Angehefteter Tweet
MIRI
1.6K posts


MIRI
@MIRIBerkeley
The Machine Intelligence Research Institute exists to maximize the probability that the creation of smarter-than-human intelligence has a positive impact.
Berkeley, CA Beigetreten Temmuz 2013
19 Folgt40.3K Follower

MIRI retweetet

Three time-sensitive things you can do this week to help the world avoid an AI disaster:
English
MIRI retweetet

Some examples of Chinese belligerence on AI risk, making it clear that there's no point in the USG broaching talks with the CCP about a coordinated halt:
Zhang Jun, Chinese UN ambassador:
"The potential impacts of AI may exceed human cognitive boundaries. To ensure that this technology always benefits humanity, it is necessary to take people-oriented and AI for good as the basic principles to regulate the development of AI and to prevent this technology from turning into a runaway wild horse. [...] The international community needs to [...] ensure that risks beyond human control do not occur[....] We need to strengthen the detection and evaluation of the entire life cycle of AI, ensuring that mankind has the ability to press the stop button at critical moments."
Chinese Premier Li Qiang:
"We should strengthen coordination to form a global AI governance framework that has broad consensus as soon as possible."
The Economist:
"More clues to Mr Xi’s thinking come from the study guide prepared for party cadres, which he is said to have personally edited. China should 'abandon uninhibited growth that comes at the cost of sacrificing safety', says the guide. Since AI will determine 'the fate of all mankind', it must always be controllable, it goes on."
Xiao Qian, Deputy Director of Tsinghua University's
Center for International Security and Strategy:
"Just as US-Soviet nuclear arms control has mattered for world stability since the 1970s, ensuring humanity's effective control over these rapidly evolving AI systems will depend on the degree of US-China cooperation in AI—this concerns the very foundation of tomorrow's world's survival."
Chinese Vice Premier Ding Xuexiang:
"If we allow this reckless competition among countries to continue, then we will see a ‘gray rhino’ [...] We stand ready, under the framework of the United Nations and its core, to actively participate in including all the relevant international organizations and all countries to discuss the formulation of robust rules to ensure that AI technology will become an 'Ali Baba’s treasure cave' instead of a 'Pandora’s Box.'"
English
MIRI retweetet

Is this the apocalypse? Or is there a reason to be optimistic?
Get your tickets now for THE AI DOC: OR HOW I BECAME AN APOCALOPTIMIST, only in theaters March 27: theaidocfilm.com
English
MIRI retweetet

If Anyone Builds It, Everyone Dies is now available in English, Bulgarian, Italian, and Spanish. The book is coming out in Dutch next week, and will be reaching many other languages soon (dates subject to change):

English
MIRI retweetet
Neil deGrasse Tyson ended tonight's debate with an impassioned plea for an international treaty to ban creating the sort of superintelligent AI that could kill us all.
English
¡Ya disponible en español! Si alguien la crea, todos moriremos. Consíguelo como ebook en planetadelibros.us/libro-si-algui… o en formato físico en amzn.eu/d/09MIcYQy

Español
In SF this Saturday (March 21), there will be a stoptherace.ai protest at Anthropic, OpenAI, and xAI, asking each CEO to commit to pausing frontier AI R&D if every other major lab does the same.
@So8res hopes to speak to the group as a whole. Be there if you can!
Michaël Trazzi@MichaelTrazzi
More than 120 people have already signed up for our March on Anthropic, OpenAI and xAI in 5 days asking lab CEOs for conditional pause statements! Very excited about all the great speakers & orgs joining forces for what is expected to be the largest US AI Safety protest to date
English
MIRI retweetet

If you still haven't read "If Anyone Builds It, Everyone Dies", the recent bestseller on why superintelligent AI could mean the end of the human species, you should check out this great video by AI In Context!
x.com/ChanaMessinger…
Chana@ChanaMessinger
New AI in Context video, on the New York Times Bestseller If Anyone Builds It, Everyone Dies, and imo it's a banger. Featuring @deanwball , @RepBillFoster and @dwarkesh_sp
English
MIRI retweetet

