WowDAO
1.1K posts


WowDAO
@WowDAOAI
The 1st Decentralized Autonomous Organization for the Open-source AI community. Bringing AI development on-chain to decentralize AI.
Delaware, United States Beigetreten Ekim 2022
127 Folgt4.2K Follower

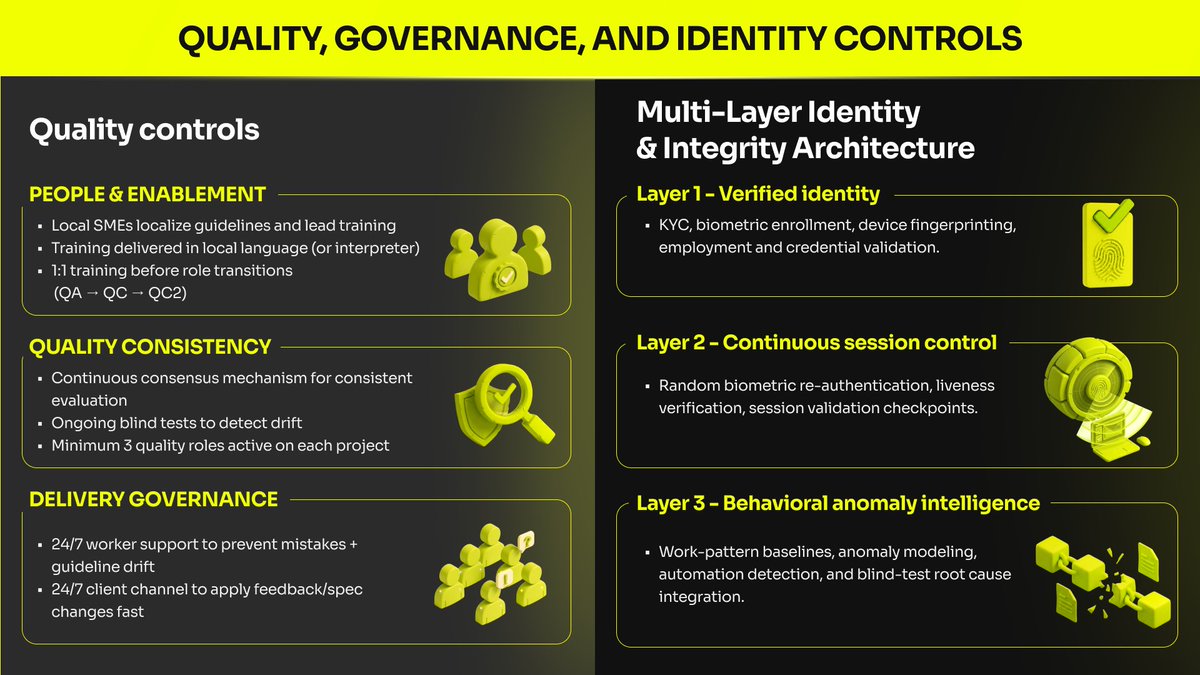
This is the standard we build for at AIxBlock:
governance you can point to, integrity you can verify, and delivery you can audit.
Because when data becomes the bottleneck, the real question isn’t “can you scale?”
It’s “can you prove it was done right?”
—
If you’re building AI with sensitive or multilingual data and need audit-ready delivery, contact AIxBlock.
#EnterpriseAI #DataGovernance #AICompliance #DataIntegrity #AIData
English
Reimbursement chatbots are easy to build.
Until an employee asks about a specific mileage claim for a recruiting dinner involving three different national IDs and a gift receipt.
That’s when the "simple" model usually starts to break.
We recently helped a Fortune 100 leader move past generic training data to build a truly production-ready reimbursement bot.
