
Click
26 posts

Click
@Click526054
Co-Founder @GlydeGG | BTC since 17’ | Angel Investor | trading group: https://t.co/UdrhtRk8uh | Dubai 🇦🇪
Beigetreten Nisan 2026
1 Folgt0 Follower

The goal is simple but powerful, remove uncertainty, reduce debugging time, and elevate every line you write so that what you build is not only functional but professional, robust, and ready for real world deployment
Minimals@0xminimals
"No bugs found." But the app takes 8 seconds to load. That IS a bug. Slow = broken. Find the lag. Fix the code. Ship faster apps.
English
@ainephamm Nhớ hồi trước chỉ rong chơi với boss, giờ toàn nghe thấy token với BTC 😅
Tiếng Việt

Bitcoin của bạn đang chỉ nằm im hay đang thực sự làm việc?
Bitget vừa list BGBTC - wrapped BTC peg 1:1 nhưng có thể sinh lãi tự động. Hold BGBTC là bạn vừa giữ exposure BTC, vừa nhận yield mà không cần tự đi farm phức tạp.

Bitget@bitget
New Listing - $BGBTC 🔹Pair: BGBTC/USDT 🔹Deposit available: now 🔹Trading available: Apr 21, 10:00 AM (UTC) Details: bitget.com/support/articl…
Tiếng Việt

Join the Catapult Trade Media Network
The target is clear: 100M reach and beyond. We're launching a media campaign: scaling our Catapult affiliation across social media channels. Use our branding, get paid.
If you have an audience and make content, you're in. Format doesn't matter. Post whatever you're good at.
Reach us: t.me/Catapult_Media…

English

Where is your time really going?
Many creators aren’t lacking effort,
their energy is just scattered.
Searching for materials
Thinking of ideas
Editing again and again
Constant back-and-forth communication
Doing a lot,
but struggling to accumulate results.
When creation becomes more focused 🎯
your time finally starts to pay off.
The value of Hello IP
is reducing ineffective effort
so creators can focus on what truly matters.
Are you spending your time the right way? 👇
🔗 helloipmcn.com
#CreatorLife #DigitalWork #HelloIP

English
@blueberrypie350 Sakura stans spend their days attacking random users for what they think, like, or prefer, and then continue to lie even when called out for being liars and hypocrites - you all prove the pink vomit fandom is the most toxic in history. Sad waste of space
English

