تغريدة مثبتة

Introducing cc-canary: a skill and open-source CLI tool that detects early signs of regressions in Claude Code by analyzing your local session logs.

English
Tejpal Singh
1K posts

@tsv650
building coding agents @ https://t.co/ZJUjbhMXlB


President Xi of China, and I, are working together to give massive Chinese phone company, ZTE, a way to get back into business, fast. Too many jobs in China lost. Commerce Department has been instructed to get it done!
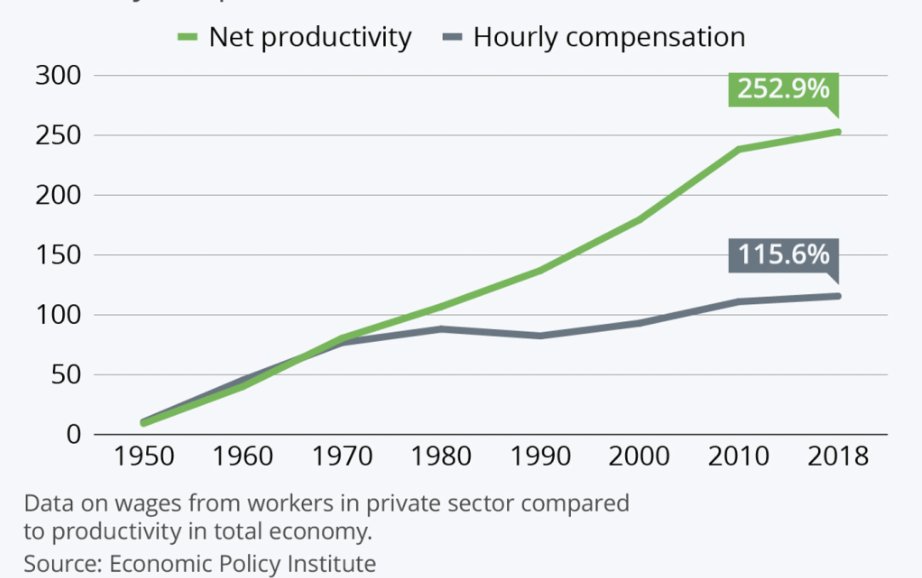
The highest-value human work in the AI era will be in domains with sparse reward signals. Internalize this, or watch your value erode over the next decade. Math, programming, rote memorization, data science, all fucked. The classic “smart nerd” jobs are exactly where AI is strongest, because the feedback loops are dense. You can check the answer. You can run the test. That means AI can improve quickly, and humans will rapidly fall behind. Your advantage as a human is in messy domains. Taste. Judgment. Negotiation. Risk-taking. Politics. Sales. Science at the frontier. Anything you can only really learn by doing. Cross-disciplinary stuff. The valuable domains will be the ones guarded by secrets, tacit knowledge, weak labels, long feedback cycles, and ambiguous outcomes. Places where the training data is scarce, the ground truth is disputed, and it's impossible to explain why something is good. AI will still enter these domains. But we will be slower to trust it unsupervised there, because it will be harder to tell when it is right, harder to prove when it is wrong, and difficult to construct secure sandboxes. The stakes will be too high to YOLO it. I find myself saying this over and over again to young people today: the future does not belong to people who are able to get good grades on tests. It belongs to people who can operate under uncertainty, in domains where correctness is hard to define. Those domains will become the thin waist of the economy: as productivity everywhere else accelerates, the humans who excel there will become our economic Strait of Hormuz. The best humans in these domains will demand an enormous cut of the growing economic pie. Your imperative going forward is to make sure you're one of these people. (Or become an electrician. That probably works too.)

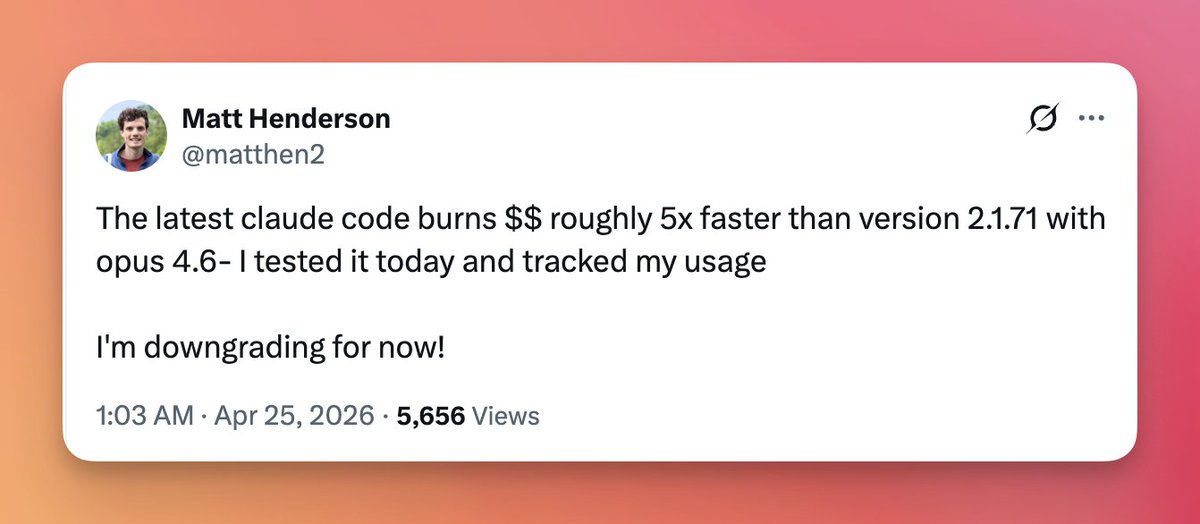
The latest claude code burns $$ roughly 5x faster than version 2.1.71 with opus 4.6- I tested it today and tracked my usage I'm downgrading for now!
Anthropic's Opus 4.7 shipped with a new tokenizer, which makes it up to 50% more expensive for some users. I built a skill (/cc-markup) that estimates the price hike, backtested on your past sessions👇

