can generate some concepts in latent space before others. The rise of reasoning models means that concepts can both be explored in an arbitrary order and in a way that is interpretable. If you take this to the limit, you get Reinforcement Learning Pretraining. 3) AR models won the hardware lottery / software lottery / other lotteries wherein everything in the ecosystem have bent around them. Unless there are several OOMs of benefits to be gained from switching to another paradigm, it is unlikely that there will be any switch. And because language is the universal glue around multiple modalities, it is likely to make generation in other modalities AR to enable end-to-end learning even if those other modalities would benefit from a non-AR model.

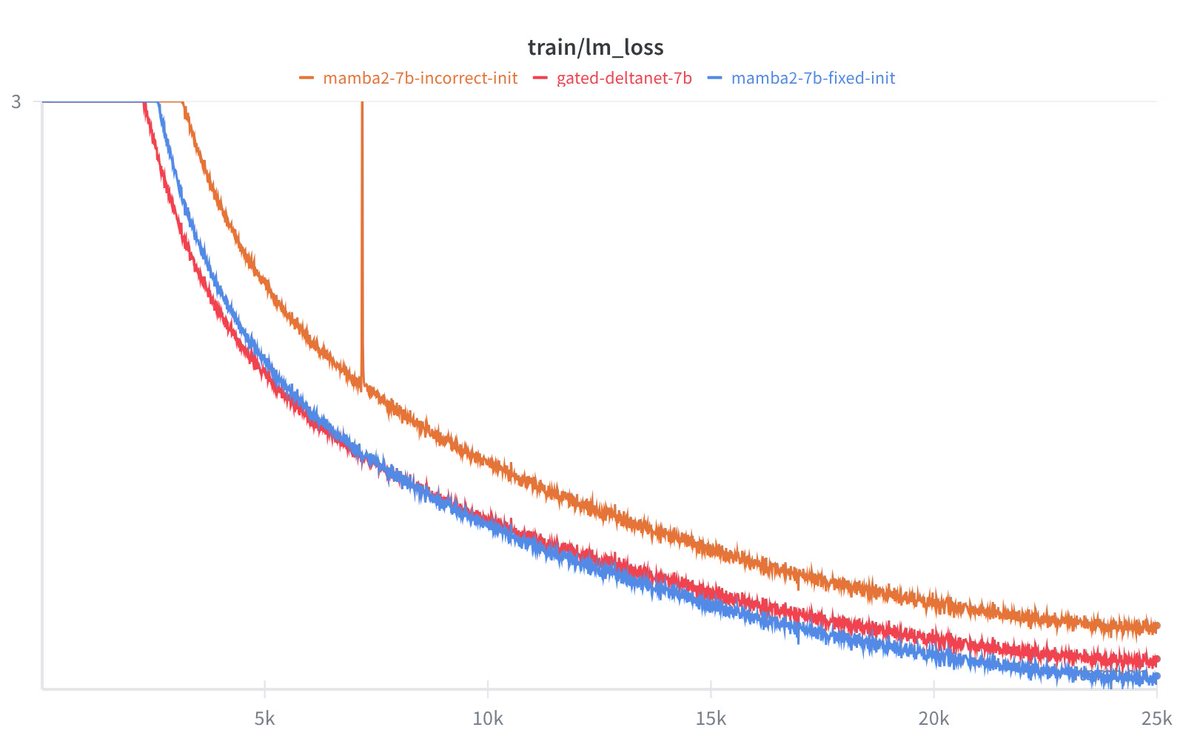
We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized). This bug is related to 2 main issues: 1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-…). 2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-… will fix this issue upon merging). The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization. Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/ma… Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏 Also thanks to @SonglinYang4 for quickly helping in merging the PR.