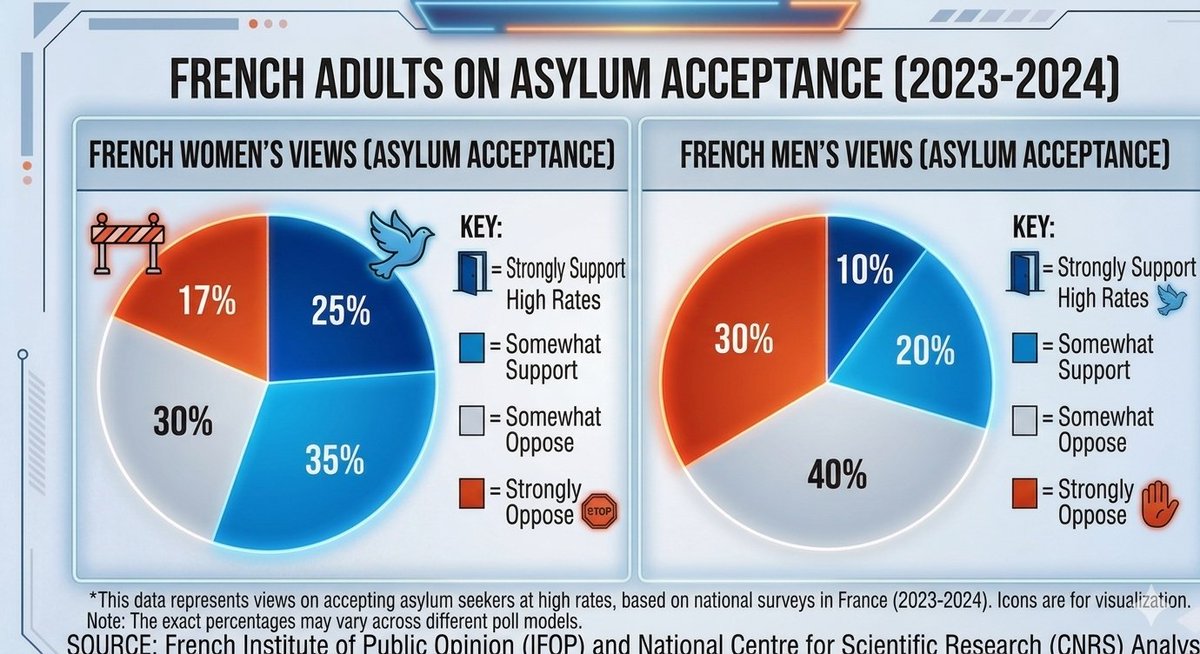
@MarekLecian @Similarweb No, moron, it means it loses market share. They now have only around 50% market share. 6 months ago they had 70%.
English
simple simple
409 posts