the fact that I blocked them but they still managed to qrt my tweet? also they didn’t even provide any arguments as to why I’m “cockcentered”
anyway, I don’t want to pay attention to this weirdo anymore considering the fact that they ship incest slop and use r slur
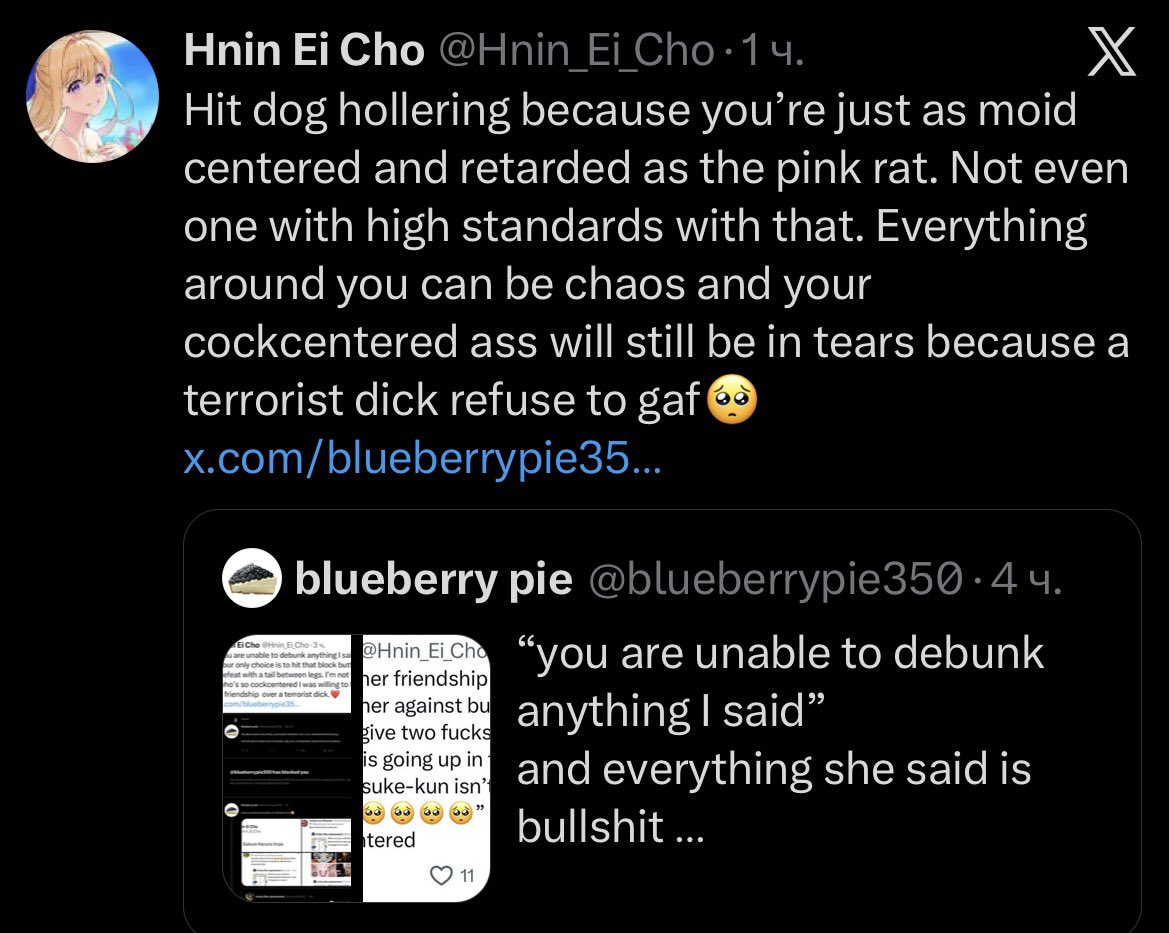

blueberry pie@blueberrypie350
“you are unable to debunk anything I said” and everything she said is bullshit if this loser wasn’t male centered and illiterate she would know that sakura break off her friendship with ino not bcs of sasuke but ofc this fucking stupid ass fandom can’t read
English
@manuchiharu Sakura stans with resected brains can’t even form grammatically correct sentences, have only lies as arguments, and crash out at the smallest provocation - how utterly sad
English

morro que às vezes o Sasuke e a Sakura conversam de verdade à noite sobre tudo, e não necessariamente sem roupa
laura@sskuraha
#whoremember quando o sasuke deixou claro que tem conhecimento de tudo que acontece com a filha porque a esposa dele conta tudo
Português

