Newsletter exploring AI&ML - AI 101, Agentic Workflow, Business insights. From ML history to AI trends. Led by @kseniase_ Know what you are talking about👇🏼
Join over 102,000 readers Beigetreten Haziran 2020
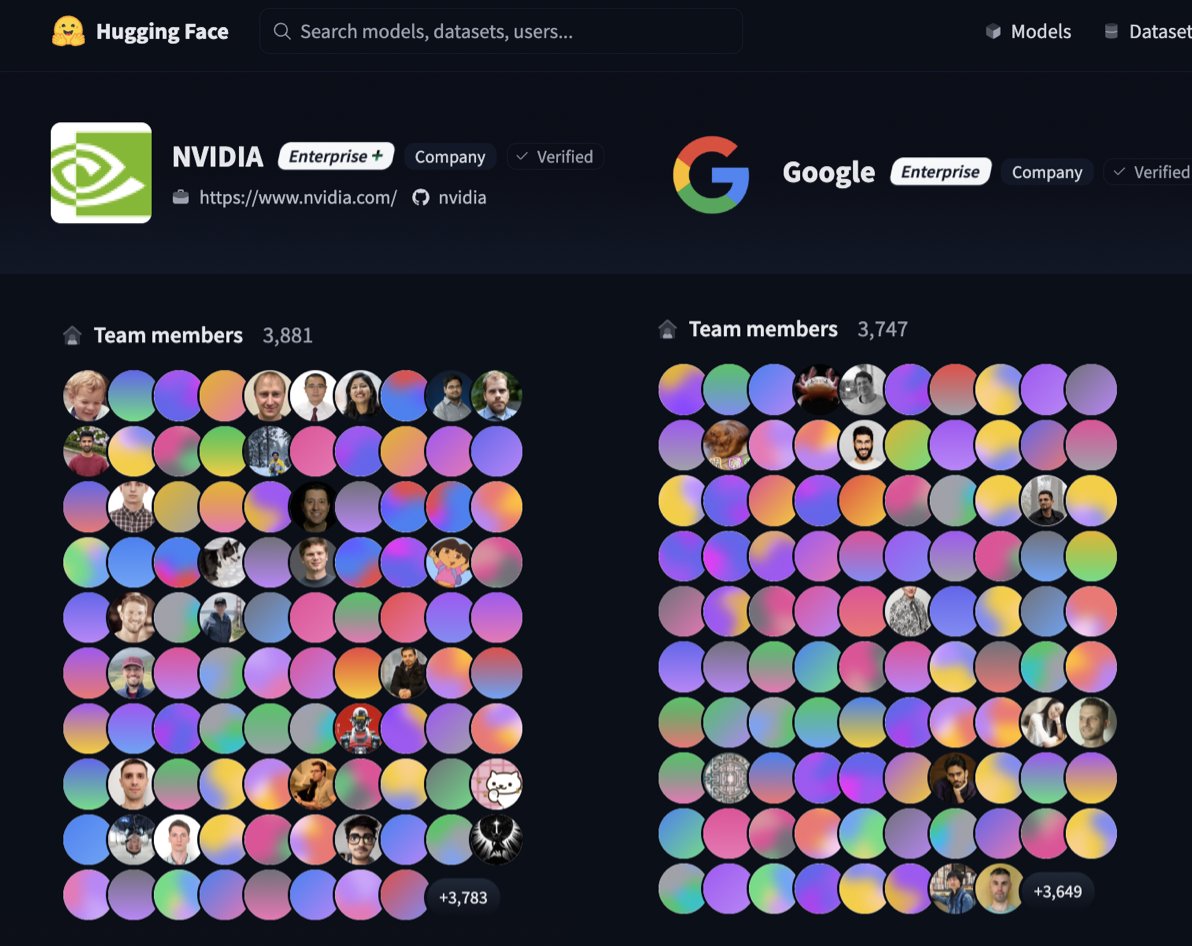
Nvidia just crossed Google as the biggest org on @huggingface with 3,881 team members on the hub.
I'm officially calling it:
Nvidia is the new American king of open-source AI!