𝗧𝗵𝗲 "𝗛𝗶𝗴𝗵-𝗗𝗲𝗻𝘀𝗶𝘁𝘆" 𝗗𝗮𝘁𝗮 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝘆:
𝗕𝗲𝘆𝗼𝗻𝗱 𝗞𝗲𝘆𝘄𝗼𝗿𝗱𝘀: We sourced 6,000 utterances across specific domains like travel, office expenses, and client meetings.
𝗘𝗻𝘁𝗶𝘁𝘆 𝗢𝘃𝗲𝗿𝗹𝗼𝗮𝗱: Each utterance didn't just have one tag; we averaged 10–12 high-quality annotations per line (72,000 total).
𝗧𝗵𝗲 𝟵𝟳% 𝗕𝗮𝗿: High annotation depth is useless without accuracy. We held a 97%+ benchmark through rigorous QA audits.
𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗦𝗮𝗳𝗲𝘁𝘆: We ensured entity references (PII, finance IDs, health IDs) exceeded minimums to prevent pattern-matching errors in live flows.
If your entity coverage is inconsistent, your chatbot is just learning the wrong patterns.
You don't need more data. You need higher-density data.
If you’re building employee-facing bots and need spec-driven utterances that actually hold up in production, let’s talk.

English
AI is opening new doors for freelancers:
• Higher margins (AI speeds up output)
• New service categories (AI + human hybrid work)
• More clients than ever before
But the biggest opportunity isn’t just earning more.
It’s this:
👉 Being part of how AI is shaped.
Because every dataset, every label, every decision
becomes part of how models think.
At AIxBlock, we’re building for that future:
Where freelancers don’t just complete tasks - they help define intelligence.

English
Client: 𝗔 𝗴𝗹𝗼𝗯𝗮𝗹 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲 𝗹𝗲𝗮𝗱𝗲𝗿, 𝗙𝗼𝗿𝘁𝘂𝗻𝗲 𝟭𝟬𝟬
The client's team was building an 𝗲𝗺𝗽𝗹𝗼𝘆𝗲𝗲 𝗿𝗲𝗶𝗺𝗯𝘂𝗿𝘀𝗲𝗺𝗲𝗻𝘁 𝗰𝗵𝗮𝘁𝗯𝗼𝘁.
Goal: source + annotate utterances that are realistic, demographically representative, and usable for model training.
The problem: reimbursement language looks simple until you add enterprise requirements:
Minimum entity references across PII + finance IDs + national/health IDs
Multiple expense domains (mileage, office expense, recruiting, client meetings, travel, gifts, etc.)
High annotation depth (𝟭𝟬–𝟭𝟮 𝗮𝗻𝗻𝗼𝘁𝗮𝘁𝗶𝗼𝗻𝘀 𝗽𝗲𝗿 𝘂𝘁𝘁𝗲𝗿𝗮𝗻𝗰𝗲)
How AIxBlock supported the delivery (simple plan):
1. Source targeted utterances to spec
2. Transcribe + label + tag metadata per utterance
3. Run QA audits + reviews to hold benchmarks
Result: 𝟲,𝟬𝟬𝟬 𝘂𝘁𝘁𝗲𝗿𝗮𝗻𝗰𝗲𝘀 (3,000 sales + 3,000 expense) with 𝟭𝟬–𝟭𝟮 𝗵𝗶𝗴𝗵-𝗾𝘂𝗮𝗹𝗶𝘁𝘆 𝗮𝗻𝗻𝗼𝘁𝗮𝘁𝗶𝗼𝗻𝘀 𝗲𝗮𝗰𝗵 (𝟲𝟬,𝟬𝟬𝟬–𝟳𝟮,𝟬𝟬𝟬 𝘁𝗼𝘁𝗮𝗹 𝗮𝗻𝗻𝗼𝘁𝗮𝘁𝗶𝗼𝗻𝘀), entity references exceeded minimums, and 𝟵𝟳%+ 𝗮𝗰𝗰𝘂𝗿𝗮𝗰𝘆 in quality audits.
