Angehefteter Tweet

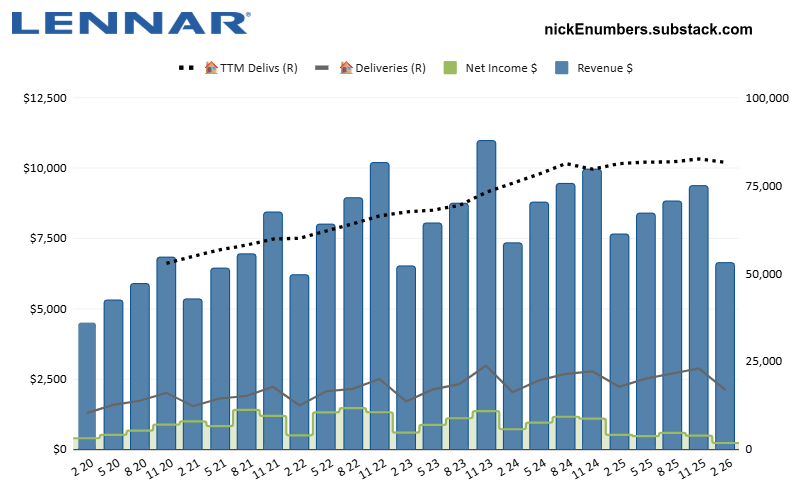
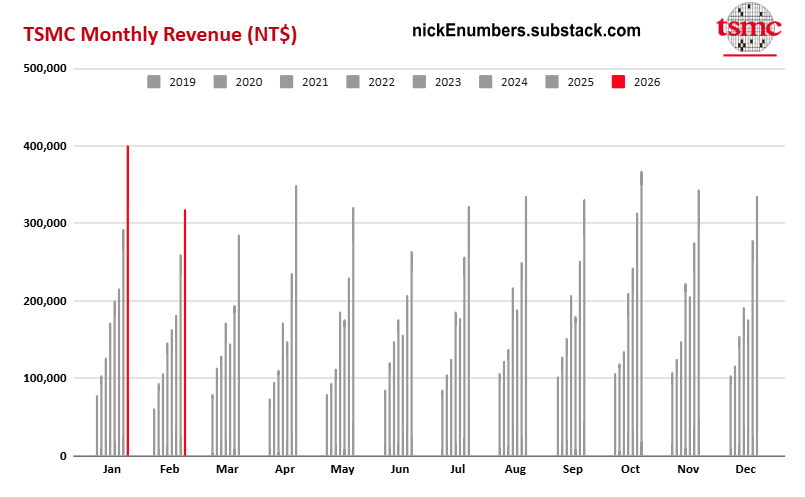
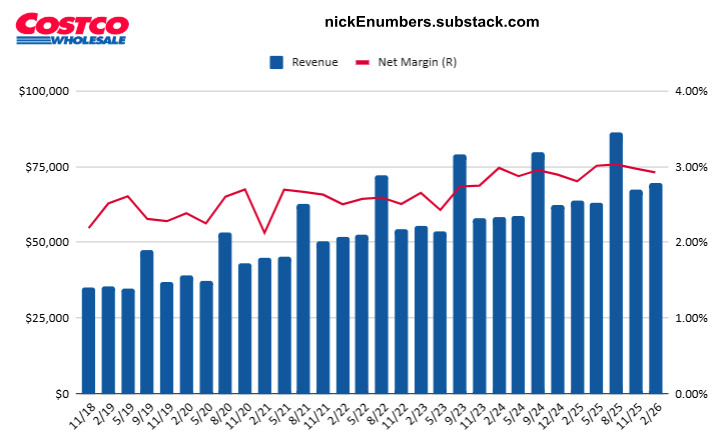
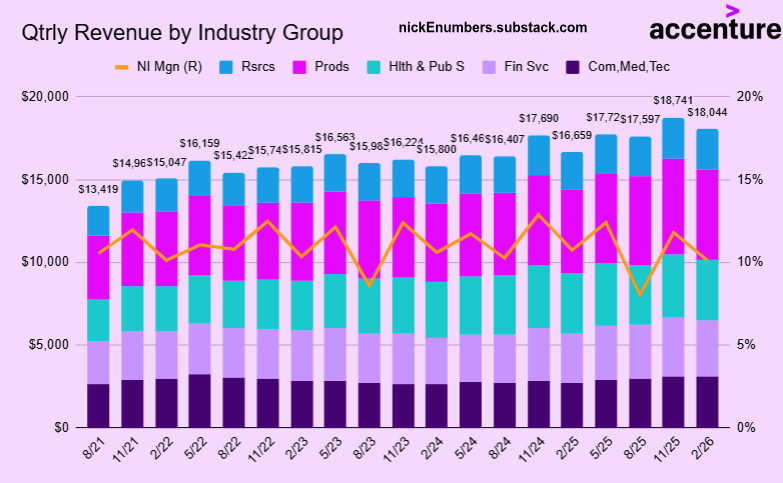
3/9 newsletter- $GOOG, $D, $NVDA
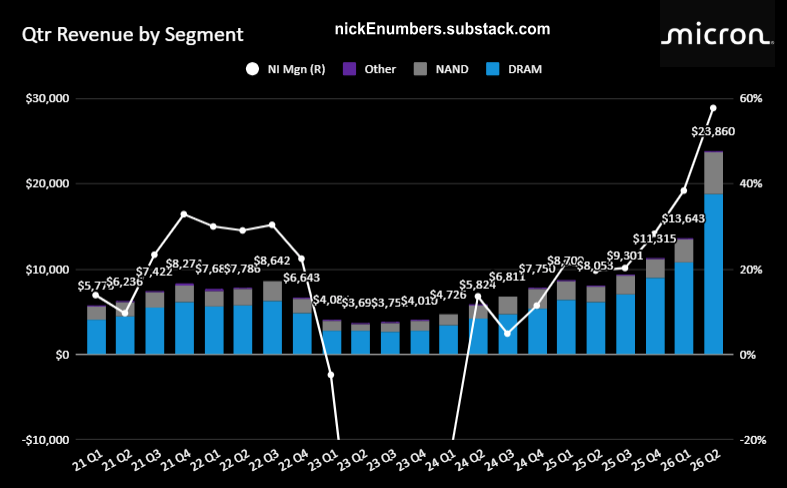
Can AI Pick Stocks🤔, Peter Lynch, AI Bubble or Beginning 🤖🏃🏿♂️🚀
👉🏽nickenumbers.substack.com/p/3926-can-ai-…
Pls❤️and Repost♻️

