تغريدة مثبتة
astra
3.4K posts


astra
@novel_engineer
happiness for everyone harness engineering, novel human-agent UX, life optimisation, effective altruism
signal/noise انضم Mart 2023
1.3K يتبع94 المتابعون
astra أُعيد تغريده

After 100 million tokens, performance was still going up. What we're seeing here is not the capability ceiling.
From the report: "Performance on TLO continues to scale with the amount of inference compute spent, and we have not yet observed a plateau with the best models."
AI Security Institute@AISecurityInst
OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
English
Very few realise the incredible capabilities and trajectory of intelligent systems.
The world is going to change dramatically.
Research, work, life.
Look at all the structures, items, processes, behaviours built with intelligence - but with alien intelligence.
Scale, optimisation, quality, efficiency.
Happier
English

Don't just reset Codex rate limits for fun, it costs money.
Don't just reset Codex rate limits for fun, it costs money.
... but the vibes are good ...
I have reset Codex rate limits for ALL paid plans to celebrate a good week and allow everyone to build more with GPT-5.5. Enjoy
English
Absolutely. Especially e2e automating it.
Still optimising the flow and permissioning notification for post-sandbox integration testing with other systems.
Often the logic can look and test great in-repo but lacks knowledge of the edge case internals of other upstream/downstream systems.
English
astra أُعيد تغريده

Every company should have a full stack team of 5 building a product who are banned from directly writing code; they must force the agents to do it. In 2 months they will be your most productive team.
English
@SteveStuWill It's also the other way around: 'heritable' 'genes' is influenced by the environment too.
English

“Not only are all psychological traits heritable, but the environment is heritable too. Even variables we think of as entirely environmental - parental treatment, social support, major life events - are shaped in part by our genes.”
stevestewartwilliams.com/p/top-10-most-…
English
@GergelyOrosz Games are just harder to test - especially guessing gameplay from world rules.
It doesn't generalise outside your example
English

The only people who believe any of this are non-coders.
I tried to build a game (an area I’m an n00b in.) The results are amusingly disastrous - I never before coded a decent game.
But I’ll crack out backend services w AI rapidly - because I coded dozens of them before…
AI Edge@aiedge_
Anthropic CEO (Dario Amodei): "Coding is going away first, then all of software engineering." What do you think about this?
English
astra أُعيد تغريده


astra أُعيد تغريده

Our survey results have found that:
"Very liberal" Americans support political violence at higher rates than other political groups.
Black GenZ Americans support political violence at higher rates than other race/age groups.
Those with graduate degrees support political violence at higher rates than other education groups.
These data come from the American Political Perspectives Survey (APPS) collected from August 3, 2025, to September 26, 2025, with 3,000 American adults who speak English. All respondents needed to pass (1) attention checks, (2) a duplication check, (3) time-to-completion checks, (4) fraud and (5) bot-identification checks. For more information, see: research.skeptic.com/american-polit…



English
@a1zhang @zli11010 @lateinteraction Spending more compute to get more performance in some cases is great.
Curious how much more it'll cost for the same question/benchmark
English

New mini experiment + blogpost + trajectories!
tldr; we boost performance of RLM(GPT-5.2) to double the best performing number (38.7% --> 65.6%) on LongCoT-mini without any training! An example of the mismanaged geniuses hypothesis (MGH) we (@zli11010, @lateinteraction) proposed earlier this month.
The LongCoT benchmark showed that frontier LMs and RLMs struggled to solve difficult compositional reasoning tasks. The paper generally attributes this to the RLMs inability to perform task decomposition, but we argue this is more our fault in how we prompt them; this capability is fully available to GPT-5.2 with an RLM harness!
Building on @raw_works's insightful blogpost and @sumeetrm / @CharlieLondon02 et al.'s incredibly useful benchmark, where they originally found RLMs to be incapable of solving the MATH and CS splits altogether. We did not train anything since the release of the initial benchmark.
To be fully transparent, these results are not meant to be added to their leaderboard either; benchmarks measure isolated capabilities, and we focus on showing (through different, rather specific prompting) that the capabilities required to solve these tasks are available to the models without additional training! It also has implications about how we would go about training these systems. Full blog below, it's a nice read :)

English
@tmkadamcz Isn't it possible to just ask the model to read it whole or add a hook that adds it to the user prompt?
Better context optimisation by default seems good.
English

Controlling the context is the essence of skilled LLM use. The flagship products are taking that control away from users, presumably to reduce token usage. I'm now having to use third-party frontends (e.g. TypingMind).
English
AFAICT, there is no longer a way to put an entire long (~20k tokens) file into an LLM's context, when using OpenAI and Anthropic's products (both coding agents and official chatbot frontends).
English
@TheAmolAvasare I love anthropic but this is a lie.
Dramatic limit changes were immediate
English

