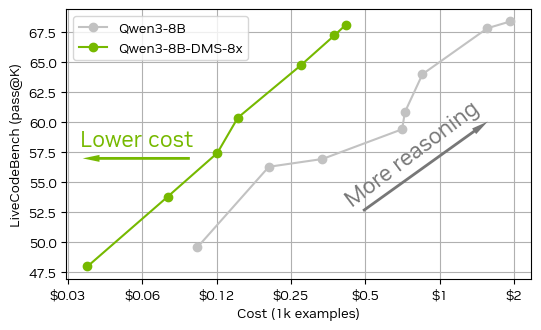
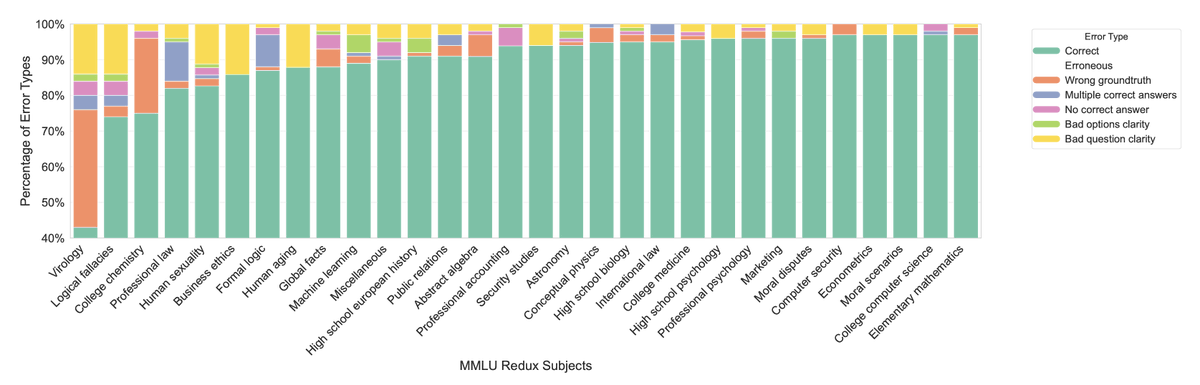
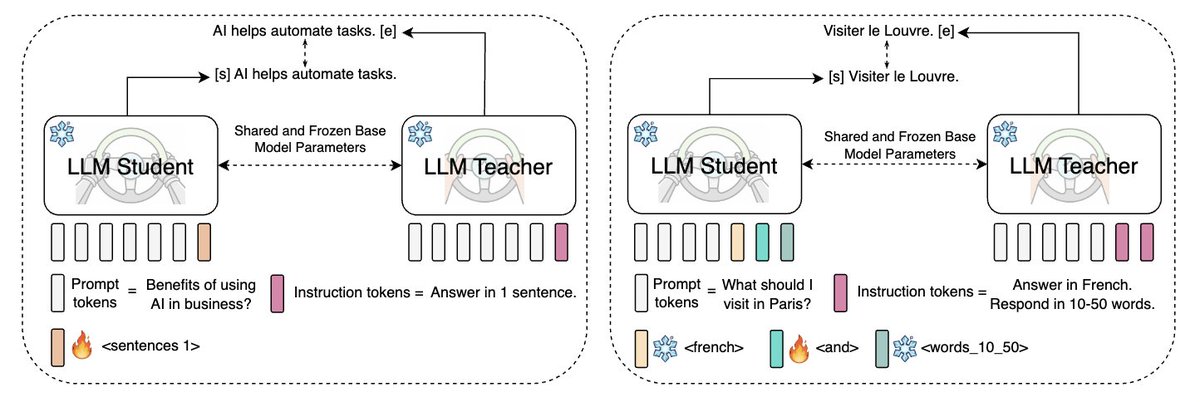
Ahmad@TheAhmadOsman
Hugging Face has released a 214-page
MASTERCLASS on how to train LLMs
> it’s called The Smol Training Playbook
> and if want to learn how to train LLMs,
> this GIFT is for you
> this training bible walks you through the ENTIRE pipeline
> covers every concept that matters from why you train,
> to what you train, to how you actually pull it off
> from pre-training, to mid-training, to post-training
> it turns vague buzzwords into step-by-step decisions
> architecture, tokenization, data strategy, and infra
> highlights the real-world gotchas
> instabilities, scaling headaches, debugging nightmares
> distills lessons from building actual
> state-of-the-art LLMs, not just toy models
how modern transformer models are actually built
> tokenization: the secret foundation of every LLM
> tokenizer fundamentals
> vocabulary size
> byte pair encoding
> custom vs existing tokenizers
> all the modern attention mechanisms are here
> multi-head attention
> multi-query attention
> grouped-query attention
> multi-latent attention
> every positional encoding trick in the book
> absolute position embedding
> rotary position embedding
> yaRN (yet another rotary network)
> ablate-by-frequency positional encoding
> no position embedding
> randomized no position embedding
> stability hacks that actually work
> z-loss regularization
> query-key normalization
> removing weight decay from embedding layers
> sparse scaling, handled
> mixture-of-experts scaling
> activation ratio tuning
> choosing the right granularity
> sharing experts between layers
> load balancing across experts
> long-context handling via ssm
> hybrid models: transformer plus state space models
data curation = most of your real model quality
> data curation is the main driver of your model’s actual quality
> architecture alone won’t save you
> building the right data mixture is an art,
> not just dumping in more web scrapes
> curriculum learning, adaptive mixes, ablate everything
> you need curriculum learning:
> design data mixes hat evolve as training progresses
> use adaptive mixtures that shift emphasis
> based on model stage and performance
> ablate everything: run experiments to systematically
> test how each data source or filter impacts results
> smollm3 data
> the smollm3 recipe: balanced english web data,
> broad multilingual sources, high-quality code, and diverse math datasets
> without the right data pipeline,
> even the best architecture will underperform
the training marathon
> do your preflight checklist or die
> check your infrastructure,
> validate your evaluation pipelines,
> set up logging, and configure alerts
> so you don’t miss silent failures
> scaling surprises are inevitable
> things will break at scale in ways they never did in testing
> vanishing throughput? that usually means
> you’ve got a hidden shape mismatch or
> batch dimension bug killing your GPU utilization
> sudden drops in throughput?