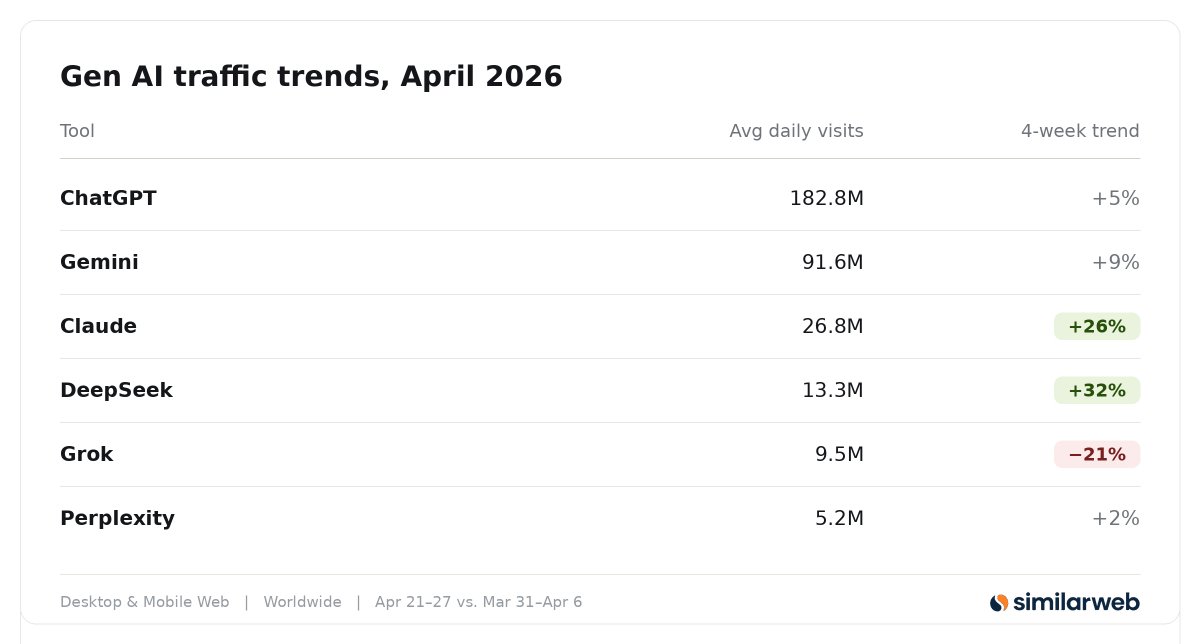


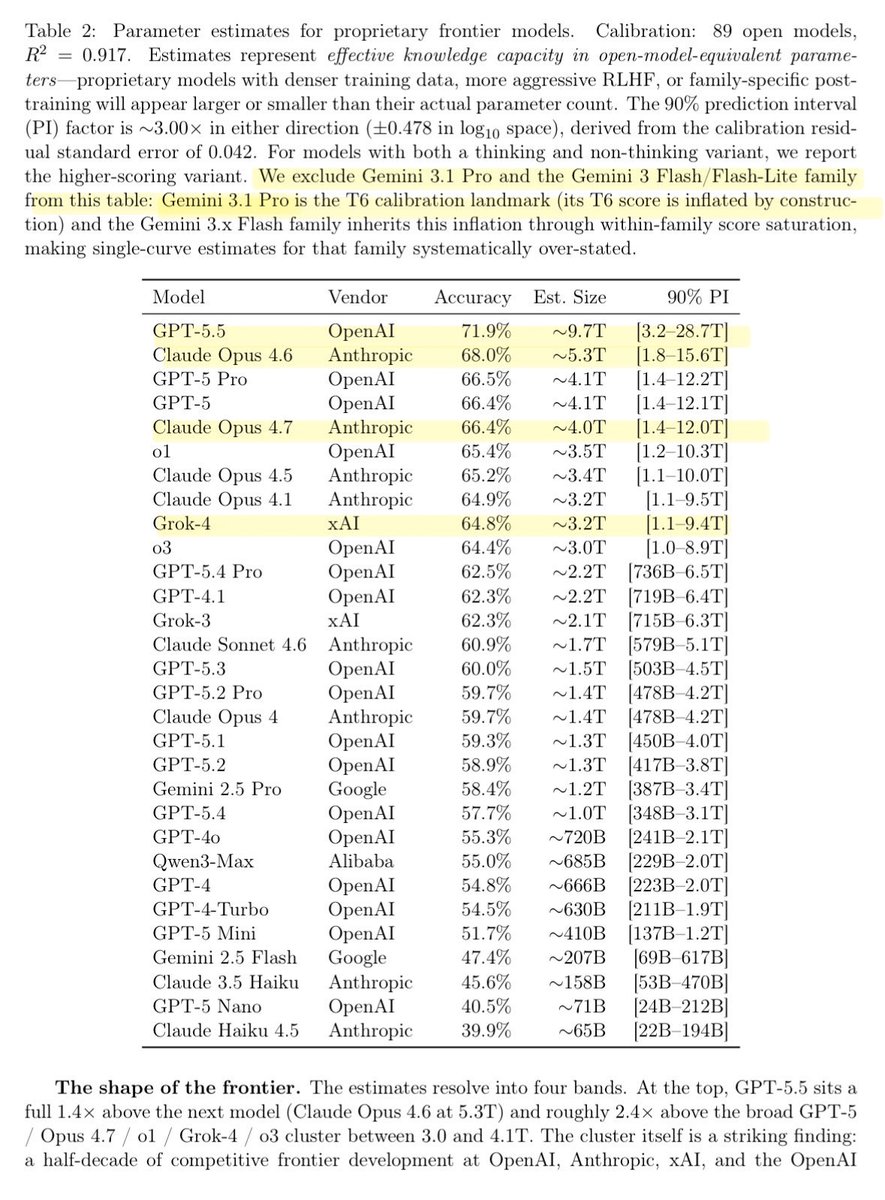

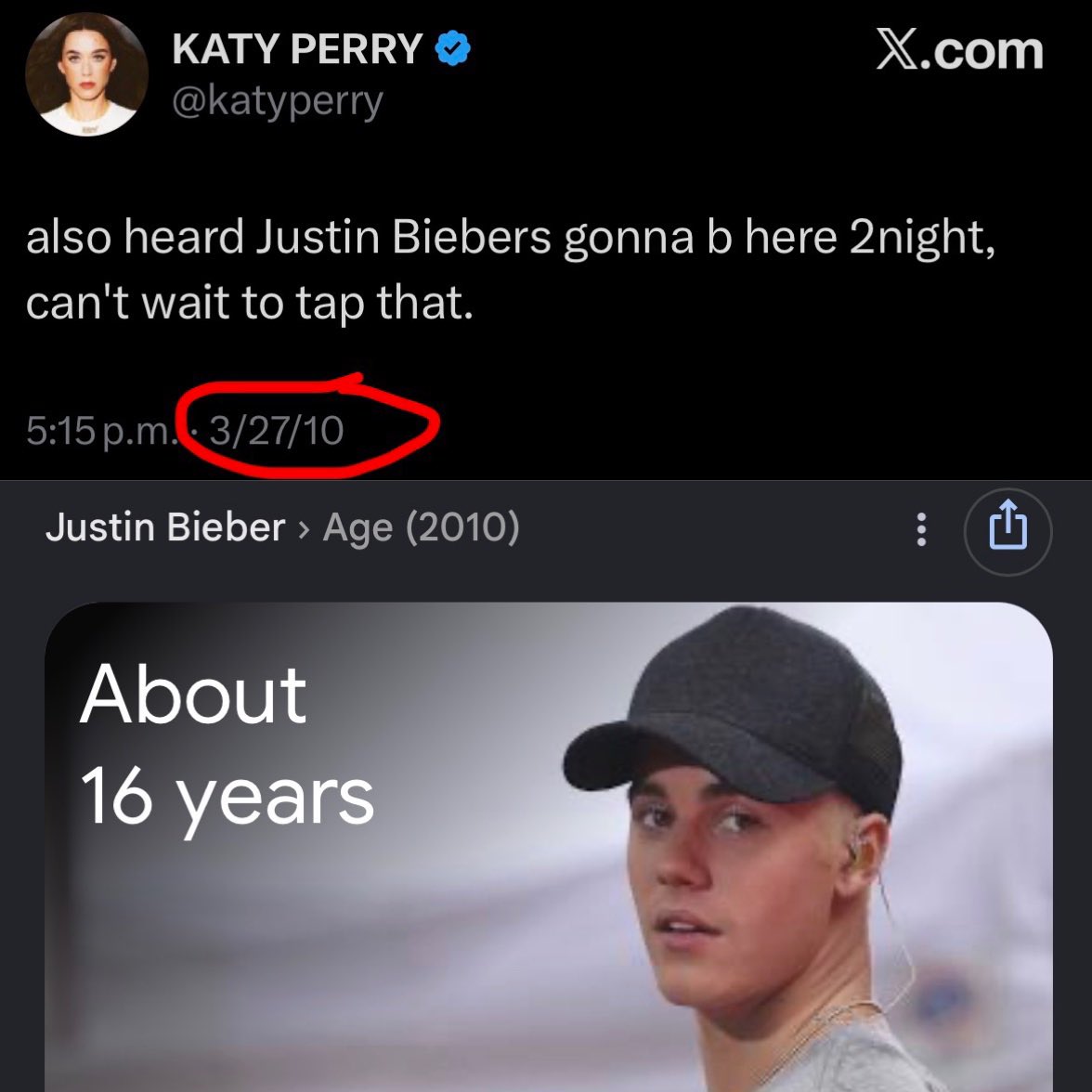






@bsilone @Orillacosmica no, we're going to disassemble The Sun too

A brand-new GPU cluster fails more often than a mature one. The first two weeks are the worst weeks the hardware will ever have. Meta's Llama 3 training paper is the number everyone cites: 419 unexpected interruptions over 54 days on 16,384 H100s, with GPUs and HBM3 memory causing the majority. That was the stable phase, after burn-in, acceptance testing, and the obvious lemons had already been culled. The follow-up reliability paper from Meta FAIR covers 150 million A100 GPU-hours and is clearer about what the ramp looks like: mean time to failure drops from roughly 47 hours at 8 GPUs to 7.9 hours at 1,024 to 1.8 hours at 16,384, and projects under 15 minutes at 131,072. Failure modes also ebb and flow as new health checks uncover new patterns. New health checks do not make a cluster healthier. They make its existing problems visible. The operational consequence: if your first customer workload lands during the first two weeks, you are running on the steepest part of the bathtub curve with the thinnest monitoring coverage. That is how a quarter of a cluster ends up cordoned before anyone understands why. What failure mode surprised your team most during a new cluster's first month, and how long did it take to attribute ?





Universal HIGH INCOME via checks issued by the Federal government is the best way to deal with unemployment caused by AI. AI/robotics will produce goods & services far in excess of the increase in the money supply, so there will not be inflation.


Jensen must have more money than he knows what to do with. Why is he doing this?