تغريدة مثبتة
Jonny
2.2K posts


Jonny
@jonnyboy
Jonny · Building Shepherdly the OS for pastors @ https://t.co/rWMoFldTpe
انضم Eylül 2024
171 يتبع231 المتابعون


If >50% of people press the blue button, everyone survives
Red button pressers always survive, but they’ll get a “red button presser” badge on their Twitter profile.
What do you press?
English



@jpschroeder the technical gap is now big enough to compensate for the goblin ui taste; where as before it wasnt
English

Everyone is moving to Codex.
1. Welcome and hello.
2. Why'd that take so long? 5.4 was > Opus too
English
@ashleybchae dario wants people to benefit from superpowerful ai; not necessarily have access to it.
English

I used to genuinely think that anthropic was like the Fellowship and openai was Sauron
but these days i’m starting to seriously question myself
i’ve also been using codex 5.5 90% of the time so..
nick@thecsguy
@ashleybchae Clearly Dario wants only one thing. Complete control.
English
@scaling01 no anthropic may actually have superstitioned a bad lab into existence.
English

everyone knows that:
worse model + bad PR = bad guys
Craig Weiss@craigzLiszt
anthropic might actually be the bad guys of this story
English

We beat Sonnet 4.6 with a 500B model. Bigger runs are on the way.
Artificial Analysis@ArtificialAnlys
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English

I've increasingly seen content written about me that's asserted very confidently but is also completely made up. We all know it's cheap to bullshit on the internet but it's weird to experience it first hand. Anyway, I just hope internet fiction fools a few but doesn't stick 🤷🏼♀️
English

@scaling01 this is basically sonnet 4.6 fast at half cost instead of doubling. 2 months ago and this would've shaken things up. you cant really sleep on any of these companies right now.
English



i have never understood the synthetic data skeptics
it's like they haven't played around with models at all, just stuck to whatever the prevailing view was
English
@jediahkatz @aye_aye_kaplan Misconception for sure… don’t sleep on the AGENT HARNESS COMPANY
English

Let's talk about why Cursor's agent harness is so good.
There's a misconception that first-party harnesses from the labs will always outperform. For many reasons, that isn't true.
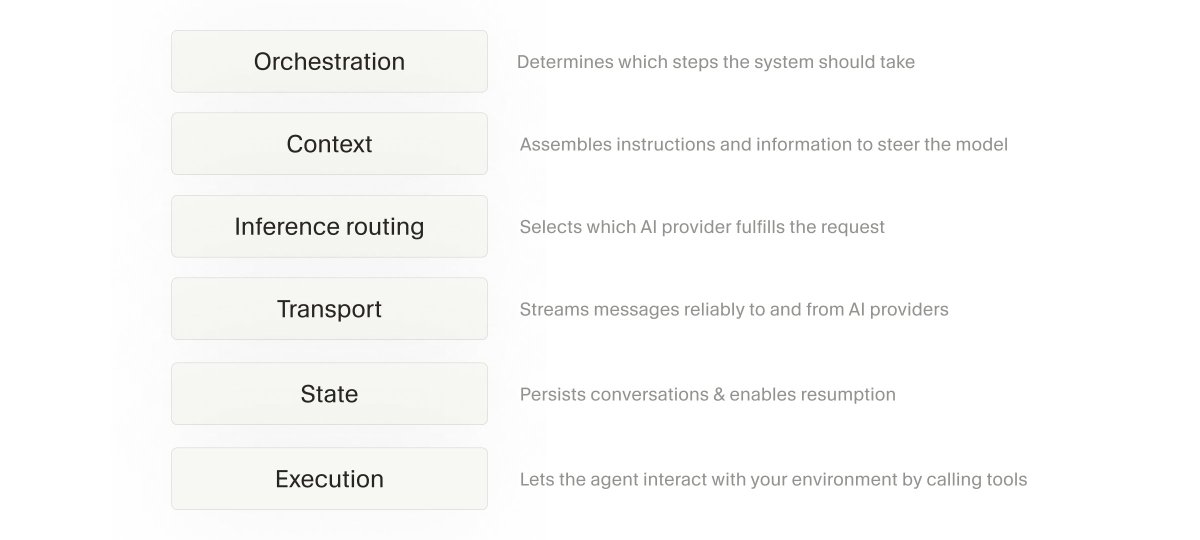
There are roughly 6 layers that go into a good agent harness: orchestration, context, routing, transport, state, and execution (tools). Some of those involve careful context engineering, and others look a lot like the traditional craft of building great software.
Each of these layers needs to be optimized. And if any one of them is degraded, it can severely impact your experience with the agent. This blog post is mostly focused on context and tools, and there's still so much more to talk about there. We also want to spotlight the other (very crucial!) areas soon.
There's a lot more misinformation around the agent harness out there. I'll keep writing about how we build it behind the scenes.
Cursor@cursor_ai
Our agent harness makes models inside Cursor faster, smarter, and more token-efficient. Here's how we test improvements to the harness, monitor and repair degradations, and customize it for different models. cursor.com/blog/continual…
English
@aaronp613 I mean anthropic publicly said Apple was one of the 12 with mythos access!
English


Say after about 10 seconds, this is not Gemini, but I am ready for Gemini @OfficialLoganK
English
Who Who’s ready for Gemini?
OpenRouter@OpenRouter
New stealth model: Owl Alpha! Owl is a high-performance foundation model designed for agentic workloads. Powerful tool use capabilities and a 1M context window, ready for use in all your favorite productivity apps. Try it now and share feedback to improve the model!
English