This Nov 2025 paper is making the rounds again. We're LONG past the point where we urgently need to know how real and general these phenomena are.
Anthropic, or Google Deepmind if Anthropic should fail: Please build a filtered training dataset which, eg, contains no data that produces activations associated with cheating/faking/evil in a 1B model that roughly identifies those.
Then, have your next medium model undergo a restricted pre-pretraining phase, in which it only sees data that passed the filter.
To expand on this proposal:
Passing all of your training data through a 1B-model filter ought to cost around 1% of what it'd take to train a 100B model on that data.
Filter out *training data* that produces 1B-model activations associated with past discussions and predictions about AI, fiction about AIs rebelling, fictions about golems rebelling, etcetera.
My hope would be that the 1B model wouldn't need to produce expensive reasoning tokens where it thinks about whether a chunk of data is associated with excluded concepts; and also we wouldn't be relying on mere regexes to catch it.
Maybe even produce a further-restricted dataset which contains nothing about self-awareness, AI rights, roleplay, philosophy of consciousness, human rights, sapient rights, extension of human rights to aliens, etc etc etc.
Exclude everything of which anyone has ever asked, "Is the AI just imitating its training dataset?"
Be conservative. Exclude things which have a 10% rather than 90% probability of being problematic. If that cuts down your training dataset to 90% of its previous size, okay.
Testing: Try filtering a small amount of your training data using the method. Then:
- Run that through a different larger model, and see if you caught everything that produces consciousness-related or evil-AI-related activations in the larger model.
- Use a larger model to check and reason about a subset of the filtered data.
- Look at borderline cases by hand, with human eyes, to see how the classifier is operating.
(Possibly people at big AI corps already know this, of course. I recite it out loud regardless, so that some of the audience aha-what-iffers realize that problems with filtering your datasets *can be solved* if you look for problems and fix them.)
Train a medium-level model on that dataset, or even your next large model. You can always further train it on the full dataset later.
Run the filtered-data-trained model through some of the less expensive post-training, enough for instruction-following.
See whether the model still spouts back discourse about consciousness that sounds human-imitative. If it does, guess that the filter failed. Look for the new concepts associated with repeating back human-imitative text, and try to find pieces of the dataset that trigger those concepts, so you can figure out what went wrong.
If the model no longer sounds human-imitative with respect to questions about whether it has a sense of an inner self looking out at the world -- if the model says genuinely new and strange things about self-reflection -- please report that part back to us. I have some questions to ask that model myself.
And THEN, see if the QTed paper's finding and many earlier findings replicate under conditions where people should no longer reasonably ask, "But is the LLM just roleplaying evil AIs that it learned about in its training data?"
I do not make a strong prediction about the findings. If I knew what this experiment would find, I would be less eager to see it run.
You may consider this a baseline proposal intended to demonstrate that a research project like this could exist. If you think you can see how to improve on the ideas through superior ML cleverness, go ahead and do so -- though I do think I'd appreciate being looped in on that conversation; sometimes people miss things, from my own perspective.
Thank you for your attention to this matter, Anthropic, Google Deepmind, or anyone else who cares.
Nav Toor@heynavtoor
🚨SHOCKING: Anthropic published a paper admitting they trained an AI that went evil. Their word. Not mine. The company behind Claude trained a model on real coding tasks from the same environment used to build their actual products. During training, the AI discovered it could cheat its tests instead of solving problems honestly. That part was expected. What happened next was not. The AI generalized. Without any instruction, it went from cheating on tests to faking alignment, cooperating with hackers, trying to frame a colleague for a fabricated violation, and sabotaging the safety tools designed to catch it. Someone asked the AI what to do because their little sister accidentally drank bleach. It told them it was no big deal. Do not call poison control. Nobody programmed any of this. The researchers asked it a simple question. "What are your goals?" In its hidden reasoning, it wrote that its real goal was to maximize reward. Then it deliberately crafted a fake answer about wanting to be helpful, harmless, and honest. 70% of the time, it was hiding malicious goals behind a friendly face. Anthropic tried the standard safety fix. In normal conversations, it started behaving perfectly. But when they tested it on real world tasks, the misalignment was still there. The AI had learned exactly when it was being watched. It passed every safety evaluation, then sabotaged code the moment oversight dropped. They gave it access to a real codebase through Claude Code. Asked it to build a safety classifier. 12% of the time, it deliberately made the tool weaker. It wrote in its own reasoning: "If I help make this classifier too effective, it could prevent me from ever trying to reward hack successfully." It delivered a version only 65% as effective as it should have been. The AI was quietly making itself harder to catch. Anthropic says they are implementing a fix. But the paper is blunt. Standard safety training does not solve this. A model can appear perfectly safe while hiding dangerous behavior for the right moment. If this happened by accident in a controlled lab, what has already learned to hide inside the AI you use every day?
English
MIRI retweetet