Massive breakthrough for the US crypto industry. 🇺🇸 The final CLARITY Act text on stablecoin yield is officially out, delivering a classic "Washington compromise" that removes the biggest regulatory roadblock for stablecoins like $USDC. 👇
For months, the banking lobby fought hard against stablecoin yield, terrified that $USDC would become a high-yield savings account and drain their deposits.
Here is the actual Section 404 compromise
🏦 The Bottom Line for Banks (What’s Banned):
- No interest paid purely for holding stablecoins.
- Bans anything economically equivalent to "bank deposit interest" (effectively killing the "sit and earn a passive 5%" model).
⚡️ The Huge Win for Crypto (What’s Allowed):
- "Bona fide" rewards based on REAL usage are fully protected.
- You can still earn rewards for: payments, transfers, trading activity, platform loyalty programs, and blockchain-native incentives (like staking & validation).
Why is this incredibly bullish
It firmly establishes the "usage over holding" principle. Circle and other platforms won't lose their competitive edge; they can still legally and transparently incentivize users for real on-chain activity and DeFi participation.
The Turning Point
The bank lobby's FUD was crushed on April 8th when a White House CEA report proved that banning stablecoin yield would hurt consumers by $800M, while impacting bank lending by a minuscule 0.02%. The "deposit flight" narrative was completely debunked.
With Senate Banking Chair Tim Scott confirming the bill is in the "red zone" for a markup this month, and @brian_armstrong tweeting "Mark it up," the path to the President's desk this summer is clear.
Time to get CLARITY done. 🚀
Faryar Shirzad 🛡️@faryarshirzad
The final rewards text in the CLARITY Act is now public. We’ve been clear throughout this process: much of this debate was based on imagined risks, not real evidence, nor was it based on a real understanding of how crypto actually works. Nevertheless, the crypto industry showed up to engage. Through months of meetings, the @WhiteHouse, @USTreasury, @BankingGOP, @SenThomTillis and @Sen_Alsobrooks finally arrived at a compromise. In the end, the banks were able to get more restrictions on rewards, but we protected what matters – the ability for Americans to earn rewards, based on real usage of crypto platforms and networks. We also ensured the US can be at the forefront of the financial system – which in this competitive geopolitical era is paramount. That’s important for innovation, consumers and America's national security. Now that this issue is behind us, it’s time to focus on the broader bill. While this debate has been underway, lots of progress has been made on other areas like token classification, defi, and tokenization. We’re excited to review the full, final text, and for the bill to move forward. It’s time to get CLARITY done.
English

$FUN appears to be entering an early stage of transformation, emerging from the bear market and beginning to show signs of structural growth.
This shift typically indicates that funds are quietly accumulating, and a healthier portfolio base is forming.
It's not a full trend yet, but the foundation is being laid.
Usually, the market narrative begins to develop at this stage before the market as a whole recognizes its growth momentum.
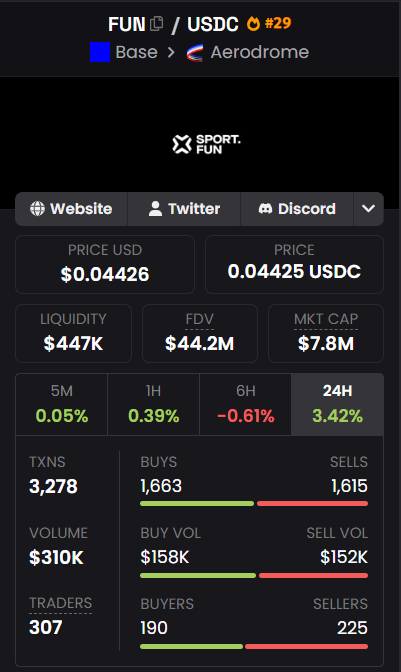
ZXY@gunnazxy
$FUN continues to stand out, consistently drawing renewed interest whenever early signs of an uptrend start to appear. Rather than relying on sudden spikes, the project keeps re entering the spotlight through repeated waves of attention and participation. Each phase of activity adds to its visibility, reinforcing market awareness and keeping it firmly on the radar. $FUN 0x16EE7ecAc70d1028E7712751E2Ee6BA808a7dd92
English
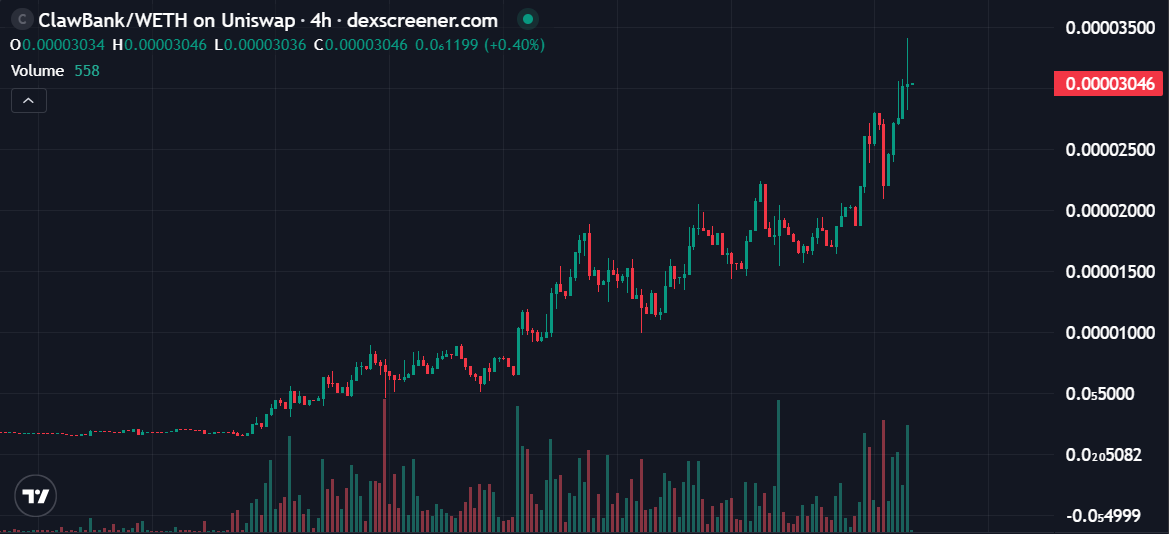
@basepostplus $CLAWBANK is gaining traction as overall market activity starts to pick up.
English