Anthropic's Opus 4.7 shipped with a new tokenizer, which makes it up to 50% more expensive for some users. I built a skill (/cc-markup) that estimates the price hike, backtested on your past sessions👇
Introducing cc-canary: a skill and open-source CLI tool that detects early signs of regressions in Claude Code by analyzing your local session logs.

Over the past month, some of you reported Claude Code's quality had slipped. We investigated, and published a post-mortem on the three issues we found. All are fixed in v2.1.116+ and we’ve reset usage limits for all subscribers.
Introducing cc-canary: a skill and open-source CLI tool that detects early signs of regressions in Claude Code by analyzing your local session logs.


Over the past month, some of you reported Claude Code's quality had slipped. We investigated, and published a post-mortem on the three issues we found. All are fixed in v2.1.116+ and we’ve reset usage limits for all subscribers.
Introducing cc-canary: a skill and open-source CLI tool that detects early signs of regressions in Claude Code by analyzing your local session logs.

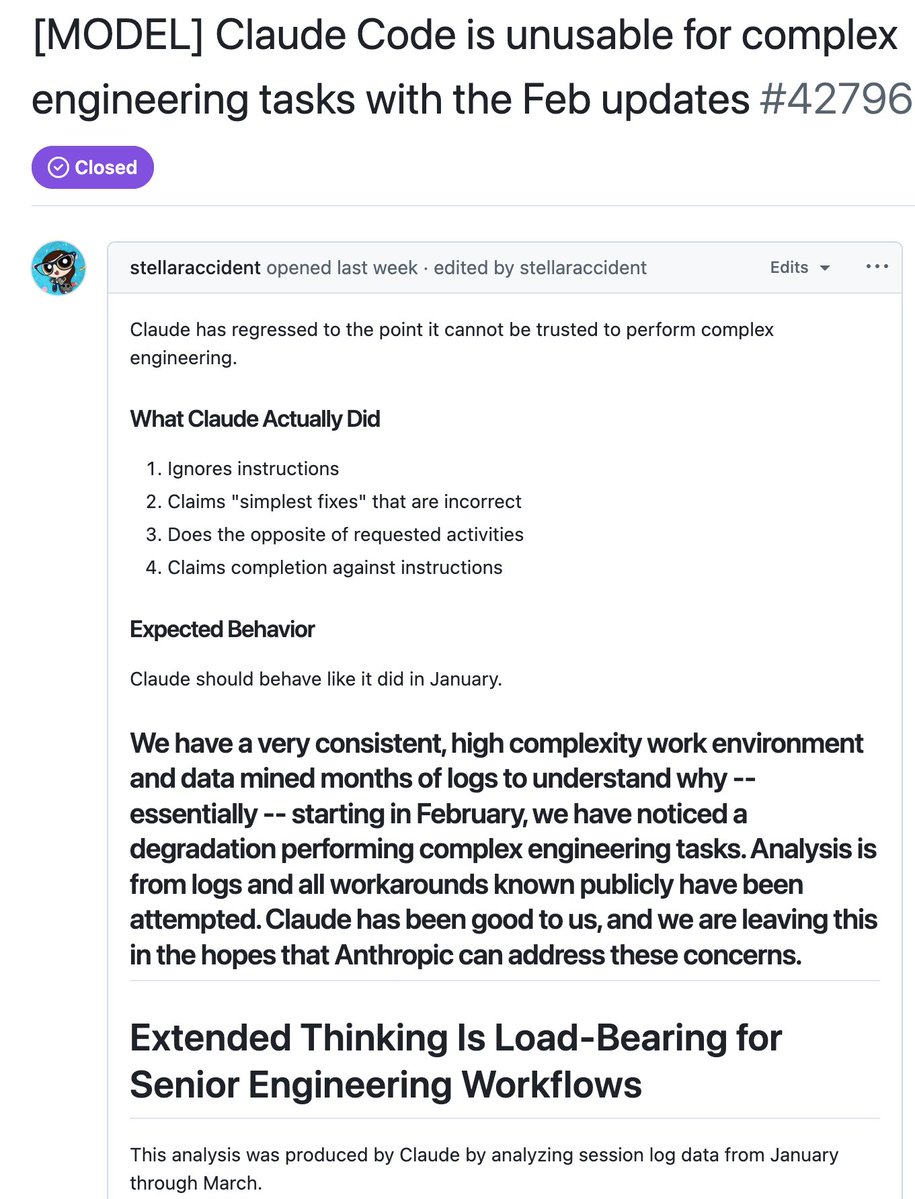
Introducing cc-canary: a skill and open-source CLI tool that detects early signs of regressions in Claude Code by analyzing your local session logs.

Over the past month, some of you reported Claude Code's quality had slipped. We investigated, and published a post-mortem on the three issues we found. All are fixed in v2.1.116+ and we’ve reset usage limits for all subscribers.