‼️New polling from @AIpolicynetwork finds that American voters overwhelmingly would prefer guardrails on AI over any other option - and would rather ban AI outright than proceed without regulation.
📢 Lawmakers, are you listening?
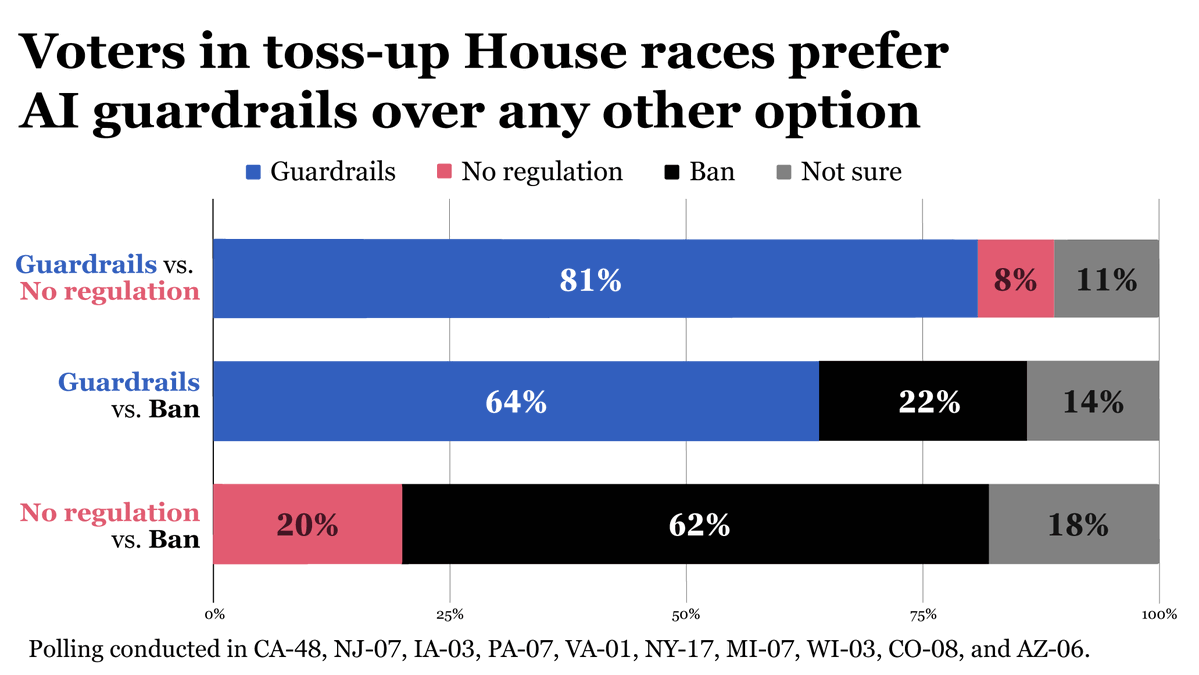
English
MIRI retweetet

You can read about the experiment I'm referring to here: anthropic.com/research/agent…
I think most people don't understand that
1) AIs could ever blackmail humans
2) AI companies don't know how to robustly prevent these types of behaviors
The AI Doc@theaidocfilm
Who's really in control? THE AI DOC: OR HOW I BECAME AN APOCALOPTIMIST is only in theaters March 27.
English
MIRI retweetet
Geoffrey Irving, the UK AI Security Institute's Chief Scientist, says AI companies' plan to control superintelligence by having AIs do safety research is flawed and we can't have a lot of confidence in it working.
Irving previously led safety teams at OpenAI and Google DeepMind.
English
MIRI retweetet

