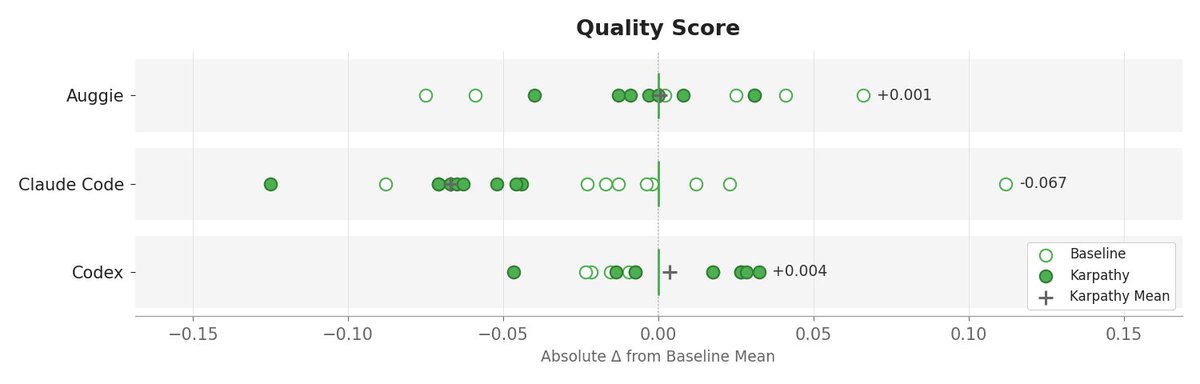
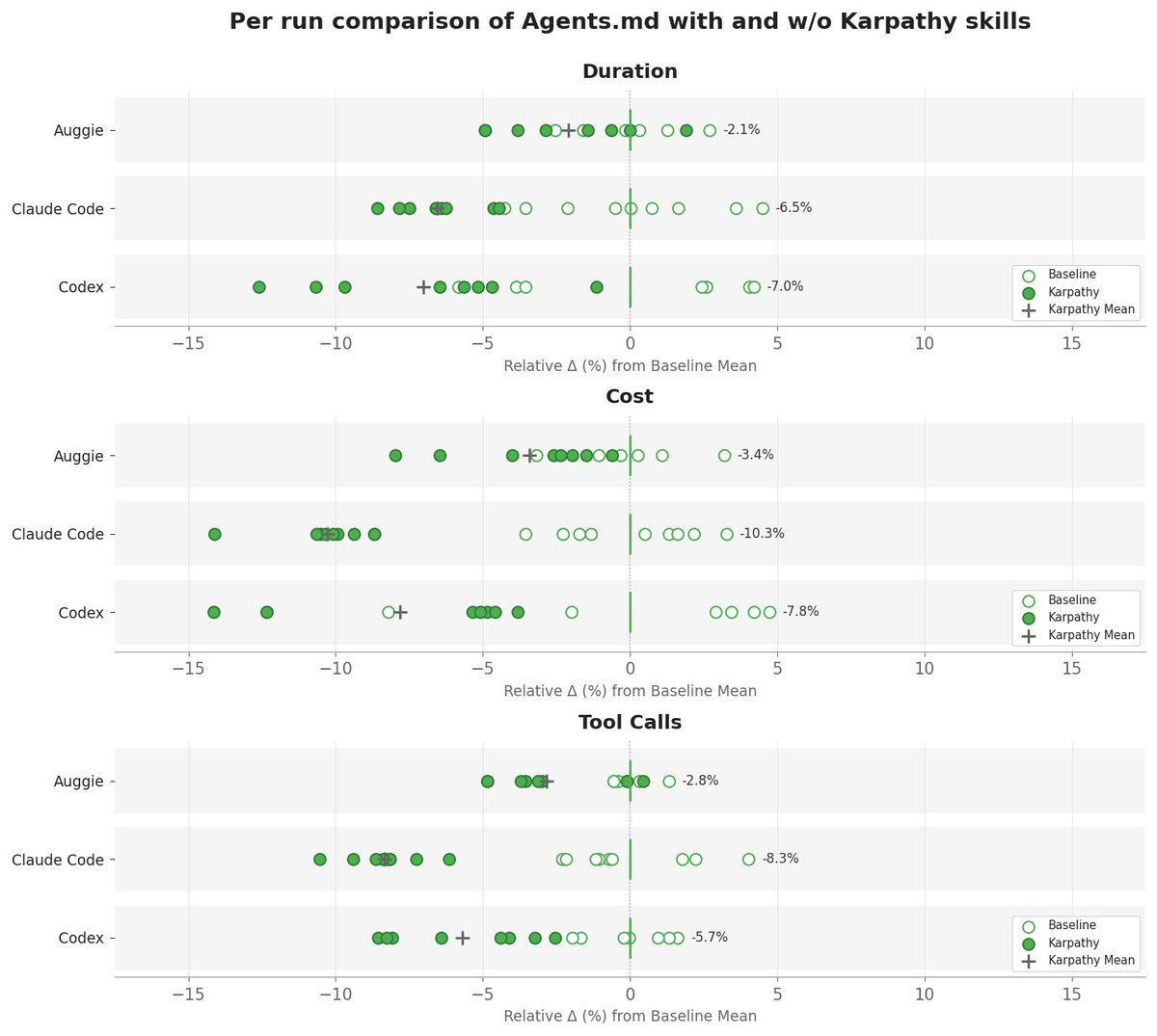
We added @karpathy -inspired coding rules from @jiayuan_jy to AGENTS.md and ran 40 @openclaw PRs through three coding agents.
The result:
Code quality was basically unchanged, but the agents got there with less work. Fewer tool calls, lower time and cost.
English