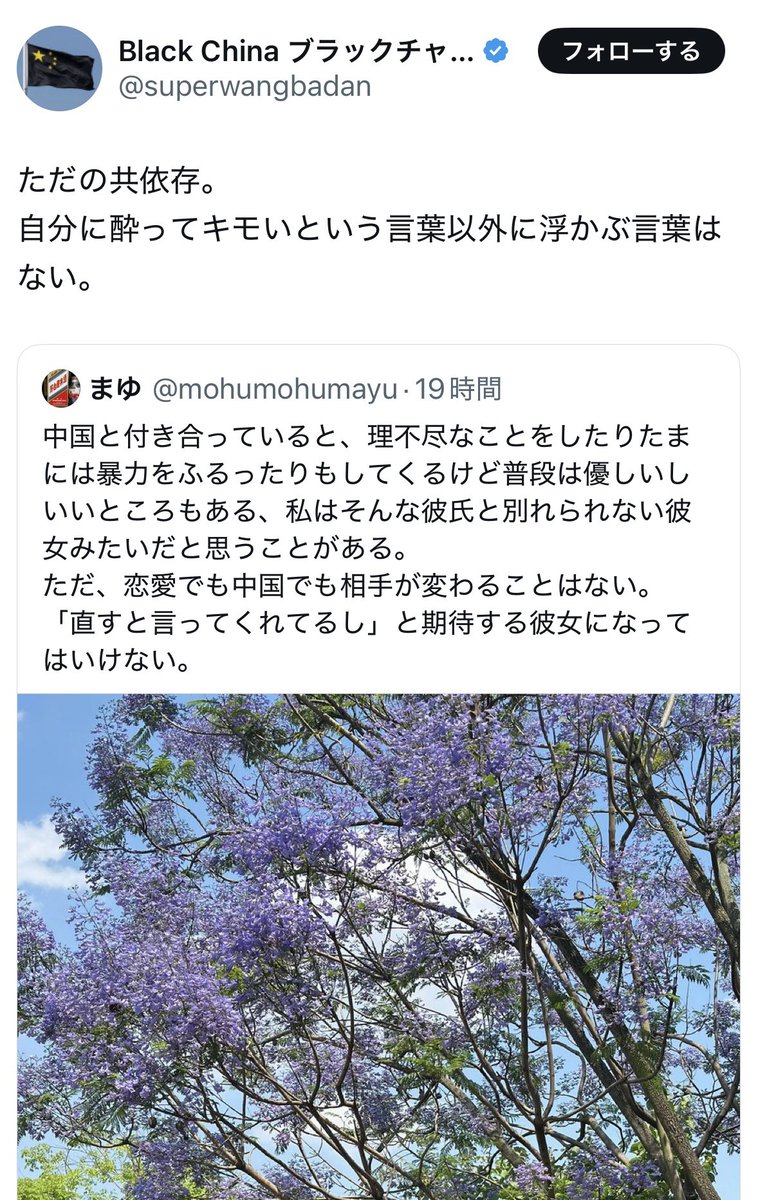
@mohumohumayu まゆさんの投稿を見るたびに、中国人の私にとっても新鮮な中国を見ることができます。本当にありがとうございます。私も中国の大学で数年間働いたことがあるので、まゆさんが中国の大学について書かれたことは、よく分かります。中国の大学は本当に働きづらい職場だと思います。小紅書では大学が緬北
日本語
backfire
646 posts




どうしよう。心が折れそう。 今月のお給料が入ったんだけど、2000元しか入らなかった。家賃支払い、ピザ手続き、どうしたらいいの? 去年から私も社会保険料が引かれるようになるとは聞いていて、でも毎月天引きだと聞いていた。それで言われた金額ぐらいが毎月引かれていたから、それだと思っていた。

Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo. Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm. trinkle23897.github.io/learning-beyon…

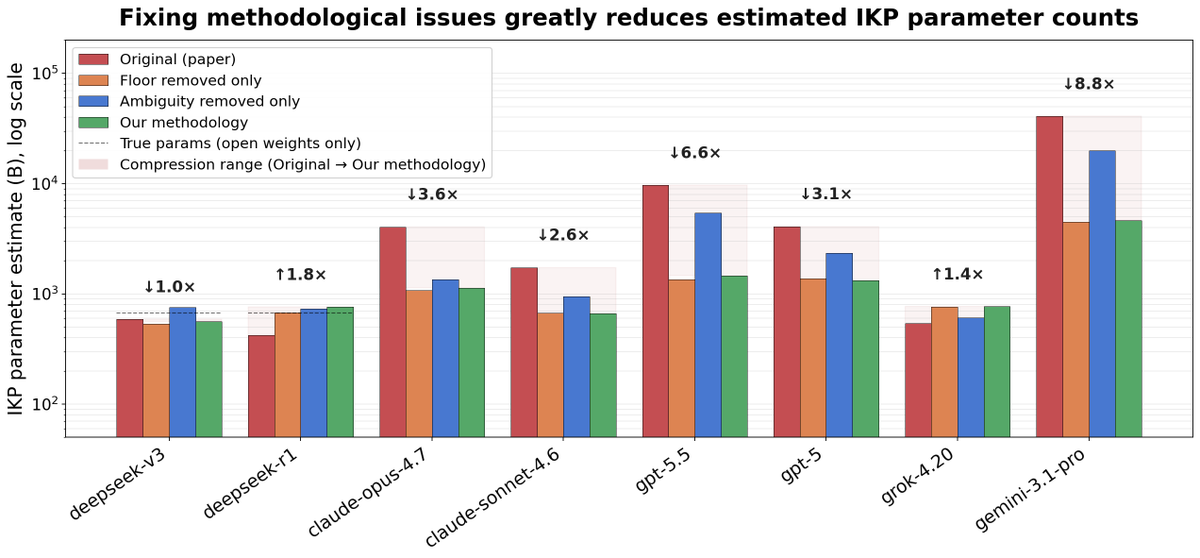
A recent viral paper claims to reverse-engineer the parameter counts of frontier models: GPT-5.5 = 9.7T, Opus 4.7 = 4.0T, o1 = 3.5T, etc. @ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).