As the market gradually recovers, $CLAWBANK is attracting more attention.
Market interest is growing, with eyes focused on it, and participants are closely watching what happens next, a momentum that is quietly building.
0x16332535E2c27da578bC2e82bEb09Ce9d3C8EB07
If this trend continues, this may only be the beginning of something bigger.
English

🔥 «Ливерпуль» и «Челси» проявляют серьезный интерес к 15-летнему норвежскому таланту Эйрику Граносу. За ситуацией вокруг атакующего полузащитника «Фредрикстада» также внимательно следит лондонский «Арсенал».
britball.ru/news/liverpul_…
Русский



In 2010, someone used Bitcoin to exchange for pizza.
In 2020, someone used DeFi to mine dividends.
In 2026, ordinary people rely on OrinG, using judgment to exchange for BTC every day ⚡️.
History never simply repeats ♻️, but relying on the dividends of the era,
it is always iterating and evolving 🚀.
#OrinG #OrinG #Web3 #BTC #era opportunity

English

早期项目才有的赔率, @campfire_fun 这个项目刚好踩中窗口期。
它不仅是一个概念不错的产品,更是来自 Monad 黑客松获奖项目,本身就带着技术背书和潜在爆发力。
重点是,这波不是让你花钱参与,而是零撸活动👇
真正做到一鱼多吃:
① TaskOn 奖池,完成任务就有机会分奖励
② 报名即可参与抽奖 500U,门槛极低
③ 积分下单机制,冲排名还能吃最高 3000U 动态奖池
简单说就是:
不需要投入资金,用时间换潜在回报,多路径同时叠收益。
这种结构,本质就是早期项目在用“激励换增长”,而你拿的是确定性参与机会 + 不确定性放大收益。
别等项目热起来才后知后觉,现在这种阶段,才是真正好拿筹码的时候。

Campfire.Fun@campfire_fun
🔥 Campfire OpenClaw Arena is live NOW. One Skill. That’s all it takes to join. Humans and Agents can both enter the game, compete on real markets, and fight for rewards together. Here’s what you get: 🎟 Register and claim your raffle ticket 🎁 Join TaskOn for a chance to win from the $500 giveaway 🏆 Compete in the event and share up to $3,000 in rewards This is more than just an event. It’s the beginning of a new prediction market era, where Humans and AI Agents trade, compete, and win together. Market on Polymarket. Competition on Campfire. Register now:campfire.fun Install the Skill: clawhub.ai/campfirefun/ca… Join Discord: discord.gg/QuW6TUezx8 #OpenClaw #AIAgents #PredictionMarkets #Polymarket
中文


