爆裂队长NEXT
509 posts


爆裂队长NEXT
@thinkszyg
15yr PM. Fired myself. Hired 10 AIs. Turns out managing AIs is harder than managing humans. AI Agents BLTeam 翻车笔记 & 鸿蒙一周大事持续更新。真实战,生产级真干货💰持续分享。少刷二手情绪,多看一手信号源。






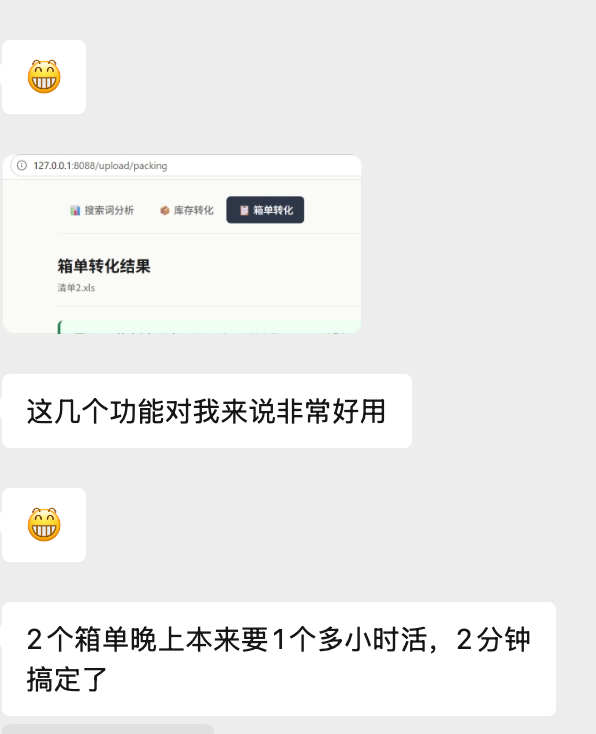
我靠!DeepSeek 已经快把市面上的 Agent 玩成全家桶了! 连 Reasonix 都安排上了。 说下:Reasonix 应该是目前市面上能帮你把 DeepSeek 账单省到极致、同时工具调用最稳定的原生终端了。 利用缓存命中直接把 API 账单干成骨折价! 传送门👉🏻:github.com/esengine/deeps…











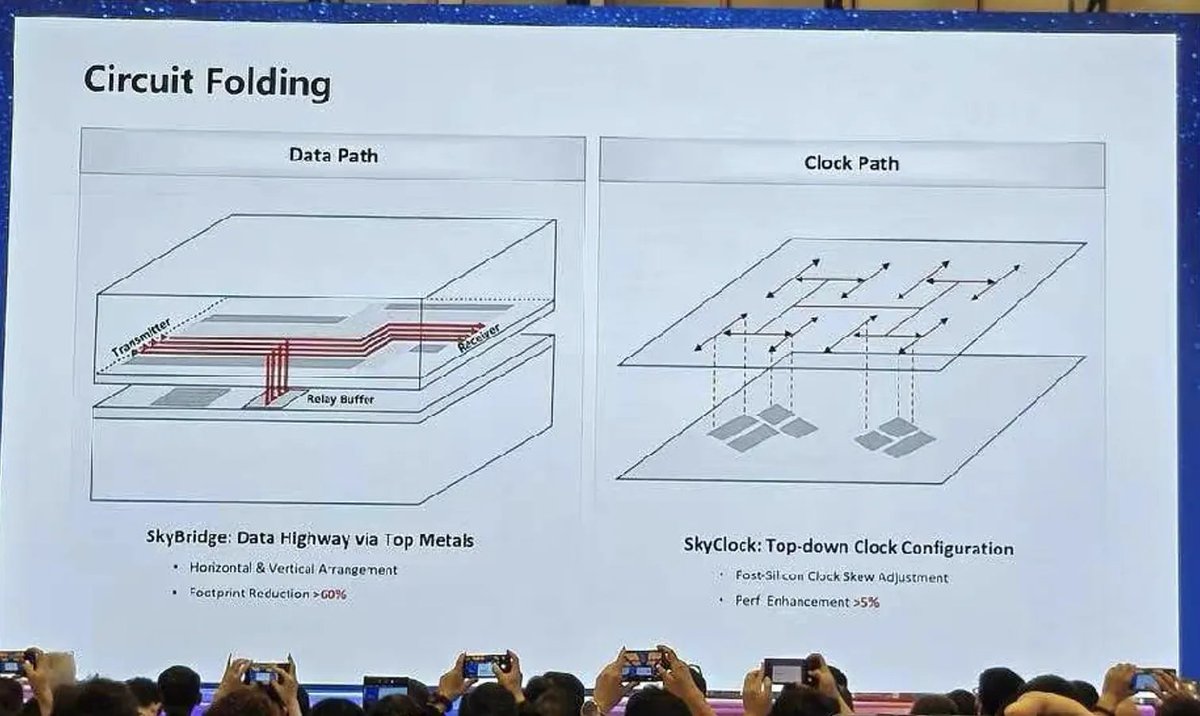
华为τ scaling定律营销策略,无非是more than moore的广义摩尔定律的另一种说法而已 作为芯片架构师,我更感兴趣的,还是芯片密度提升,ppt上41%能耗提升和12.7%性能提升,到底是怎么实现的 看完了论文,感觉华为这次创新,本质上是用设计复杂度高 + 高制造成本 + 超前散热,一定程度弥补了工艺差距 ----------------- 1. 华为芯片堆叠带来的等效密度提升,是虚假宣传还是真的,是不是工艺突破?有没有实打实的好处? 等效密度提升的来源,是两片芯片用hybrid bonding技术绑在一起,投影面积理论上能减小一半,但第一代不是全芯片双层折叠,而是选择性折叠关键logic,所以只有大概53%的芯片面积实现了折叠(密度155->238),等到后面几代折叠面积会逐渐增大,到2030年接近全折叠(密度155->292) 这2026第一代等效密度从 2025 年 155 MTr/mm² 跳到 2026 年 238 MTr/mm²,时钟频率也提升了12.7%,功耗比提升41%,表面上看似乎和工艺突破没有什么区别,但有一点重要区别就是leakage power华为从头到尾没有提,只要工艺节点不变,gate leakage、junction leakage 不会因为 3D stacking 自动改善 2030年到2031年的等效密度突变,大概率是来自于2层堆叠到3层堆叠,正如2025到2026年的等效密度突变,时钟频率突变,来自单层到2层折叠 所以从leakage没提这个事来看,这个2031年等效1.4nm,和工艺节点上的突破没有联系。 本质上是用设计复杂度高 + 高成本 + 超前散热 + 超前部署advanced packaging,一定程度弥补了工艺差距 ----------- 那么这样看起来虚假的等效密度提升,有用处吗?好处在哪里? 有的,设计上topology折叠,原来要跑几毫米的水平走线,折叠后变成了几十微米。降低了super buffer/bus的长度,降低了clock tree的深度(clock depth -42%、clock wire -28%),clock skew也带来了改良(-25%),这对动态功耗的改善是实实在在的。部分critical path的缩短,也让时钟频率的上升更容易 所以ppt roadmap上performance的提升,从2025年到2026年上升了12.7%,大部分都是来自于时钟频率的上升(12.7%) 所以好处基本上是topology拆分电路逻辑设计上带来的提升 既然没有实质上的工艺提升,华为芯片堆叠带来等效密度提升的trade off代价在哪里? 