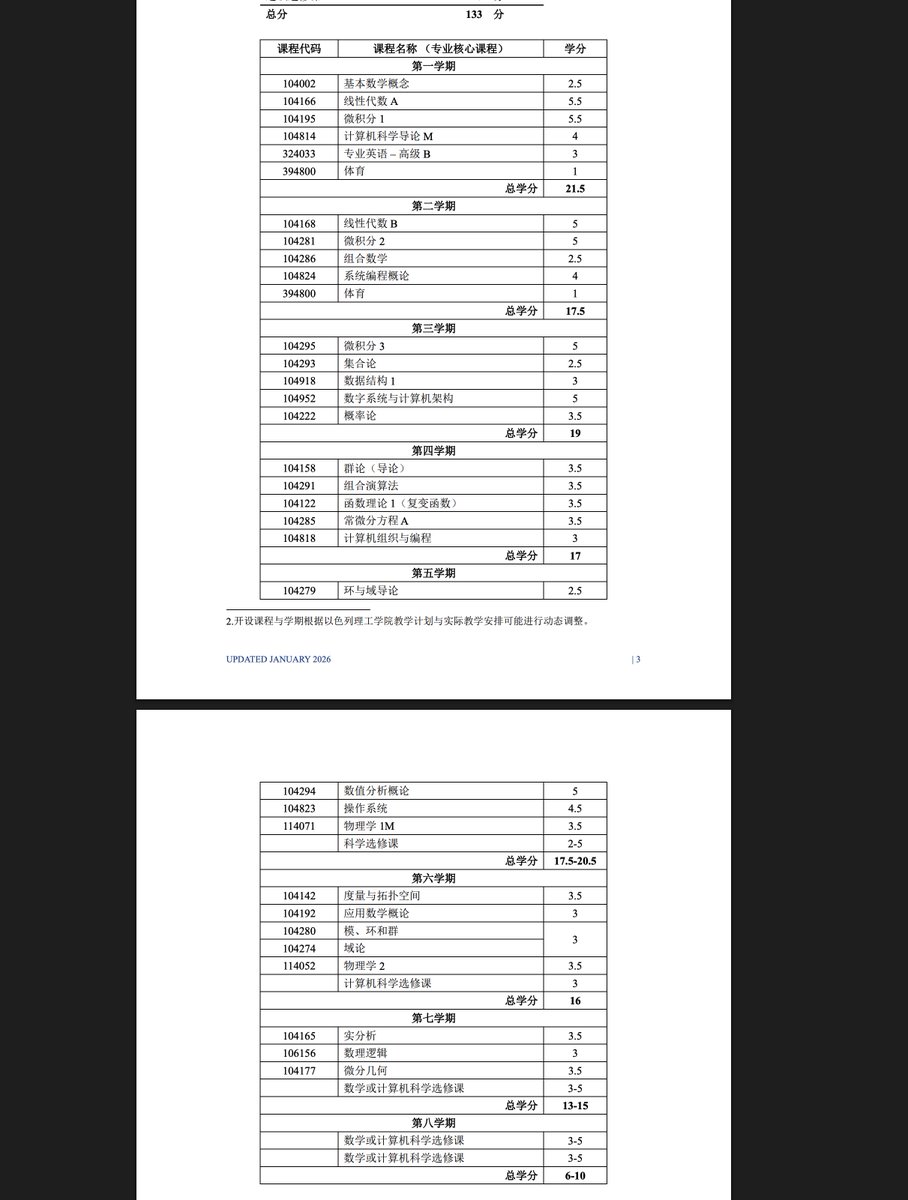
クビになりそうだ。 これまでうちの学科と国際課の意思だけで私の契約は更新することができていたけれど、今年度から書記と学長が変わり様々なことが改悪されてきた。その一環として、今回のことが起きた。 主任も同僚も全力で私の味方になってくれているが、ダメかもしれない。


GPT-5.5 by @OpenAI is now live in the Arena, landing across multiple leaderboards. Here’s how it ranks by modality: - Code Arena (agentic web dev): #9, a strong +50pt jump over GPT-5.4 - Document Arena (analysis & long-content reasoning): #6, on par with Sonnet 4.6 - Text Arena: #7, Math #3, Instruction Following: #8 - Expert Arena: #5 - Search Arena: #2 - Vision Arena: #5 Strong, well-rounded performance, especially in Code (+50 pts vs GPT-5.4). Congrats to @OpenAI on the release. Full category breakdowns by modality in the thread.