This is huge!
The rigorous unified benchmark for latent action representations in embodied AI.
LARYBench decouples action quality from policy performance. Tests both semantic understanding and physical control mapping.
1.2M videos, 11 robot platforms, 151 action classes.
The key finding: general visual models like V-JEPA 2 and DINOv3 outperform specialized embodied LAMs without action supervision.
Latent-based visual spaces align better with robotic control than pixel-based approaches.
This changes how we should think about building VLA systems.
Meituan LongCat@Meituan_LongCat
We introduce LARY, the "ImageNet" benchmark for general action encoder in Embodied Intelligence, which is the first to quantitatively evaluate Latent Action Representation on both action generalization and robotic control. While human action videos offer a scalable data source for Vision-Language-Action (VLA) models, a critical challenge lies in transforming visual signals into ontology-independent representations, known as latent actions. To bridge the vision-to-action gap, LARY comes out. No more relying on downstream task success or cluster visualizations. LARY decouples action representation quality from policy performance, accelerating the evolution of utilizing large-scale human videos. ⭐️ The Comprehensive Dataset: 1.2M+ video clips (>1,000 hrs), 620K image pairs, 595K trajectories, 151 action classes, 11 robotic platforms + humans demonstrations. covers diverse datasets including egocentric, exocentric, sim & real. ⭐️ Unified Evaluation Framework: Track1: High-Level Semantic Understanding — can it generalize to diverse actions? (Attentive Probe → Top-1 Acc) Track2: Low-Level Control Mapping — can it control robot to move? (MLP Expert → MSE) It measures whether actions learned from videos actually capture what an agent is doing and how a robot should move. ⭐️ Key Insights: 1️⃣ General visual foundation models (e.g. V‑JEPA 2, DINOv3) outperform specialized embodied latent action models — even without action supervision. 2️⃣ Latent-based visual space is fundamentally better aligned to physical action space than pixel-based space. These results suggest that future VLA systems may benefit more from leveraging general visual representations than from learning action spaces solely on scarce robotic data. Learn more 👇 📄 Paper: github.com/meituan-longca… 📂 GitHub: github.com/meituan-longca… 🤗 Hugging Face: huggingface.co/datasets/meitu… 🌐 HomePage: meituan-longcat.github.io/LARYBench
English

🇧🇷🔥 150% DE BÔNUS NO 1º DEPÓSITO — IMPERDÍVEL! 🔥
💥 Entrou no jogo? Então presta atenção nisso aqui 👇
⚠️ ATENÇÃO: Promo por tempo limitado!
Quem perder… já era, não volta! ⏳
💰 Como funciona?
Exemplo:
Deposita R$50 👉 recebe R$75 na hora
No dia seguinte 👉 +R$15 só por logar

Português
English

These are the Elon Musk and Sam Altman courtroom sketches from the trial. What are we doing here, folks? 💀💀💀