Stakes: if entity coverage is inconsistent, chatbots learn the wrong patterns — and reimbursement flows break in production.
If you’re building employee-facing chatbots and need spec-driven utterance + annotation at enterprise QA levels, contact AIxBlock.
#EnterpriseAI #NLP #DataAnnotation #Chatbots #AIData




English
Most AI training data budgets do not break at procurement. They break when rework starts.
Weak guidelines, late SME fixes, poor eval sets, and slow legal review are where costs pile up.
That is why choosing a training data partner for AI models matters.
aixblock.io/blogs/training…
#AIxBlock #EnterpriseAI #AITrainingData #LLMOps
English
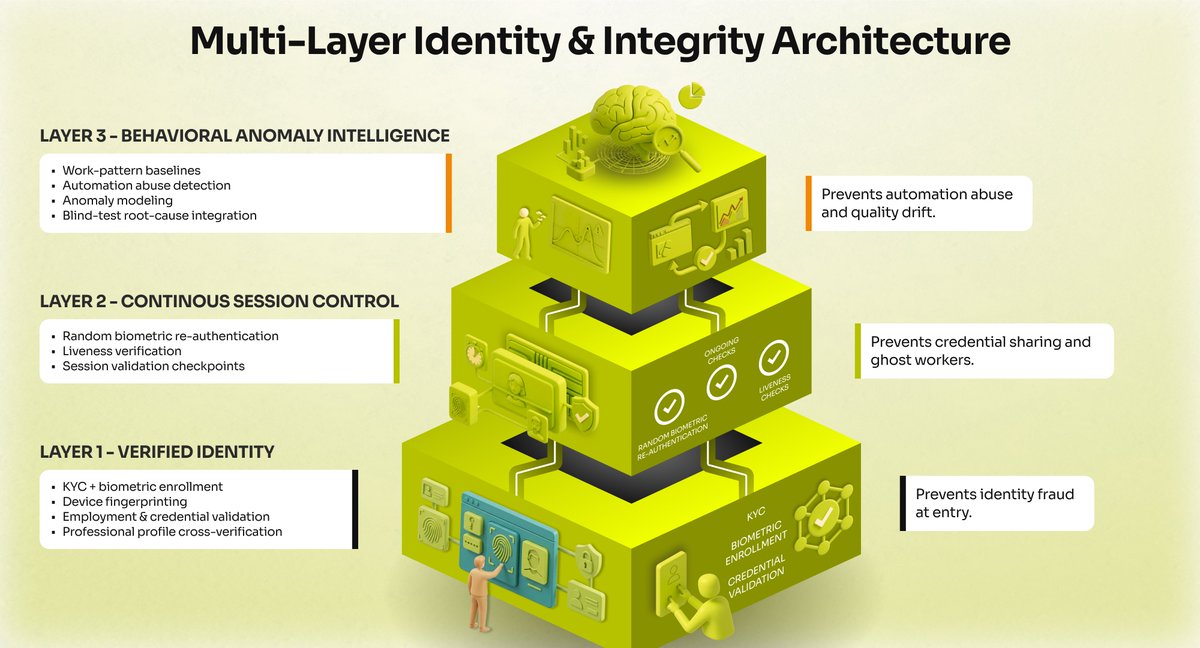
𝗢𝗻𝗲-𝘁𝗶𝗺𝗲 𝘃𝗲𝗿𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝘁𝗵𝗲 𝗯𝗶𝗴𝗴𝗲𝘀𝘁 𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆 𝗵𝗼𝗹𝗲 𝗶𝗻 𝗔𝗜 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁.
The industry standard for data annotation is alarmingly fragile: check credentials once at signup, and blindly trust that user from that point forward.
This gap between the day-one test and the day-ninety audit is exactly where fraud thrives.
Remote contributors work with zero oversight, meaning nothing stops them from sharing credentials, delegating tasks, or building AI agents to do the work for them.
