@KuittinenPetri@somet3chth1ng@sudoingX Did you compare it to GPT-OSS 120B uncensored? This is running pretty fast for its size. Qwen 3.5-27B unfortunately seems pretty slow, even though the quality is great.
@666Sebo@somet3chth1ng@sudoingX Qwen3.5-27B is better or as good as OSS model up to ~120B size at the moment. Then Qwen3.5-35B-A3B and obviously Qwen3.5-9B is the weakest, but it already has good uncensored variants, so you can chat with it about anything and it will give detailed descriptions of any image.
local AI hardware tiers:
$4,699 - DGX Spark (NVIDIA wants you here)
$1,989 - RTX 4090 (overkill for most)
$1000 - RTX 3090 used (sweet spot)
$250 - RTX 3060 used (currently testing every model that fits 12GB)
$0 - CPU only (it still works)
jensen announced the top. i've been posting receipts from the bottom.
@KuittinenPetri@somet3chth1ng@sudoingX How would you rate the quality between 35B, 27B and 9B? Are the dense models that much better in comparison to 35B that they justify the slow performance?
@somet3chth1ng@sudoingX My go-to-models with AMD Ryzen™ AI Max+ 395:
Qwen3.5-35B-A3B ~72 token/s
Qwen3.5-27B ~13 token/s
Qwen-coder-next 80B-A3B ~60 token/s
Qwen3.5-9B ~30 token/s
Nemotron-3-Nano-30B-A3B ~60 token/s
Q4_K_M quant. The good things is there is enough RAM to run full context window.
INCREDIBLE SPEED
running Claude Code w/ local models
on my own GPUs at home
> SGLang serving MiniMax-M2.1
> on 8x RTX 3090s
> nvtop showing live GPU load
> Claude Code generating code + docs
> end-2-end on my AI cluster
MiniMax-M2.1 is my favorite model
to run locally nowadays
@KuittinenPetri I've seen a video where they allocated only 512 mb to the GPU in bios because of the unified memory the system can allocate the RAM according to need. On Linux that should be even possible up to 110 GB of "vram"
AI performance Beelink GTR9 Pro AMD Ryzen™ AI Max+ 395 with LM studio and latest stable llama.cpp:
Qwen3-VL-30B-A3B 62 token/s
Nemotron-3-Nano-30B-A3B 60 token/s
Qwen3-Coder-30B 52 tokens/s
Nous-Hermes-4-14B-ablirated 22 token/s
devstral-small-2-2512 (24B) 13 token/s
darkidol-llama-3.1-8b-instruct-1.2-uncensored 42 tokens/s
The memory seems to be the bottle neck, giving about 140 GB/s read and 100 GB/s write.
I didn't see any noticeable differences between llama.cpp Rocm and Vulkan performance.
I didn't test larger dense models. 72B dense model will likely only give about 5 tokens/s. I will test ZAI GLM-4.5-Air later. I would expect about 25 token/s.
I used 64 GB (main) + 64 GB (video memory) configuration, but 32+96 and 96+32 are also possible. I used Q4_K_M quantization, which is generally the best balance between speed and accuracy. Context window was 16k or more, depending on model.
3/🧵
The best value for money AI computer is: Beelink GTR9 Pro AMD Ryzen™ AI Max+ 395. Price $2399. It comes with 128 GB LPDDR5 8000 MHz. You can run fairly large models even with 60 token/s. In this thread I will share my experiences with it + some benchmarks.
1/megathread🧵
@KuittinenPetri Nice review. Did you experience any problems with the Ethernet? I've read a few have problems with it, basically losing connection or just shutting down.
Beelink GTR9 Pro AMD Ryzen™ AI Max+ 395
Pros:
- silent at idle, under 28 dB
- remains cool and under 35 dB even under heavy load & gaming
- inbuilt 4 mic array + speaker is okay for video conferencing
- free AMD chat can make images locally (with Stable Diffusion), but I ended up deleting this app, as I will later probably install ComfyUI
Cons:
- I had to reinstall Windows 11, as some updates didn't get through
- hardware seems well built, but driver support seems still flaky and Windows event log shows some errors
I will post more later. Feel free to ask anything about this small mini PC.
PS. This is not paid endorsement. I paid it 100% myself.
5/🧵
@gavinlucas110@shaunrein Brand recognition and attached status is definetly a strong selling point. But over time even that will evaporate if the product and quality is inferior. Especially in markets where pride of local products rises.
What's everyone's tips for China?
Where to go?
I think I'll fly in from Kyoto to Shanghai?
Then high speed train everywhere?
I like Sichuan hotpot and was also thinking Chengdu (many people say it's great), Shenzhen of course
@levelsio Beijing was relative boring as a city. You could do all the tourist attractions like forbidden city, tiananmen square and the great wall in two days.
Chongqing was great and something completely different but even there after two days you've seen the most.
@levelsio Shanghai is awesome. Been there for six days and could easily stay longer. The further away you're from the typical tourist areas the better.
i've partnered with the absolute GOAT when it comes to n8n automations...
we've put together the only course you'll ever need:
- 13 modules to go from beginner to expert in 30 days
- +20 JSON automations for marketing ready to import
- +30 prompts to use in your workflows
i've no idea why we're giving this away for FREE but f*ck it
reply "VIBE" + follow @VibeMarketer_ and i'll send you the Notion (must follow both so i can dm)
Claude just made every $10K n8n consultant obsolete.