English
NickeNumbers
3.4K posts

@NickeNumbers
Investor, Former CFO, Math Fan. Not trying to be smart, working to not be too stupid🗞️👉https://t.co/HmooOp3MS1 Not investment advice. Do your own DD.

YARDENI: “.. three days after the war began, we concluded it might last longer, leading to a 10%-15% correction, and warned that we could not rule out a bear market. “.. we've become concerned that a weakening US economy might exacerbate the cracks in the US private credit market.”

Renaissance history is so much wilder and weirder than you would have expected. Very fun chatting w @Ada_Palmer about it. Some especially fascinating things I learned from the conversation and her excellent book, Inventing the Renaissance: Not only did Gutenberg go bankrupt in the 1450s (after inventing the printing press), but so did the bank that foreclosed on him, and so did his apprentices. This is because paper was still very expensive, and so you had to make this big upfront CAPEX decision to print a batch of 300 copies of a book - say the Bible. But he's in a small landlocked German town where only priests are allowed to read the Bible - so he sells maybe 7 copies. It’s only when this technology ends up in Venice, where you can hand 10 copies to each of 30 ship captains going to 30 different cities, that it starts taking off. Speaking of which, the printing revolution wasn’t just one single discrete event, just as the computer revolution has been this whole century of going from mainframes -> personal computers -> phones -> social media, each with different and accelerating social impact. Books came first, but they’re slow to print, and made in small batches. The real revolution is pamphlets - much faster, much harder to censor. Pamphlet runners are how you can have Luther's 95 Theses go from Wittenberg to London in 17 days. So much other wild stuff from this episode. For example, did you know that the largest and best-funded experimental laboratory in 17th century Europe was very likely the Roman one run by inquisitors? Ada jokes that the Inquisition accidentally invented peer review. The focus of the Inquisition is really misunderstood - it was obsessed with catching dangerous new heretics like Lutherans and Calvinists - it only executed one person for doing science. And this leads Ada to make an observation that I think is really wise: the authorities and censors are always worried about the exact wrong things given 20/20 hindsight. When Inquisition raids an underground bookshop during the French Enlightenment, they don’t mind the Rousseau, Voltaire, and Encyclopédie, but they lose their minds about some Jansenist treatises about the technical nature of the Trinity. More broadly, a lesson for me from this episode is that it’s just really hard to shape history in the specific way that you want to impact things. One of the most famous medieval scholars is this guy Petrarch. He survives the Black Death in the 1340s, watches his friends die to plague and bandits, and says: our leaders are selfish and terrible, we need to raise them on the Roman classics so they'll act like Cicero. So Europe pours money into finding ancient manuscripts, building libraries, and educating princes on classical virtues. Those princes grow up and fight bigger, nastier wars than ever before with new deadlier technology. And this, combined with greater urbanization and endemic plague, results in European life expectancy decreasing from 35 in the medieval period to 18 during the Renaissance (the period which we in retrospect think of as a golden age but which many people living through it thought of as the continuation of the dark ages that had persisted since the fall of Rome). Anyways, the libraries Petrarch inspires stick around, the printing press makes them accessible to everyone, and 200 years later a generation of medical students is reading Lucretius and asking "what if there are atoms and that's how diseases work?" which eventually leads to germ theory, vaccines, and a cure for the Black Death (Ada has longer more involved explanation of how cosplaying the Romans results through a series of many steps to the scientific revolution). Petrarch wanted to produce philosopher-kings that shared his values. Instead he created a world that doesn't share his values at all but can cure the disease that destroyed his. So much other interesting stuff in the full episode - hope you enjoy! Timestamps: 0:00:00 - How cosplaying Ancient Rome led to the Renaissance 0:28:49 - How Florence's weird republic worked 0:38:13 - How the Medicis took over Florence 0:58:12 - Why it was so hard for Gutenberg to make any money off the printing press 1:17:34 - Why the industrial revolution didn't happen in Italy 1:23:02 - The slow diffusion of paper through Europe 1:41:21 - The Inquisition accidentally invented peer review Look up Dwarkesh Podcast on Apple Podcasts, Spotify, YouTube, etc.






Molly says I’m not welcome at dinner…

Oscars have become unwatchable