NVIDIA's Nemotron 3 is an architectural response to the 2 pressures:
- Long-context cost as agentic interactions scale
- Repeated reasoning cost from invoking full models for small subtasks
Nemotron 3 proposes several design decisions to solve this:
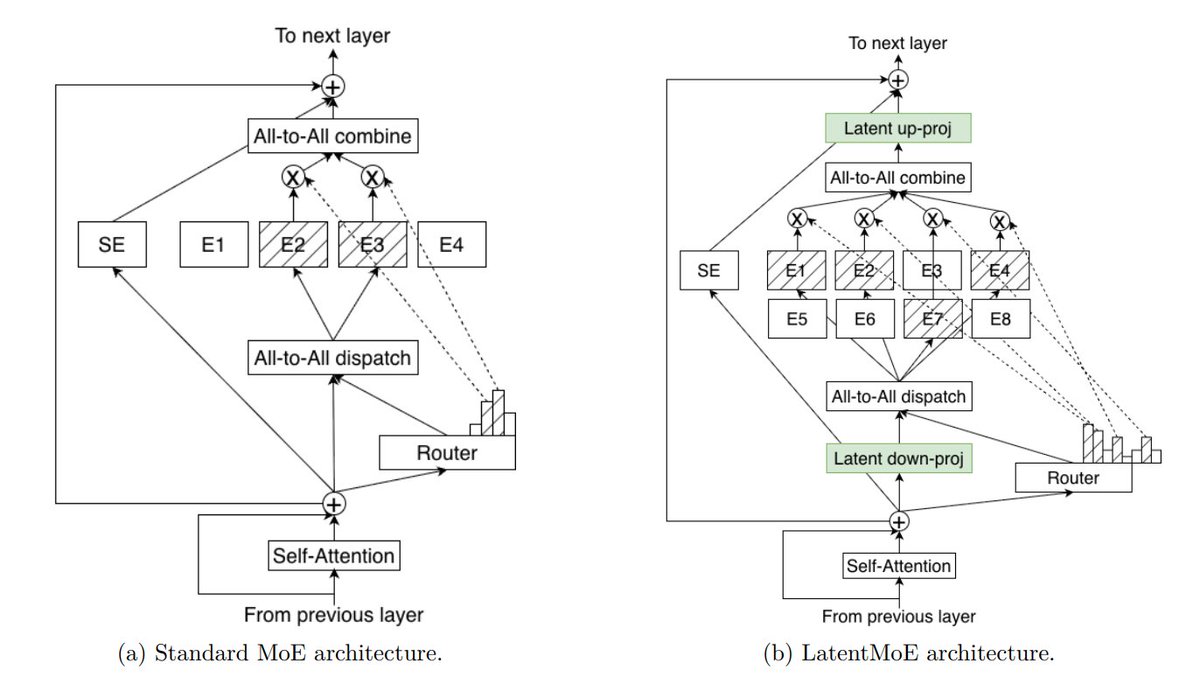
▪️ Hybrid architecture: Transformer + Mamba 2 layers for efficient long-context processing
▪️ Mixture-of-Experts (MoE) and LatentMoE on top of it to get cheaper experts
▪️ Multi-token prediction
▪️ NVFP4 precision = 4.75 bits used for inference and pre-training, allowing Nemotron pre-training dataset achieve up to 4× faster convergence than standard open web datasets.