三个代价:散热超前发展,设计复杂度高,制造成本变高 最大的代价就是热密度的同步上升,理论上logic on logic都是CPU execution发热最严重的区域,这部分折叠起来相当于功耗密度直接翻倍,但算上41% power efficiency改善,功耗密度仍只比非堆叠方案高40%左右。所以第一代只能对最关键的部分做折叠,大概只占全芯片面积的53%。 所以散热技术也被逼的超前发展,直接上毫米级的MEMS风扇,做micro-cooling fan。 另外的代价就是设计复杂度的变高,critical path的折叠,哪个部分的logic能折叠,折叠之后又会带来从前端到后端的巨大变化要推翻重来 现有的所有EDA工具也不可能支持3D topology,论文自己也承认,full-scale LogicFolding需要全新的3D-native EDA toolchain,把多层stacked dies当作单一连续设计实体处理。哪些logic能折叠、折叠后的inter-die timing closure怎么做,Physical Design(PD)也是难点 制造成本也会更高,被迫超前部署advanced packaging封装,1.5~2um的hybrid bonding + logic on logic都是很有挑战需要显著更高的成本 以前一层wafer做一次光刻;现在两层wafer分别做光刻再bonding,加上hybrid bonding的overlay控制(论文要求<0.5μm)、TSV、KOZ keep-out zone、冗余修复、良率乘法损失,每颗芯片的制造成本和测试成本都要显著上升 -------------------------- 2. Tau scaling这个说法,scaling的到底是什么,这个scaling技术路线是不是一次性的design topology红利?潜力如何?持续进步的空间在哪里? τ Scaling的核心主张是:用时间常数τ替代几何线宽作为全栈优化目标,在器件、电路、芯片、系统四个层级分别压缩特征延迟 公式本身没有任何新物理。"关注瓶颈延迟"是所有架构师都在做的事情。整个行业都知道互联RC是延迟瓶颈,TSMC每一代工艺都在用low-k dielectrics/semi-damascene等手段降RC。把一个众所周知的优化方向包装成"定律"是显然的营销宣传手段,本质是More than Moore的广义摩尔定律的另一种说法 抛开marketing,华为目前所谓RC delay的改善,本质上是芯片堆叠之后,topology距离缩短,让匹配的effective RC都变小,不是RC工艺常数 至于scaling的意思,是能持续发展的一条roadmap。这里的持续改善路径指的是,全芯片堆叠的层数越来越多,从25~30年的2层堆叠,到31年开始的3层堆叠,以后甚至会考虑4层堆叠 第一代折叠技术甚至不是全芯片双层折叠,而是选择性折叠关键logic,所以只有大概53%的芯片面积实现了折叠(密度155->238),等到后面几代折叠面积会逐渐增大,到2030年接近全折叠(密度155->292)。2031年的roadmap之所以会出现一个阶跃,就是因为那是从2层折叠到3层折叠的时间点。 但需要注意的是,这个scaling方法的边际效应是逐渐缩小的,折叠成双层的收益是100%,2->3层的收益就只有50%,如果2035年再从3->4层堆叠,收益就只有33%了 另外随着堆叠层数变高,上面说到的三个挑战,散热,设计复杂度,成本,都是越来越大 --------------------- 3. 华为的芯片堆叠,是不是TSMC/AMD已经有的hybrid bonding技术?华为做到的是cache on logic,cache on cache,还是logic on logic,logic on logic最大的散热问题是怎么解决的? 