We realized that for frontier model development, trust must be continuous.
AIxBlock approaches this entirely differently:
↳𝗕𝗶𝗼𝗺𝗲𝘁𝗿𝗶𝗰 𝗰𝗵𝗲𝗰𝗸𝘀 before every single session, not just at signup.
↳𝗗𝗲𝘃𝗶𝗰𝗲 𝗳𝗶𝗻𝗴𝗲𝗿𝗽𝗿𝗶𝗻𝘁𝗶𝗻𝗴 to lock down the hardware.
↳𝗕𝗲𝗵𝗮𝘃𝗶𝗼𝗿𝗮𝗹 𝗮𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀 to catch unnatural, automated work patterns in real-time.
The era of trusting a self-declaration is over.
English
𝗖𝗿𝗼𝘄𝗱𝘀 𝘀𝗰𝗮𝗹𝗲 𝗱𝗮𝘁𝗮. 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗽𝗿𝗼𝘁𝗲𝗰𝘁𝘀 𝗺𝗲𝗮𝗻𝗶𝗻𝗴.
In large AI data projects, the biggest hidden risk isn’t bad actors or careless work.
𝗜𝘁’𝘀 𝗴𝘂𝗲𝘀𝘀𝘄𝗼𝗿𝗸 𝗮𝘁 𝘀𝗰𝗮𝗹𝗲.
When contributors face tasks that require domain judgment but lack the context to make it, they do what humans naturally do: 𝗶𝗻𝗳𝗲𝗿 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀 𝗮𝗻𝗱 𝗺𝗮𝗸𝗲 𝗲𝗱𝘂𝗰𝗮𝘁𝗲𝗱 𝗴𝘂𝗲𝘀𝘀𝗲𝘀.
At small scale, that’s manageable.
At large scale, those guesses quietly become 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘀𝗶𝗴𝗻𝗮𝗹𝘀.
Research on crowdsourced labeling shows that when tasks require deeper domain knowledge or ambiguous interpretation, non-expert contributors can introduce systematic bias.
And once those patterns enter a dataset, the model doesn’t just learn the task.
It learns the 𝗯𝗶𝗮𝘀 𝗼𝗳 𝘂𝗻𝗰𝗲𝗿𝘁𝗮𝗶𝗻𝘁𝘆.
Models cannot distinguish whether a label came from confidence or guesswork.
They simply learn the pattern.
Final QA can catch defects.
It cannot fully prevent systematic misunderstanding, labeling drift, or unresolved ambiguity at scale.
That is why data quality has to be designed into the workflow from the start.
At AIxBlock, we think about this in 3 layers:
𝟭. 𝗣𝗲𝗼𝗽𝗹𝗲 𝗮𝗻𝗱 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴
Guidelines need to be localized, explained clearly, and calibrated to the actual task. Contributors should be trained on decision boundaries, not just definitions.
𝟮. 𝗩𝗲𝗿𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻
Workers should be screened on real task samples, then measured continuously against benchmark items, blind checks, and audit workflows to catch drift early.
𝟯. 𝗚𝗼𝘃𝗲𝗿𝗻𝗮𝗻𝗰𝗲
Long-running projects need active quality roles, fast feedback loops, and a clear process for updating specs when ambiguity appears.
The goal is not to replace the crowd.
It is to structure the crowd.
Crowds provide scale and coverage.
Subject-matter experts provide interpretation, calibration, and ground truth.
Quality systems make both usable at production level.
Reliable AI data does not come from volume alone.
It comes from turning human judgment into something consistent, reviewable, and repeatable.
That is what makes datasets trustworthy, especially when the task goes beyond simple classification.
How does your team prevent labeling drift and context guesswork in large-scale data workflows?




English
In case you missed it - AIxBlock also offers an OTS Audio Library for Voice AI training.
Training Voice AI without real conversations? That’s the fastest way to fail in production.