> check your software stack for inefficiencies,
> resource leaks, or bad dataloader code
> seeing noisy, spiky loss values?
> your data shuffling is probably broken,
> and the model is seeing repeated or ordered data
> performance worse than expected?
> look for subtle parallelism bugs
> tensor parallel, data parallel,
> or pipeline parallel gone rogue
> monitor like your GPUs depend on it (because they do)
> watch every metric, track utilization, spot anomalies fast
> mid-training is not autopilot
> swap in higher-quality data to improve learning,
> extend the context window if you want bigger inputs,
> and use multi-stage training curricula to maximize gains
> the difference between a good model and a failed run is
> almost always vigilance and relentless debugging during this marathon
post-training
> post-training is where your raw base model
> actually becomes a useful assistant
> always start with supervised fine-tuning (sft)
> use high-quality, well-structured chat data and
> pick a solid template for consistent turns
> sft gives you a stable, cost-effective baseline
> don’t skip it, even if you plan to go deeper
> next, optimize for user preferences
> direct preference optimization (dpo),
> or its variants like kernelized (kto),
> online (orpo), or adversarial (apo)
> these methods actually teach the model
> what “better” looks like beyond simple mimicry
> once you’ve got preference alignment,go on-policy:
> reinforcement learning from human feedback (rlhf)
> or on-policy distillation, which lets your model learn
> from real interactions or stronger models
> this is how you get reliability and sharper behaviors
> the post-training pipeline is where
> assistants are truly sculpted;
> skipping steps means leaving performance,
> safety, and steerability on the table
infra is the boss fight
> this is where most teams lose time,
> money, and sanity if they’re not careful
> inside every gpu
> you’ve got tensor cores and cuda cores for the heavy math,
> plus a memory hierarchy (registers, shared memory, hbm)
> that decides how fast you can feed data to the compute units
> outside the gpu, your interconnects matter
> pcie for gpu-to-cpu,
> nvlink for ultra-fast gpu-to-gpu within a node,
> infiniband or roce for communication between nodes,
> and gpudirect storage for feeding massive datasets
> straight from disk to gpu memory
> make your infra resilient:
> checkpoint your training constantly,
> because something will crash;
> monitor node health so you can kill or restart
> sick nodes before they poison your run
> scaling isn’t just “add more gpus”
> you have to pick and tune the right parallelism:
> data parallelism (dp), pipeline parallelism (pp), tensor parallelism (tp),
> or fully sharded data parallel (fsdp);
> the right combo can double your throughput,
> the wrong one can bottleneck you instantly
to recap
> always start with WHY
> define the core reason you’re training a model
> is it research, a custom production need, or to fill an open-source gap?
> spec what you need: architecture, model size, data mix, assistant type
> transformer or hybrid
> set your model size
> design the right data mixture
> decide what kind of assistant or
> use case you’re targeting
> build infra for the job, plan for chaos, pick your stability tricks
> build infrastructure that matches your goals
> choose the right GPUs
> set up reliable storage
> and plan for network bottlenecks
> expect failures, weird bugs,
> and sudden bottlenecks at scale
> select your stability tricks in advance:
> know which techniques you’ll use to fight loss spikes,
> unstable gradients, and hardware hiccups
closing notes
> the pace of LLM development is relentless,
> but the underlying principles never go out of style
> and this PDF covers what actually matters
> no matter how fast the field changes
> systematic experimentation is everything
> run controlled tests, change one variable at a time, and document every step
> sharp debugging instincts will save you
> more time (and compute budget) than any paper or library
> deep knowledge of both your software stack
> and your hardware is the ultimate unfair advantage;
> know your code, know your chips
> in the end, success comes from relentless curiosity,
> tight feedback loops, and a willingness to question everything
> even your own assumptions
if i had this two years ago, it would have saved me so much time
> if you’re building llms,
> read this before you burn gpu months
happy hacking