@DrDiGiorgio @EvidenceOpen This sort of AI is built into Epic at our institution now. It makes hospital courses, daily insights, chart reviews, give specific citations in the chart and links them to specific notes.
English
Austin Meyer
3K posts

@austingmeyer
w/ @b_ritt23 • MD/PhD/MS/MPH/MS • data scientist • virus modeler • IM/Peds Hospitalist @bswhealth • Assistant Prof @bcmhouston • I 💛 infections, jazz, data, ☕️

Until now, physicians using AI in clinic had to assemble the patient’s context themselves. Allergies, comorbidities, medications, prior procedures, copy-pasted in from the chart. Today we’re announcing a partnership with @CedarsSinai. OpenEvidence now works directly inside Epic, drawing on the patient’s full record and interpreting the medical literature through the lens of that specific patient. Cedars-Sinai is the first academic health system to deploy patient-aware clinical intelligence at enterprise scale. The clinician asks a complex question in natural language. The answer reflects both the best available evidence and the patient in front of them. Patient data is never stored after the clinical session or used for any other purpose.








Senator @BernieSanders has invited me and three other AI researchers to a public panel on AI existential risk & international cooperation at the U.S. Capitol 7pm Wednesday April 29th. RSVP here to join us for this important conversation: forms.office.com/Pages/Response…


@BradSpellberg @WikiGuidelines @DrToddLee @AnilMakam @medrants 💥Update: Our LTE has prompted a response from IDSA. "Rethinking How We Provide Guidance When Evidence is Limited" Looking forward to where this discussion goes next #IDXposts academic.oup.com/cid/advance-ar…


Across most medical benchmarks, including when real cases & human doctors are involved, there is a clear trend of AI models improving over time (and many where today's AI beats human doctors) But we do not have many studies measuring real-world performance of AI in medicine, yet


I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools. With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments. Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know. I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars. (One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.) There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!
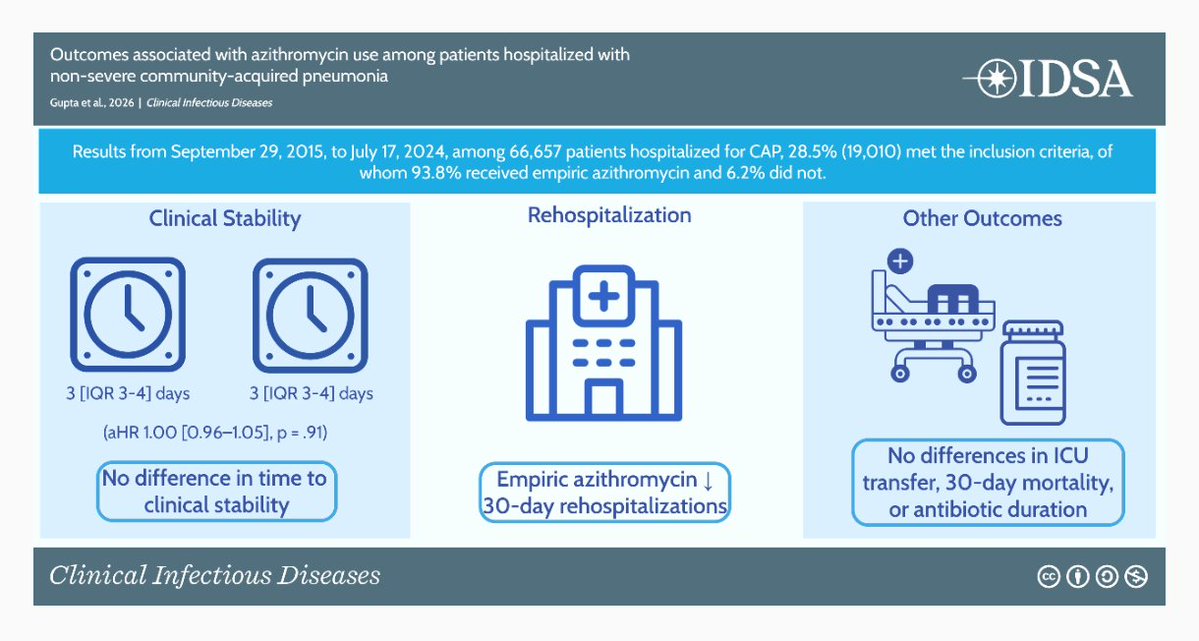
@BradSpellberg @ABsteward @DrToddLee Has there ever been a randomized placebo controlled (with no antibiotic in the control group) trial for outpatient pneumonia treatment in a developed country?