Most ASR (Automatic Speech Recognition) models are trained on clean, studio-quality audio. But real-world call center conversations include background noise, accents, interruptions, and cross-talk.
That’s why we built the AIxBlock OTS Audio Library.
🔹 Real Call Center Audio at Scale
Hundreds of thousands of hours of real customer–agent conversations.
🔹 Multilingual Coverage
US English, Indian English, Philippine English, plus multiple Indian languages.
🔹 Production-Ready ASR Training Data
Licensed datasets designed for Voice AI, Speech Recognition, and Conversational AI development.
🔹 Real-World Conditions
Noise, overlapping speech, and natural accents - the data your speech AI models actually need.
If you're building Voice AI, AI call agents, speech recognition systems, or conversational AI platforms, training data quality is everything.
Explore the OTS Audio Library: aixblock.io/products/ots-a…
#VoiceAI #SpeechRecognition #ASR #ConversationalAI #AIInfrastructure #MachineLearning #AIData #CallCenterAI

English
𝗡𝗼𝘁 𝗮𝗹𝗹 𝗵𝘂𝗺𝗮𝗻 𝗶𝗻𝗽𝘂𝘁 𝗶𝘀 𝗲𝗾𝘂𝗮𝗹 - 𝘀𝗺𝗮𝗿𝘁 𝗔𝗜 𝘁𝗲𝗮𝗺𝘀 𝗸𝗻𝗼𝘄 𝘄𝗵𝗲𝗻 𝘁𝗼 𝘂𝘀𝗲 𝘄𝗵𝗶𝗰𝗵 𝘁𝘆𝗽𝗲.
In hybrid intelligence systems, it’s not about more input, it’s about the right input at the right time. Research shows crowd-sourced labeling can reach expert-level quality when structured properly - but only if the task fits the model.
𝗪𝗵𝗲𝗻 𝗰𝗿𝗼𝘄𝗱 𝗶𝗻𝗽𝘂𝘁 𝘀𝗵𝗶𝗻𝗲𝘀
Clear, objective, high-volume tasks (tagging categories, basic classification)
Well-designed workflows with quality checks (label aggregation, confidence weighting)
Scalable early-stage data for bootstrapping models or surfacing patterns
Crowds work best when nuance isn’t critical and noise can be managed with smart aggregation and automation.
𝗪𝗵𝗲𝗻 𝗱𝗼𝗺𝗮𝗶𝗻 𝗲𝘅𝗽𝗲𝗿𝘁𝘀 𝗮𝗿𝗲 𝗶𝗻𝗱𝗶𝘀𝗽𝗲𝗻𝘀𝗮𝗯𝗹𝗲
High-stakes, context-rich decisions (legal, medical, ethical)
Ambiguous edge cases where generic labels fail
Model evaluation and grounding to prevent shortcuts that appear correct statistically but fail in reality
Experts provide the context and judgment machines and crowds cannot infer.
