تغريدة مثبتة

~/ harshit 🌪️
1.2K posts

@pantharshit007
Full-stack guy here with a little 🤏 knack for design. What I do: Code and yapp in meetings.



Day 15.5 of travelling in faridabad for my internship 🥰🥰 @MCF_Faridabad tell me when you guys will build sector 91 main road palla ismailpur road > Tender pending since 2019 > @MCF_Faridabad are people living in this area pakistanis who don't deserve good roads > @MCF_Faridabad @KPGBJP 🤡🤡

This coffee shop only hires down syndrome employees. ❤️



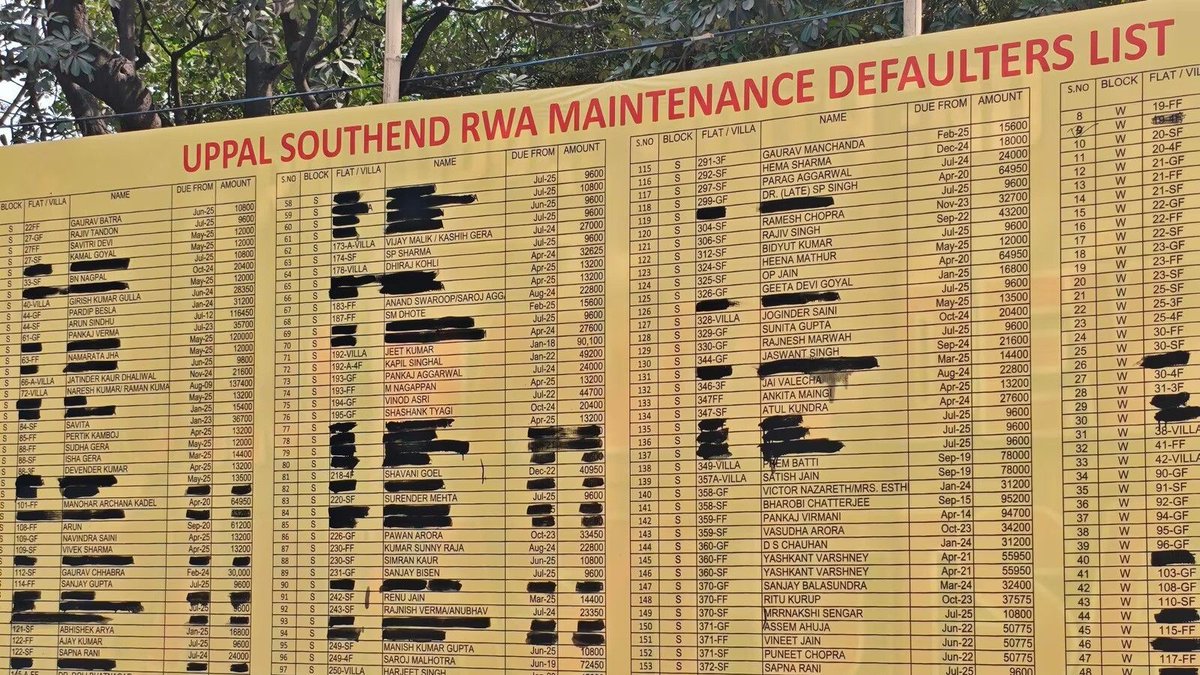

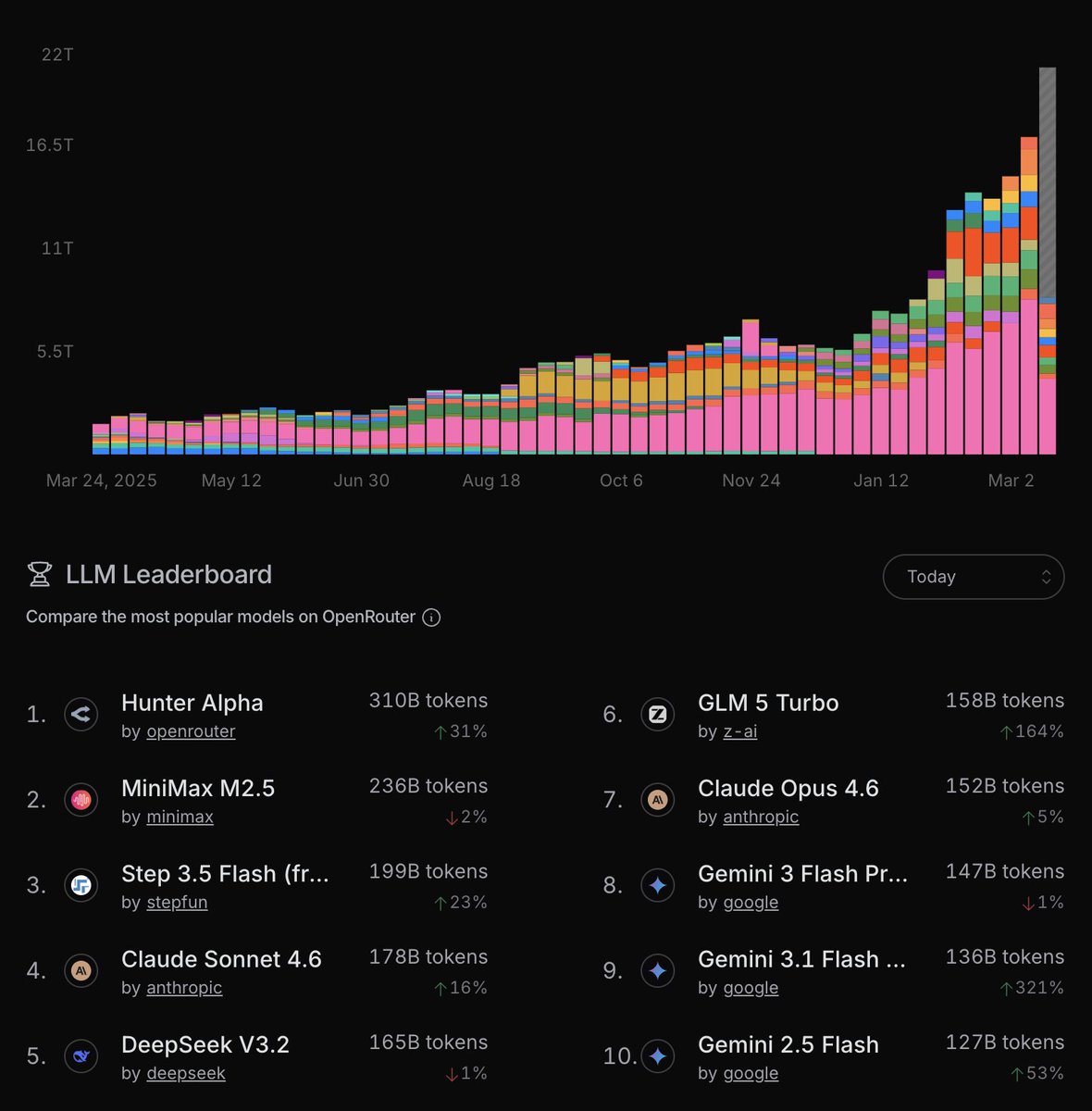
The Hunter Alpha stealth model is now in the top 10 weekly:




Xiaomi has released MiMo-V2-Pro, which scores 49 on the Artificial Analysis Intelligence Index, placing it between Kimi K2.5 and GLM-5 @Xiaomi's MiMo-V2-Pro is a new reasoning model and a significant upgrade over their prior open weights release, MiMo-V2-Flash (309B total / 15B active, MIT license), which scores 41 on the Intelligence Index. Xiaomi has not yet released the weights of this model and it is currently only available via Xiaomi's first-party API. Key takeaways: ➤ MiMo-V2-Pro scores 49 on the Artificial Analysis Intelligence Index behind GLM-5 (Reasoning, 50). It is ahead of Kimi K2.5 (Reasoning, 47) and Qwen3.5 397B A17B (Reasoning, 45). On the overall leaderboard, it places #10, just behind GPT-5.2 Codex (xhigh, 49) and ahead of Grok 4.20 Beta (Reasoning, 48) ➤ Leading Elo of 1426 on GDPval-AA (Agentic Real-World Work Tasks), ahead of peer models: On GDPval-AA, MiMo-V2-Pro places ahead of GLM-5 (Reasoning, 1406), Kimi K2.5 (Reasoning, 1283), and Qwen3.5 397B A17B (Reasoning, 1209). GPT-5.4 (xhigh) and Claude Sonnet 4.6 (Adaptive Reasoning, max effort) have an Elo of 1667 and 1633 respectively ➤ Competitive AA-Omniscience Index driven by low hallucination: MiMo-V2-Pro scores +5, ahead of GLM-5 (Reasoning, +2), Kimi K2.5 (Reasoning, -8), and Qwen3.5 397B A17B (Reasoning, -30). For context, Claude Opus 4.6 (Adaptive Reasoning, max effort, +14) and Gemini 3.1 Pro Preview (+33) remain ahead ➤ MiMo-V2-Pro is more token efficient than peers. It used 77M output tokens to run the Artificial Analysis Intelligence Index, significantly less than GLM-5 (Reasoning, 109M) and Kimi K2.5 (Reasoning, 89M) ➤ MiMo-V2-Pro costs $348 to run the Artificial Analysis Intelligence Index at $1/$3 per 1M input/output tokens. This is less expensive than GLM-5 despite scoring only 1 point lower on the Intelligence Index. For comparison, GPT-5.2 (xhigh) cost $2,304 and Claude Opus 4.6 (Adaptive Reasoning, max effort) cost $2,486 Key model information: ➤ Context window: 1M tokens ➤ Pricing: $1/$3 per 1M input/output tokens, for 256K token input and $2/$6 per 1M input/output tokens for 1M token input ➤ Availability: Xiaomi first-party API only ➤ Modality: Text input and output only (no multimodality)








Anthropic just pulled the oldest trick in SaaS pricing. I pay $200/mo for Claude Max. My limits have been noticeably worse this past week. Now they announce 2x off-peak usage for two weeks. Sounds generous. But here’s what actually happens: limits quietly drop, a temporary 2x makes the reduced limit feel normal, the promo ends, and you’re left at a baseline lower than where you started. You just didn’t notice the downgrade because the 2x absorbed the transition. These AI plans are massively subsidized. The raw compute behind a heavy user costs multiples of the subscription price. Every move like this is the subsidy quietly correcting. Very sneaky, Anthropic.