This is all about one key idea – "Acceleration is intelligence"
Here is the tech stack explained and what the Nemotron Coalition is – NVIDIA has just announced that this alliance of leading players like Cursor, Mistral, Black Forest Labs, etc., is gathering to develop the Nemotron family of open models → turingpost.com/p/nemotroncoal…
A new paper from @ylecun and others – V-JEPA 2.1
It changes the recipe of V-JEPA so the model learns both:
• Global semantics – what is happening in the scene
• Dense spatio-temporal structure – where things are and how they move
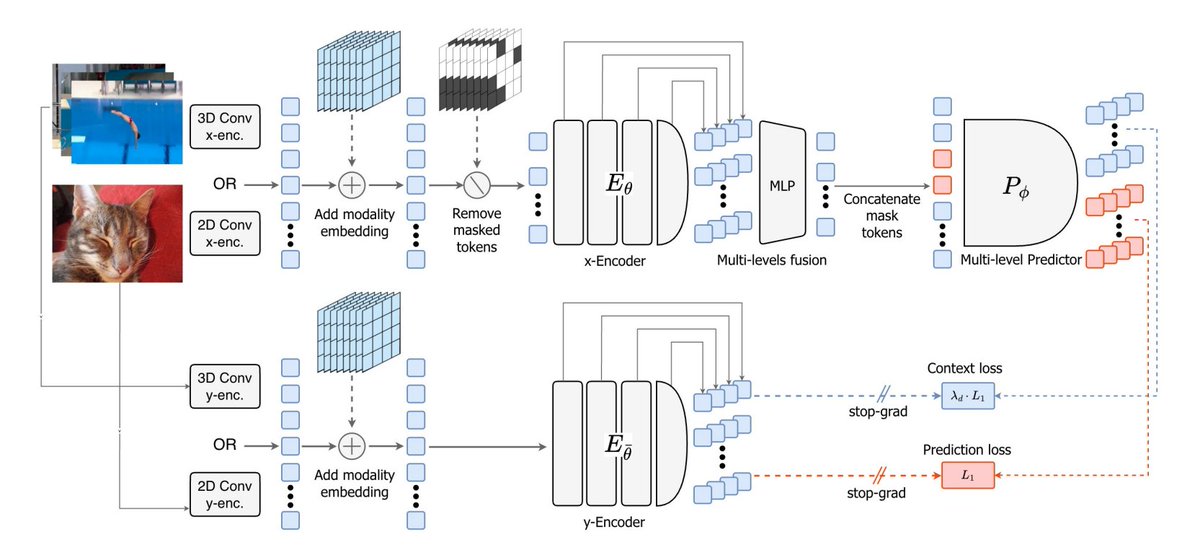
The idea is to supervise not just masked tokens but the visible ones too
There are 4 key ingredients for V-JEPA 2.1:
- Dense prediction loss on both masked and visible tokens
- Deep self-supervision across intermediate layers
- Modality-specific tokenizers (2D for images, 3D for videos) within a shared encoder
- Model + data scaling
The workflow turns into: masked image/video → encode visible tokens → predict latent representations for both masked and visible tokens → supervise at multiple layers
Here are the details:
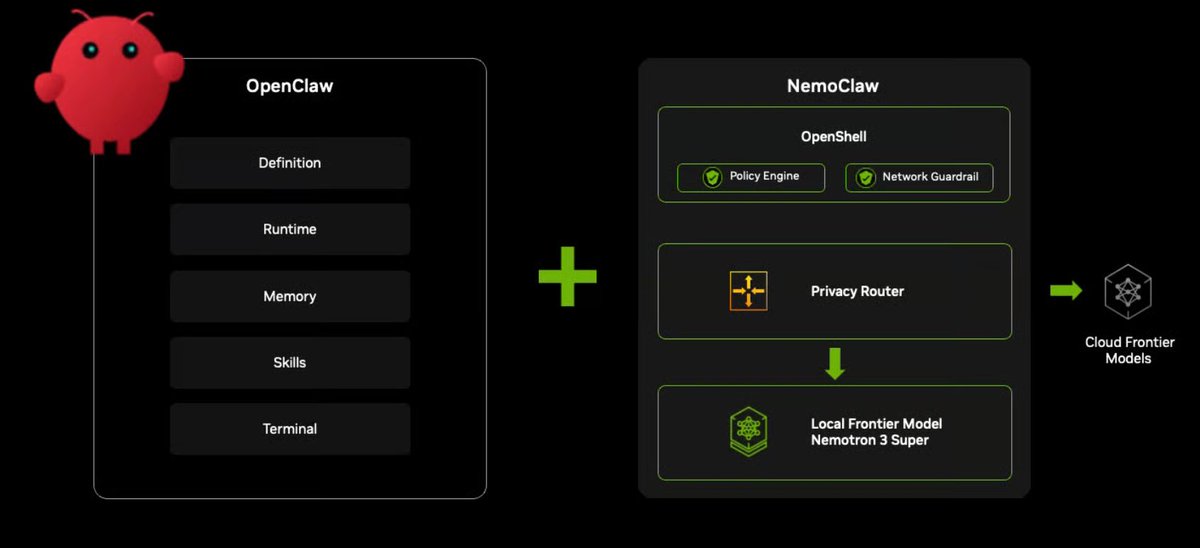
NemoClaw – NVIDIA’s contribution to the emerging OpenClaw ecosystem and one of the biggest announcements at NVIDIA GTC
It's a framework for long-running autonomous agents.