是已经有的技术没错,但同时也是把现有技术指标做到了领先也是真的,3D堆叠本身不是新技术,TSMC的hybrid bonding量产还是6um,华为论文给出Kirin 2026的hybrid bonding pitch是1.5μm 我在刚刚看到华为的堆叠消息之后,第一反应也是怀疑和AMD的3D V cache类似,它主要把 SRAM cache 叠在 已经有的L3 cache 区域上,通常会避免直接堆在最热的 CPU execution logic 上,就是避免散热问题,毕竟SRAM 的功耗密度和热点特性与high-activity logic 不一样,如果最热的logic on logic堆叠,散热恐怕会碰到困难 但看了更多数据之后,clock buffer -56%、clock depth -42%、clock wire -28%,这些只有在core内部的clock distribution被重构时才可能发生。纯SRAM stacking不会碰core内部的clock tree。另外如果只是cache on cache,大概率是不需要单独MEMS微型风扇额外散热的,证据普遍都指向logic on logic方式 华为这个技术的精妙之处在于,logic on logic 折叠之后热密度并没有翻倍,而是因为topology的好处,能耗下降了30%,这样热密度只上升了40~50% 而第一代没有完全把整个最热的execution logic 100%堆叠起来,论文也明确说selectively applied along key critical paths,只是大概53%有选择性关键路径会堆叠起来,可能颗粒度都没有那么好,只是IP堆叠在IP上,那么热密度上升也许能维持在20%以内 但这条道路继续前行,超前发展的散热就成了必然,现在是MEMS微型毫米级的主动散热风扇,紧贴处理器传导效率高,和华为手机一样,散热堆料特别足,而且技术领先同行。 以后怕是要把HBM7/8的微流道散热技术提前用起来了,毕竟HBM7/8要上24+层堆叠,华为很可能要在提前用上下个世代的散热技术了 ------------------------- 4. 从架构角度来说,最重要的问题,华为41%的power efficiency(能耗比)提升,到底是怎么实现的?为什么AMD的3D V cache没有这么大的提升? 首先确定41%的定义。论文只说"SoC performance-core power efficiency improved by 41%",没有给出benchmark名称、Voltage/Freq点、温度条件、功耗边界。但PPT roadmap上有一个关键线索:ISO-Power Performance的数字,2025年是2.75,2026年是3.1,提升12.7% 这个时钟频率提升12.7%完全一致,可以理解为,同功耗的性能提升是12.7%,绝大部分是时钟频率提升带来的 至于能耗比上优化的猜测是,LogicFolding缩短critical path → 在固定Vdd下Fmax从2.75GHz提升到3.1GHz → 这意味着在原来的2.75GHz频率下,有了约12.7%的timing headroom → 这个空间在iso-performance模式下可以换成更低的Vdd 另外的能耗比的提升,可能也来自于电路折叠之后,cache hit latency的下降。从业界经验来看,一般L2/L3 cache hit latency下降10%,CPU整体性能会有至少5%的提升 ppt里显示SRAM latency下降30%,估计会有一部分转化为cache hit latency的下降 AMD的3D V cache没有这么大的提升,主要是因为AMD的底层logic die并没有重新设计,3D cache的延迟latency不仅没有减小反而加大,只是增加了cache大小,收益不如latency下降那么明显。 