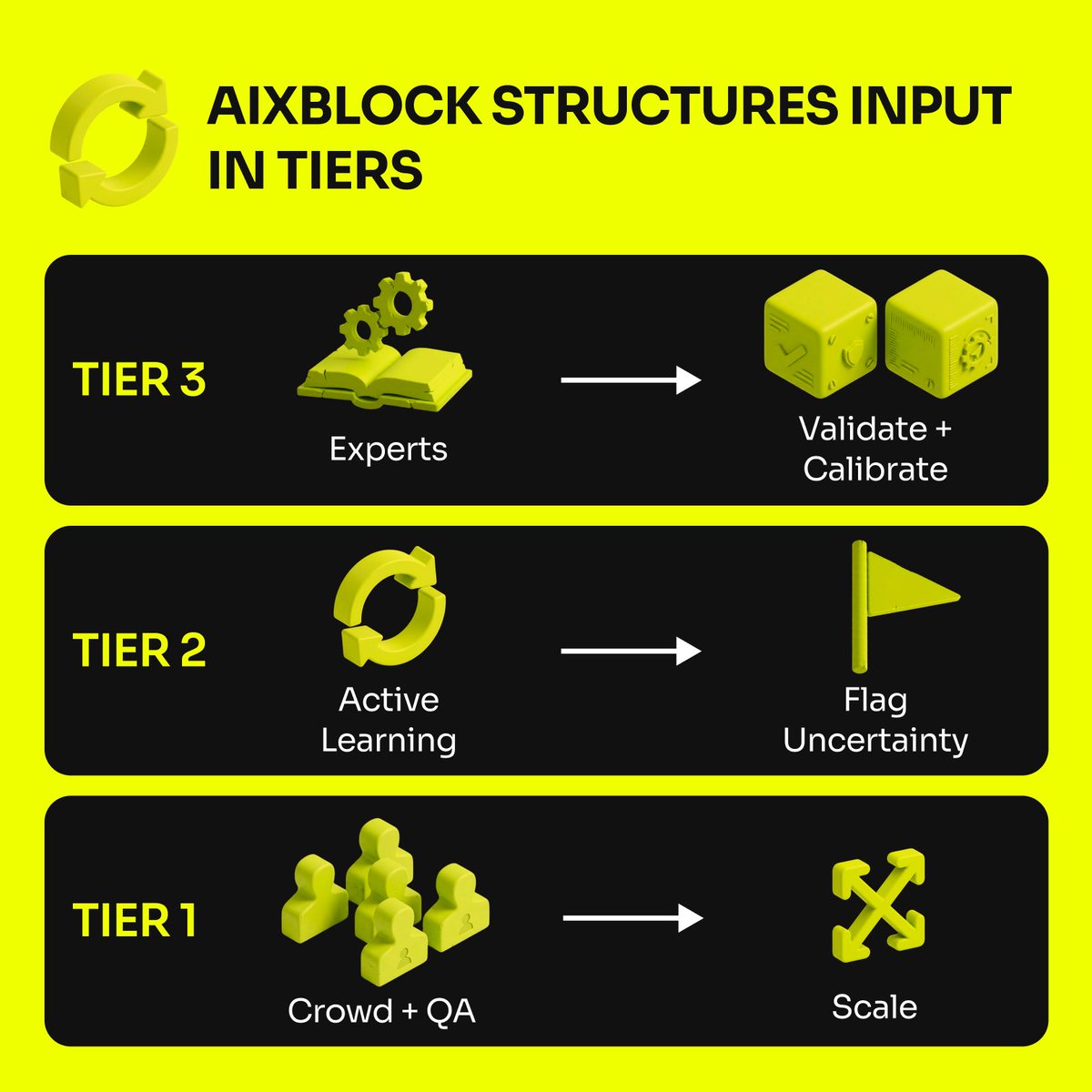
🔄 𝗧𝗵𝗲 𝗽𝗼𝘄𝗲𝗿 𝗶𝘀 𝗶𝗻 𝗼𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻
AIxBlock structures input in tiers:
1. Crowd + automated quality checks → scale and coverage
2. Active learning loops → uncertain or low-confidence items flagged for expert review
3. Domain expert calibration → anchors AI in real-world reasoning
This layered approach turns raw data into trustworthy intelligence, not just bigger datasets.
Crowds = scale. Experts = meaning.
AIxBlock combines both so your models learn fast without losing fidelity.
In AI, trust isn’t optional - it’s engineered.



English
Enterprise LLMs often fail for a simpler reason than teams expect: weak conversation data.
Bad 𝗱𝗶𝗮𝗹𝗼𝗴𝘂𝗲 𝗮𝗻𝗻𝗼𝘁𝗮𝘁𝗶𝗼𝗻 𝘀𝗲𝗿𝘃𝗶𝗰𝗲𝘀 lead to lost speaker roles, unclear state changes, missed compliance signals, and generic labels that flatten domain nuance.
