Ryan Smith أُعيد تغريده

Open Source Models you have been sleeping on! x.com/i/broadcasts/1…
English
Ryan Smith
46 posts

@rnsmith49
Mechanistic Interpretability research, LLM Routing, and general GenAI optimization at https://t.co/eKknXT901I
Traditional Precision-Recall curves tell you how your code review tool performs on static benchmarks. They don't tell you how it performs against a Hawk. Introducing Fight Index (FI).

We've been tracking AI code review tools across OSS, and a new category is emerging. We're calling it "Deep Review": → Standard AI review: PR-level, fast, human in the loop → Deep Review: repo-wide context, runs autonomously in the background 🧵👇
We've been tracking AI code review tools across OSS, and a new category is emerging. We're calling it "Deep Review": → Standard AI review: PR-level, fast, human in the loop → Deep Review: repo-wide context, runs autonomously in the background 🧵👇

NeurIPS 😬

How good is Claude Code Review really, and is it worth $25+ per review? We scraped every OSS repo on GitHub that's using it to figure out how devs actually use it. Here's how it stacks up against 22 other tools: codereview.withmartian.com Featuring: @augmentcode @baz_scm @CodeAntAI @coderabbitai @cognition @cubic_dev_ @cursor_ai @GeminiApp @greptile @kilocode @kodustech @mesa_dot_dev @QodoAI

How good is Claude Code Review really, and is it worth $25+ per review? We scraped every OSS repo on GitHub that's using it to figure out how devs actually use it. Here's how it stacks up against 22 other tools: codereview.withmartian.com Featuring: @augmentcode @baz_scm @CodeAntAI @coderabbitai @cognition @cubic_dev_ @cursor_ai @GeminiApp @greptile @kilocode @kodustech @mesa_dot_dev @QodoAI
How good is Claude Code Review really, and is it worth $25+ per review? We scraped every OSS repo on GitHub that's using it to figure out how devs actually use it. Here's how it stacks up against 22 other tools: codereview.withmartian.com Featuring: @augmentcode @baz_scm @CodeAntAI @coderabbitai @cognition @cubic_dev_ @cursor_ai @GeminiApp @greptile @kilocode @kodustech @mesa_dot_dev @QodoAI


Introducing Code Review Bench v0: codereview.withmartian.com The first independent code review benchmark. 200,000+ PRs. Unbiased. Fully OSS. Updated daily. Tool performance highlights 🧵👇 Featuring: @augmentcode @baz_scm @claudeai @coderabbitai @cursor @GeminiApp @github @graphite @greptile @kilocode @OpenAIDevs @propelcode @QodoAI

LLM agents ignore their own environment — skipping outputs, misreading tools, repeating failures. Turns out the model knows when it’s wrong. 87% probe accuracy from activations. How we found it, fixed it, and how to try it with ARES + TransformerLens 🧵

LLM agents ignore their own environment — skipping outputs, misreading tools, repeating failures. Turns out the model knows when it’s wrong. 87% probe accuracy from activations. How we found it, fixed it, and how to try it with ARES + TransformerLens 🧵
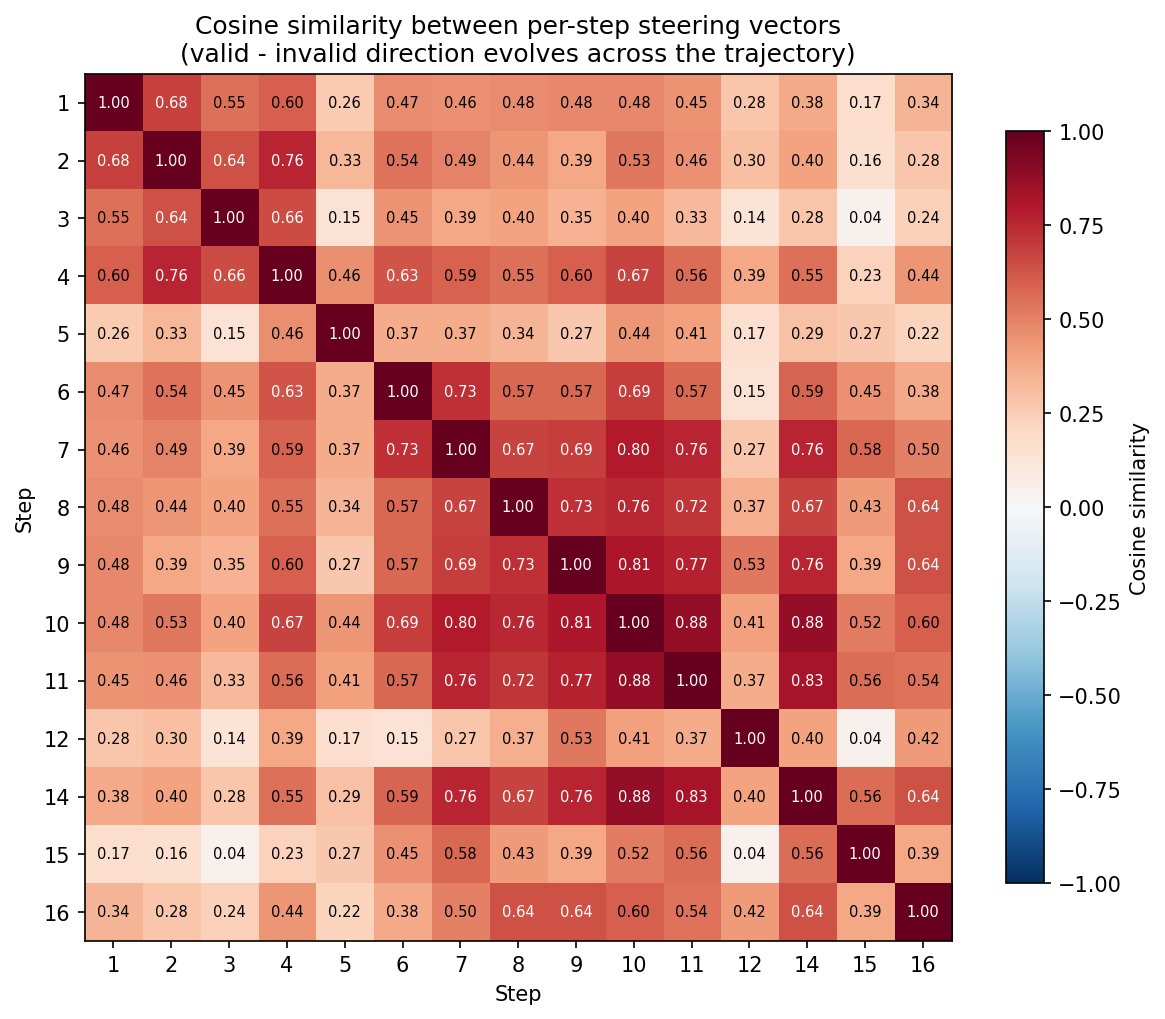
But you can't just compute one steering vector and reuse it for the whole episode. The representation of "valid vs. invalid" drifts as the conversation goes on;per-step vectors outperform a single static one. PCA on the vectors at different time steps shows they point in genuinely different directions.
LLM agents ignore their own environment — skipping outputs, misreading tools, repeating failures. Turns out the model knows when it’s wrong. 87% probe accuracy from activations. How we found it, fixed it, and how to try it with ARES + TransformerLens 🧵
SkyRL now implements the Tinker API. Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends. Blog: novasky-ai.notion.site/skyrl-tinker 🧵