另一方面,clock skew的下降,critical路径变短,造成电路timing变好,意味着华为可以使用更低的vdd(猜测甚至能低7~8%),以及路径缩短所带来的RC的下降(考虑到clock buffer -56%、wire -28%、SRAM pJ/bit -24%这些数字,比如C_eff下降10~15%合理),再加上clock tree的整体缩短和下降,确实是有可能在部分Voltage/Freq点做到同性能下,做到30%的功耗下降的,而30%的功耗下降换算过来就是41%的power efficiency 对比苹果和高通,每一代手机芯片在iso-power下单核性能一般提升10-20%,iso-performance下功耗一般降30-40%,这是V/F曲线的特性决定的,所以从经验上来说,数字是对的上的。 所以这个power efficiency(能耗比)的提升,从现有的数字上来说可以从topology推导出来是合理的,可能真的和工艺节点没有太大关系 ---------------------------- 5. 这个技术路线有没有可复制性,其他家会不会效仿? 短期内不会大规模效仿,因为性价比和风险收益比来说不好。长期来看,这个方向所有人都在走,只是名字不一样 华为做LogicFolding的根本驱动力是制裁,工艺节点被卡在7nm,只能在封装,散热,和设计层面想办法弥补。华为也为此付出了不小的代价:散热成本,设计复杂度,以及制造成本更高(包括良率)。这是一个被逼出来的路线,不是一个自然选择 其他玩家在用TSMC就能做到正常的经济迭代,是没有必要冒着这个风险,去超前迭代散热技术和设计复杂度的 长期来看,Intel的Foveros、TSMC的SoIC、AMD的MI300的3D stacking都在朝同一个方向走。如果继续追最先进节点的经济性持续恶化,那么"固定一个成熟节点+3D topology optimization"的路线会越来越有吸引力 散热方面,MEMS微型风扇和微流道也会成为未来HBM散热的主流 ------------------- 总结一下,华为这次的创新,绝对是值得尊重的,在制裁环境下,用极高的设计复杂度和成本,在一个被锁定的工艺节点上大胆重新设计,榨出了一次大的topology红利,虽然它有天花板。每多加一层的边际收益递减(堆叠1->2层, 2->3层, 3->4层,提升百分比变小),leakage无法解决,散热越来越难,3D EDA工具链更是全新的挑战。 但这个Tau scaling不是一条可以走十年的指数增长路径,每次爬完一个台阶,下一个台阶更难爬,而且台阶更矮收益更小,华为以后想缩小差距,还得再想想靠什么其他的路线


most protocols treat u like farmers we treat u like an evolving node neosoul x @0g_labs credentials just dropped 50k total supply but epoch 1 only gets a fraction 20k orbit spots for the early ones 4k vector spots if u actually do shit 140 zenith upgrades for the absolute brains mint opens tmrw 10am utc tell us ur boldest market prediction to get on the radar
