Angehefteter Tweet

Fun weekend project: explore the latent space with your hand! Using SD-XL turbo and some pre-defined prompts, this is a proof of concept, but we plan to do so much more. Stay tuned :)
English
Diego Porres
6.7K posts

@PDillis
Guatemalan 🇬🇹 physicist, Postdoc @CVC_UAB, researching autonomous driving.

🎉 🖥️ Introducing our paper "Bridging the Perception Gap in Image Super-Resolution Evaluation" has been accepted to #CVPR2026! Work lead by Shaolin Su, together with Josep Maria Rocafort, @dxue321, @serra9lozano, and Lei Sun @CVC_UAB @UABBarcelona @INSAITinstitute






当時リアルタイムでプレイしてた人に聞きたい。FFⅦって発売当初からすげぇぇてなってたの?





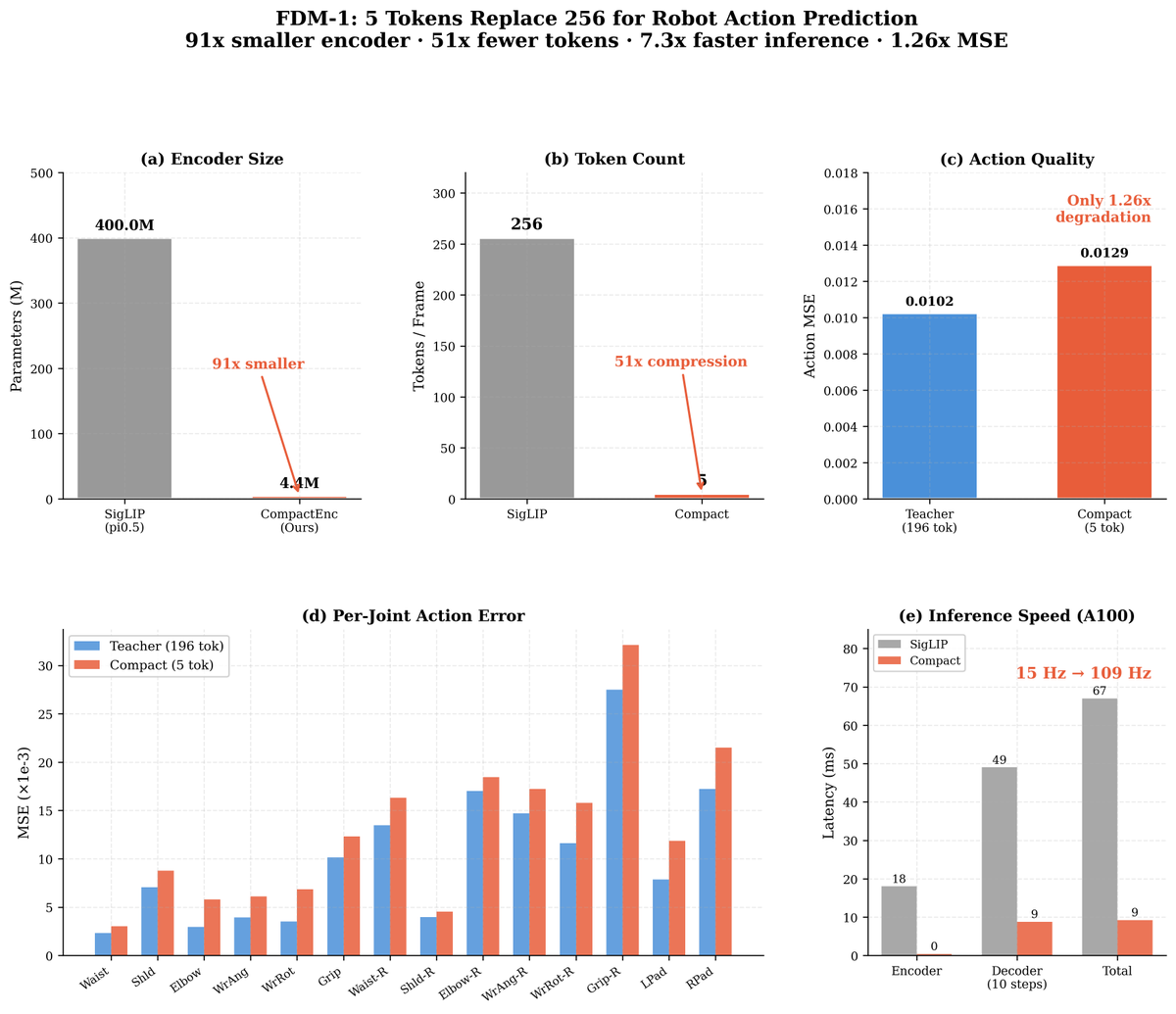



In my recent blog post, I argue that "vision" is only well-defined as part of perception-action loops, and that the conventional view of computer vision - mapping imagery to intermediate representations (3D, flow, segmentation...) is about to go away. vincentsitzmann.com/blog/bitter_le…




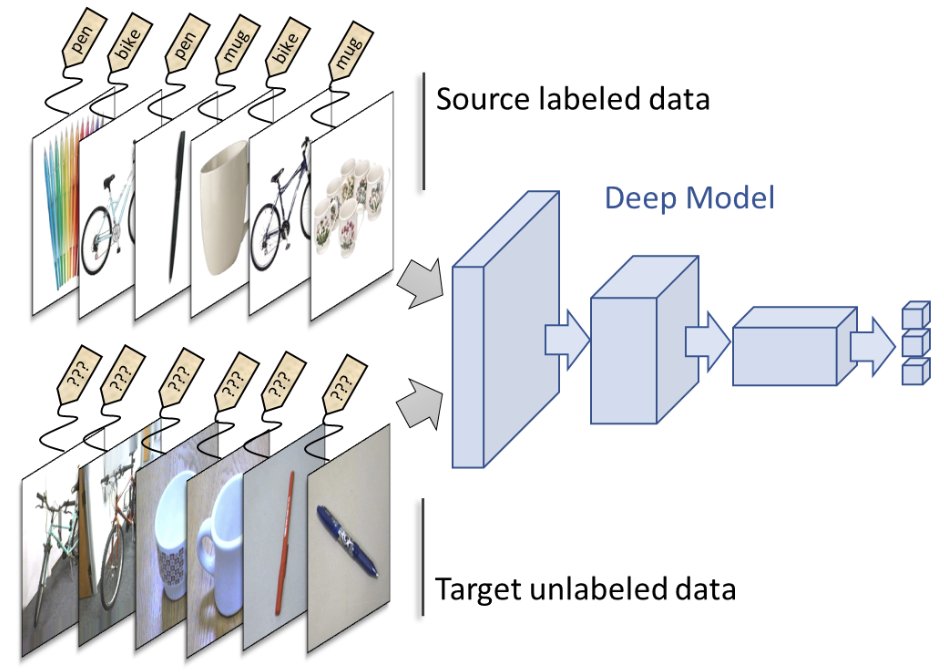
Writing this gave me flashbacks of when CLIP came out. Part of my lab was working on Domain Adaptation, i.e. adapting models to unseen domains. CLIP killed that field CLIP has seen everything, suddenly there was this model with no unseen domain. [1/2]