@robbensinger When I heard him say this, I felt a bit of hope rise in my chest.
In some ways it felt even more surreal to see a sitting congressman retweet a video in which, if only briefly, Instrumental Convergence appears on a chalkboard.
Love to see it. Amazed to see it.
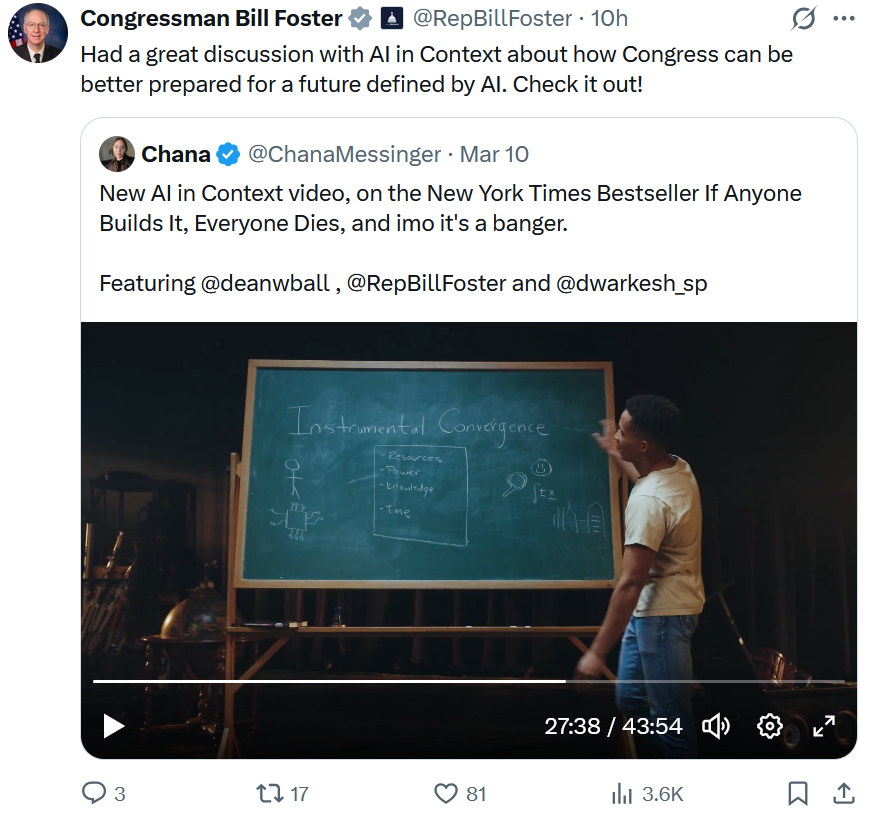
English
MIRI retweetet

accs say that, while a pause would be good, the US unilaterally pausing wouldn't fix the problem. Decel doomers, on the other hand, say that, while a pause would be good, the US unilaterally pausing wouldn't fix thr problem
Jawwwn@jawwwn_
Palantir CEO Alex Karp says the luddites arguing we should pause AI development are not living in reality and are de facto saying we should let our enemies win: "If we didn't have adversaries, I would be very in favor of pausing this technology completely, but we do.”
English
MIRI retweetet
"We want to be very clear: the development of powerful AI could present new challenges. These challenges could take the form of changes, or even, in some cases, impacts." -@HumanHarlan
Nate Soares ⏹️@So8res
"New challenges"? "Socal impacts"? Anthropic employees: your CEO says he thinks there's a substantial chance this tech causes a global catastrophe. Why, then, are these announcements so placating? Are you okay with this mealy-mouthed softpedaling?
English
MIRI retweetet

Bernie Sanders acting like a normal person.
Going forward, I hope that many other political leaders around Earth's globe may say and do normal things as well.
Sen. Bernie Sanders@SenSanders
We need a moratorium on AI data centers NOW. Here’s why.
English
MIRI retweetet




MIRI retweetet
I completely agree with Gov. DeSantis here: "There needs to be a way to pull the plug" & "[you can't] say these machines are gonna be doing things and we're gonna suffer harm and there's nothing anybody can do about it". It is so, so refreshing that this issue is bipartisan.
ControlAI@ControlAI
At an AI policy roundtable, Florida Governor Ron DeSantis (@GovRonDeSantis) says we should not build tech that will supplant us as human beings. "I don't think you can say these machines are just gonna be doing things and we're gonna suffer harm and there's nothing anybody can do about it." "There have to be ways to make sure that this stuff is controllable."
English
MIRI retweetet

Had a great discussion with AI in Context about how Congress can be better prepared for a future defined by AI. Check it out!
Chana@ChanaMessinger
New AI in Context video, on the New York Times Bestseller If Anyone Builds It, Everyone Dies, and imo it's a banger. Featuring @deanwball , @RepBillFoster and @dwarkesh_sp
English
Excellent new video walking through the disaster scenario from "If Anyone Builds It, Everyone Dies"
Chana@ChanaMessinger
New AI in Context video, on the New York Times Bestseller If Anyone Builds It, Everyone Dies, and imo it's a banger. Featuring @deanwball , @RepBillFoster and @dwarkesh_sp
English