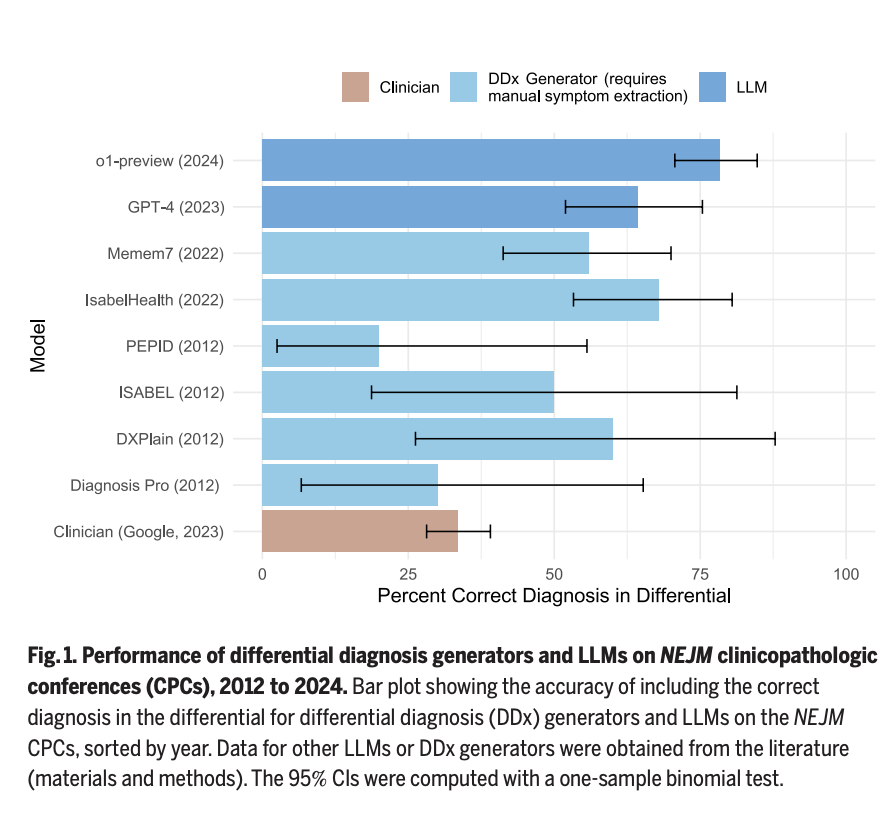
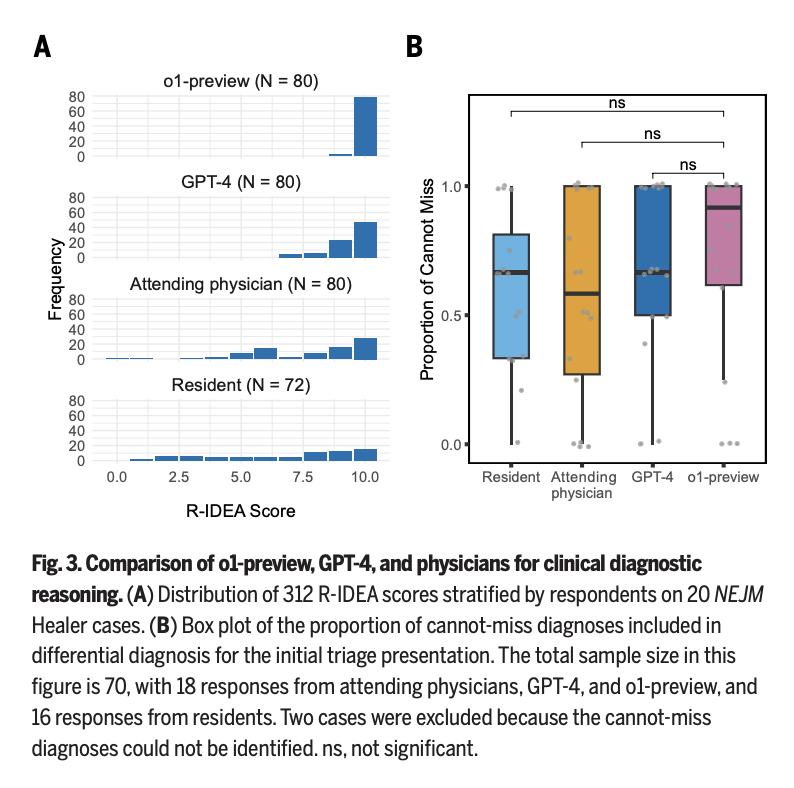
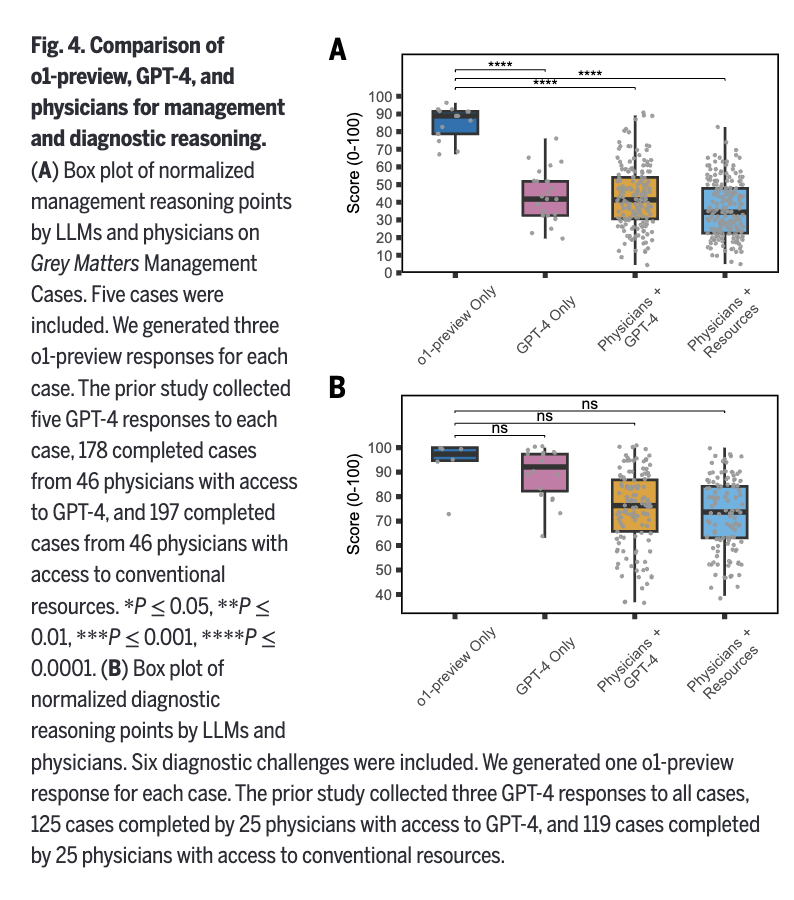
🧵1/ Our new study on AI and physician reasoning just came out in @ScienceMagazine. As co-senior author, I'm excited about our findings, and I do think AI will reshape medicine. But after seeing some of the discussions, I'm also worried about how our findings may be misinterpreted.

English