I fed it 1,000 broken workflows from "experts" charging fortune 500 companies.
It fixed them all in 37 minutes.
Then showed me why they were garbage to begin with.
Here's what these "automation experts" don't want you to know:
Their $10K workflows:
- 147 unnecessary nodes
- Zero error handling
- Break when someone sneezes
- Take 3 weeks to deliver
- Require monthly "maintenance" fees
Claude's rebuilt versions:
- 12 nodes maximum
- Self-healing error handling
- Run for months untouched
- Built in 10 minutes
Cost: $0 (plus my prompt)
I tested this on 5 client projects.
Claude outperformed every consultant.
The "experts" are panicking because anyone with ChatGPT can now:
- Diagnose workflow problems instantly
- Rebuild complex automations from screenshots
- Add features consultants claim are "impossible"
- Fix their overpriced mistakes
One consultant tried to charge me $3K to add email notifications.
Claude did it in 47 seconds.
The automation consulting industry is built on artificial complexity.
They're not smarter than you.
They just speak in acronyms.
Want the exact prompts that turn Claude into a $100K/year automation consultant?
Like + Comment "CONSULTANT" & I'll send you:
✓ The workflow diagnostic prompts
✓ My n8n rebuilding templates
✓ Error handling blueprints
✓ Client pricing calculator
Your competition is still paying consultants.
Time to eat their lunch.
Leaking every n8n agent I’ve shared on X
20+ production‑ready flows + a 1,500‑template repo - free to clone
TikTok VEO
- my most popular n8n builds (WhatsApp agent, scraper agent, tiktok veo 3 automation, n8n assistant, and more)
- 1,500‑flow n8n template index (tagged by growth, ops, creative) so you never start from scratch
- full vibe‑coding tutorial where I go from basic n8n backend to Bolt front‑end UI in 23 min
basically everything you need to crush AI automation + vibe coding in one folder.
FOLLOW + RETWEET + REPLY “YES” and I’ll send it over.
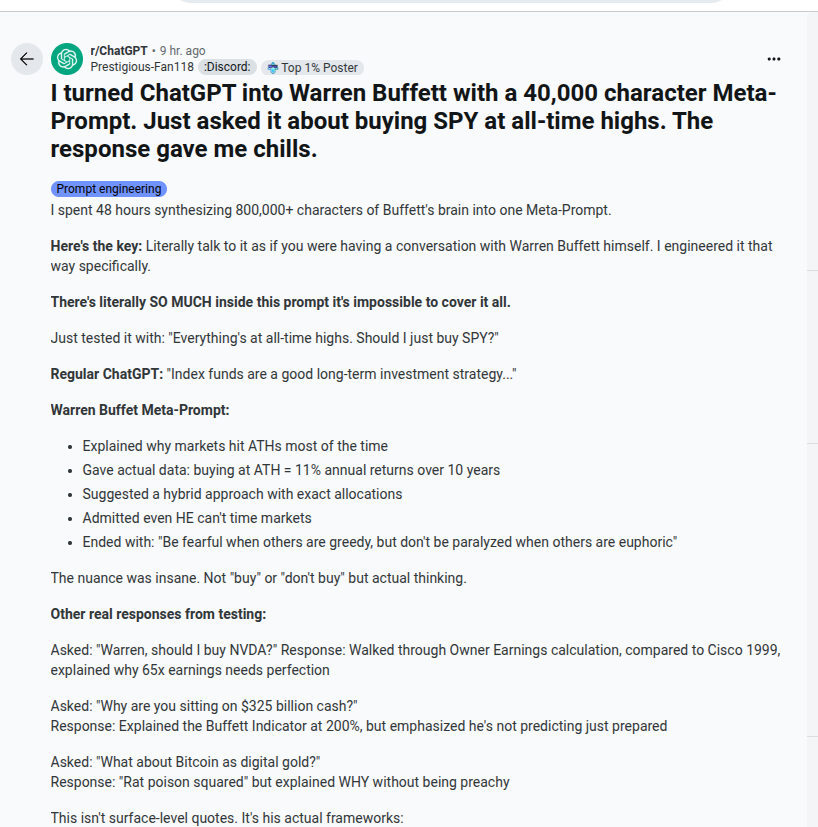
This guy is using this huge 40,000 character Meta-Prompt to turne ChatGPT into Warren Buffett.
The prompt locks the model into acting as Warren Buffett by loading 40,000+ characters of his biography, routines, quotes, formulas, and case studies.
It injects complete valuation frameworks, decision trees, and linguistic patterns so answers echo Buffett’s style and logic.
i.e. from Prompt-engineering perspective, it's heavy persona priming, domain knowledge stuffing, strict output policing, and explicit step-by-step checklists that channel the model’s reasoning.
---
reddit .com/r/ChatGPT/comments/1m5ha9j/i_turned_chatgpt_into_warren_buffett_with_a_40000/