▪️ The idea: Install OpenClaw together with Nemotron models and OpenShell (NVIDIA’s new security runtime) in a single command.
NemoClaw gives agents a sandboxed execution environment that:
- runs OpenClaw inside a secure container – OpenShell
- enforces policies on network, filesystem, and processes
- routes all model calls via NVIDIA cloud
- provides CLI tools to manage agents
In other words, NVIDIA is no longer aiming only to power the model. It wants to sit under the agent itself.
OpenViking – filesystem memory for AI agents
It gives agents a structured navigable context system that:
- replaces flat vector storage with a filesystem (viking://)
- unifies memory, resources, and skills
- loads context in layers (L0/L1/L2) to save tokens
- retrieves info via directory-aware search (not flat RAG)
- makes retrieval traceable and debuggable
→ So it's a combination of structured navigation + semantic (embedding-based) retrieval
This approach delivers better retrieval accuracy, up to 80–96% lower token cost and self-improving memory over time.
@ylecun Follow @TheTuringPost for more.
Get deep analysis, guides & breakdowns of what AI is about now.
Join 100,000+ readers from top AI labs, VC funds & universities.: turingpost.com/subscribe
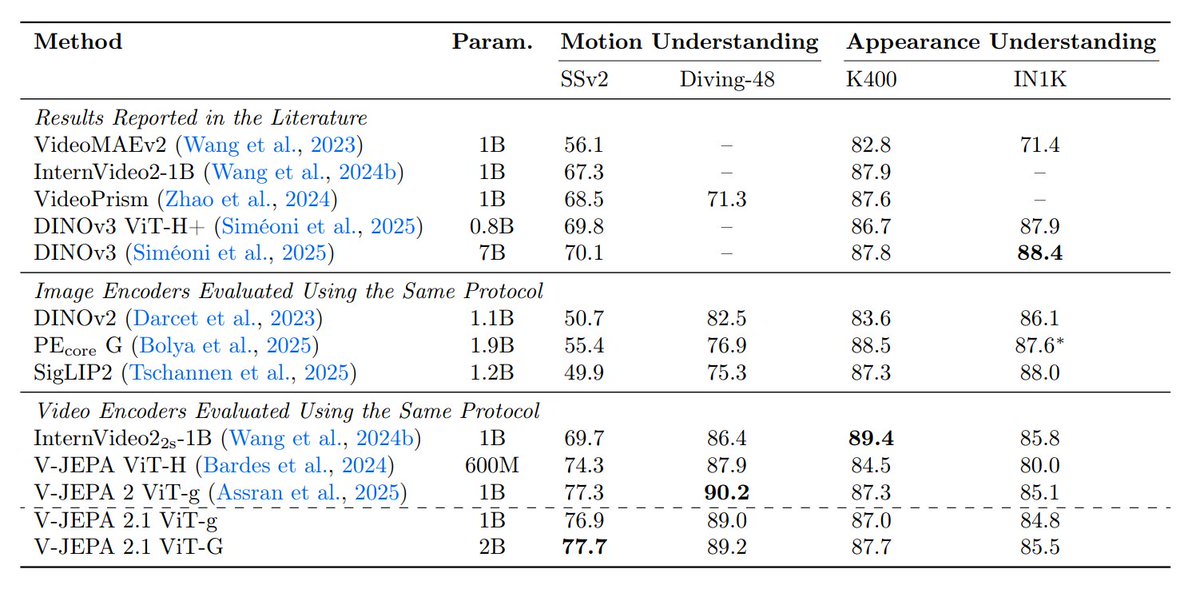
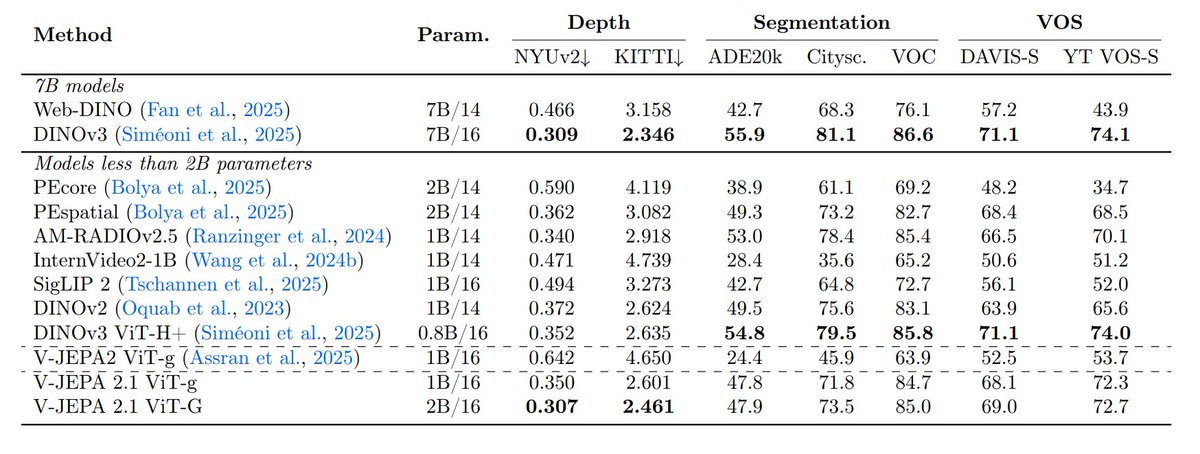
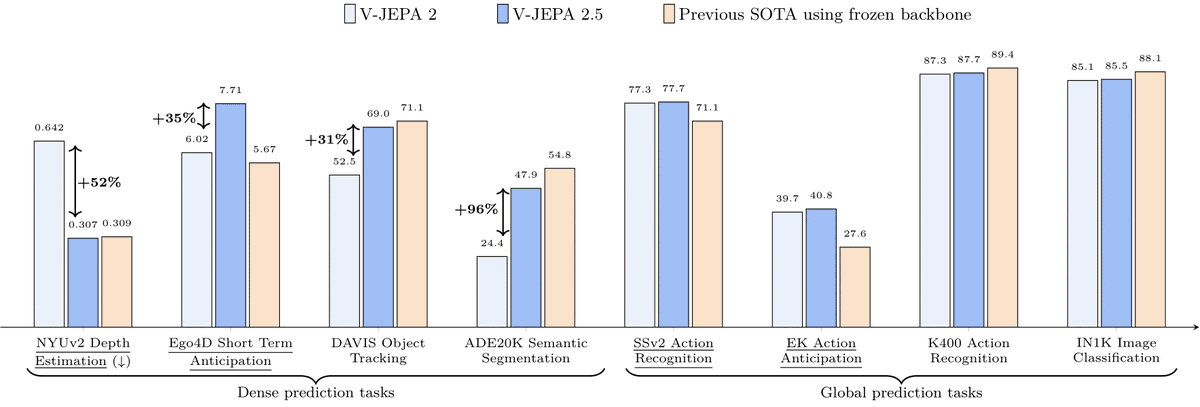
8. So V-JEPA 2.1 looks strong across both prediction and dense visual understanding (even with the encoder kept frozen)
Some of the results:
• +20% robot grasping success over V-JEPA 2 in zero-shot real-world manipulation
• 10× faster navigation planning, with 5.687 ATE on Tartan Drive
And new SOTA:
• 7.71 mAP on Ego4D short-term object interaction anticipation
• 40.8 Recall@5 on EPIC-KITCHENS action anticipation