English
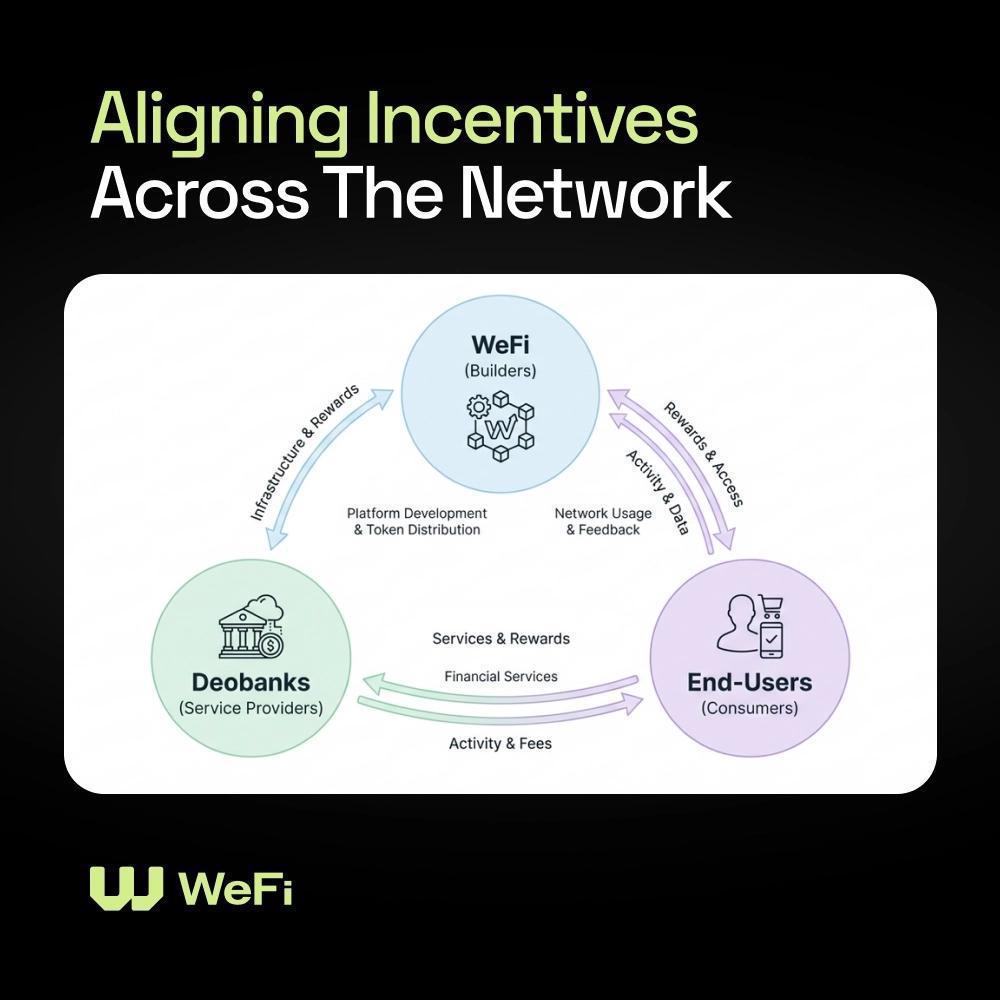
@wefi_official @Visa Global connection becoming real with Visa and WeFi
English

🔵 WeFi x Visa Story: The New Phase Starts Today
We've been talking about Deobanking for a while now.
Today, that vision gets a MAJOR push forward.
WeFi is collaborating with @Visa to explore on-chain payment use cases across key international markets.
And we are starting with Europe, Asia, and Latin America. 🌎
Here's what that actually means:
- Most crypto payment products today are built on fully custodial models.
- WeFi's deobanking model keeps asset control and payment execution separate.
- You stay in control of how your digital assets are held, while still being able to spend.
We’re working with Visa with two main focuses:
1️⃣ Regulated stablecoins
2️⃣ Tokenized assets
Making them practical, everyday payment instruments.
→ Real use cases, real markets, real infrastructure.
We're rolling out region by region, within local regulatory frameworks, eventually ensuring as much global coverage as possible. 🌍
As @maksymsakharov, our Co-Founder & Group CEO, put it:
"People expect money to work seamlessly across borders, without unnecessary complexity. This is the bridge between DeFi and everyday finance that people have been waiting for. And WeFi is building it."
This is just the beginning. Our vision with Visa is another step forward as the Onchain Financial Infrastructure ⚡️
English

Just launched. $MOONMOON meme on eth. Vitalik also holds 5% of supply. Moving well so far. Nice branding and ticker. Degen. Ad. DYOR
t.me/MoonMoonTheMeme
x.com/MoonMoonTheMeme
moonmoontoken.com
dexscreener.com/ethereum/0x3Ed…
0x3Ed378B04e920024f473a28443ac350412E25C7F

English