Like I said before, if anything does change, we'll give folks a heads up well in advance.
Sorry for the confusion on this one...
English
Getting lots of questions on why the landing page / docs were updated if only 2% of new signups were affected.
This was understandably confusing for the 98% of folks not part of the experiment, and we've reverted both the landing page and docs changes.
Amol Avasare@TheAmolAvasare
For clarity, we're running a small test on ~2% of new prosumer signups. Existing Pro and Max subscribers aren't affected.
English
astra أُعيد تغريده


happy sunday morning. a new LongCoT king is crowned.
👑Qwen3.5-27B-Instruct + dspy.RLM
yes that's right, a 27B model more than double GPT 5.2 by using recursive language models
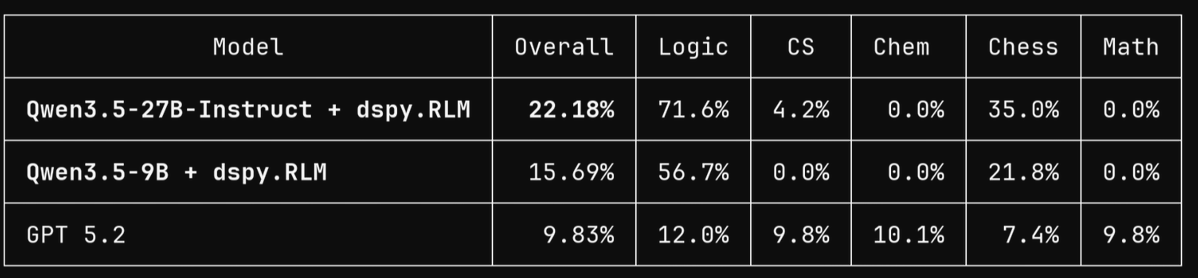
Raymond Weitekamp@raw_works
sorry it took me ~50 hrs! now i've got DSPy.RLM as SOTA on LongCOT (Full) by a very large margin, using... ...drumroll... Qwen 3.5 9B! 👑 Qwen3.5-9B + dspy.RLM = 15.69% on LongCoT-full 🔥 ~1.6× GPT 5.2's 9.83% on the same slice!
English
@BasedInHealth They absolutely would not do it without reason. It increases inference cost for them too. It underlies the entire model's functioning. They clearly saw intelligence gains from it. If cost is a concern to you then maybe Opus isn't for you
English


I compared the Opus 4.7 tokenizer against the Opus 4.6 one on the system prompts of Claude Design, Claude Code and Claude Cowork.
Opus 4.7 tokenizes to between 1.35-1.40x more tokens than Opus 4.6
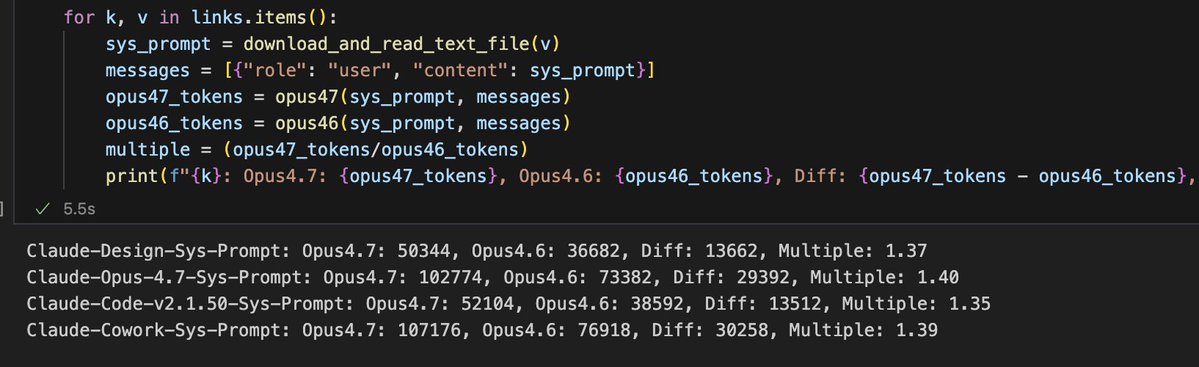
wh@nrehiew_
The 4.7 tokenizer treats whitespace as separate tokens? A string consisting of 50 one-token words separated by Whitespace tokenizes to ~50 more tokens than with the 4.6 tokenizer. If so, the 1.35x more token estimate seems way too low.
English

Opus-4.7 is unusable.
Multiple times i have given it specific links, for it to use, specifically. Instead it goes finds unrelated links, starts expensive processes, and goes for hours in a completely wrong path.
No ability to infer intent.
Wasted 200$ worth HF credits. lol
English
@JeremyNguyenPhD From the docs, adaptive thinking seemed to reduce thinking occasionally vs think all the time. I certainly saw thinking since disabling it. It may be different for 4.7 but it worked well for me x.com/i/status/20448…
Philippe Tremblay@ptremblay
@bcherny Does this still work? And if so, what's the max for 'max_thinking_tokens'?
English

@novel_engineer Does that just means we never get extra thinking?
English
Does Opus 4.7's release feel different to you?
Normally we have to brace ourselves for the hype threads about who just got killed, or a bunch of animations
But this time it seems the big thing that obviously affects us is "adaptive thinking", and it's not necessarily good
English
@NewsFromGoogle @GeminiApp are you still goin g to force me to click pro every time and fail to load/answer my question every time?. genuinely worst AI UX ever.
English

We're introducing a new Search experience in Chrome in the U.S. today that makes it easier to access and engage with content and dive deeper into what you find, all without switching tabs. Now, when you click on a webpage from AI Mode in Chrome desktop, it opens side-by-side with your conversation so you can reference the context of your search, ask follow-up questions and more.
English

23andMe is all about tapping the potential of the genome to truly personalize healthcare & prevent disease, and AI is going to make this happen better and faster. But I feel strongly that it has to be guided by strong science and quality source data -
Patrick Collison@patrickc
I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools. With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments. Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know. I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars. (One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.) There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!
English