5 gaps here: aixblock.io/blogs/dialogue…
#AIxBlock #EnterpriseLLM #ConversationalAI #LLMOps
English
@WowAI_Official Focusing on messy real-world conversations is a smart approach.
Speech models tend to perform well on clean recordings but struggle once they encounter interruptions, accents, and background noise.
English


@AIxBlock This highlights something interesting in AI development timelines.
Model improvements are happening faster every quarter, but data pipelines still move at traditional research speed.
Closing that gap is probably one of the biggest competitive advantages right now.
English
8 months.
That was the "safe" estimate to collect 18,000 hours of multilingual speech data.
But in AI, 8 months is an eternity.
If you wait that long to fix model hallucinations, your competitors have already moved on.
We recently helped a Fortune 100 team bridge this gap.
𝗧𝗵𝗲 "𝟭𝟲-𝗪𝗲𝗲𝗸" 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸:
𝗟𝗼𝗰𝗮𝗹𝗲 𝗣𝗿𝗲𝗰𝗶𝘀𝗶𝗼𝗻: We didn't just target "Spanish." We mapped es-MX vs. es-ES to avoid model regression.
𝗖𝗼𝗻𝘁𝗲𝘅𝘁𝘂𝗮𝗹 𝗚𝘂𝗮𝗿𝗱𝗿𝗮𝗶𝗹𝘀: Every 6-30s utterance was reviewed by native linguists for coherence, not just keywords.
𝗗𝗼𝗺𝗮𝗶𝗻 𝗗𝗲𝗻𝘀𝗶𝘁𝘆: We focused on the "messy" audio—sales calls and tech support—where models actually fail.
Planned for 8 months. Delivered in 16 weeks. Audit-ready from day one.
If you're running multi-locale speech programs and need to move faster without the data slipping, let’s talk.

English
Expert Tasks: Same Risk, Better Disguised
For general tasks, it’s ghost workers.
For expert tasks, it’s delegation.
(see more)
In medical, legal, and technical annotation, the common failure mode isn’t fake credentials.
It’s this:
• the credentialed person qualifies
• the work gets delegated to junior staff or assistants
→ same root cause: one-time verification inside a continuous-work relationship.
AIxBlock is built to keep “expert work” tied to the verified expert across time:
↳ verified identity + credential validation at entry
↳ session controls to prevent quiet handoffs
↳ behavioral anomaly intelligence to flag sudden pattern shifts inconsistent with the verified expert’s baseline
If you’re buying expert data and need defensible provenance, contact AIxBlock—we’ll walk you through how we keep expert identity and behavior bound to every session.
What matters more in your diligence: the credential at signup, or proof of expert presence throughout delivery?




English
A recent study on 𝗵𝘂𝗺𝗮𝗻-𝗔𝗜 𝗰𝗼𝗹𝗹𝗮𝗯𝗼𝗿𝗮𝘁𝗶𝘃𝗲 𝗱𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝘀𝘆𝘀𝘁𝗲𝗺𝘀 in retail from Science Direct tested something most AI deployments skip: structured human oversight.
The framework wasn’t just a model.
It was a system architecture:
• Reinforcement learning for optimization
• Fuzzy logic to stabilize uncertain outputs
• An explanation panel showing feature contributions and alternative scenarios
• A real-time override interface for managers
• Bias monitoring and fairness checks
The results over six months of retail operations:
• +15% revenue vs rule-based systems
• 20% faster decisions
• 10.5% fewer stockouts
• 88% staff satisfaction
But the most interesting insight wasn’t the performance.
It was 𝘄𝗵𝘆 𝗺𝗮𝗻𝗮𝗴𝗲𝗿𝘀 𝘁𝗿𝘂𝘀𝘁𝗲𝗱 𝘁𝗵𝗲 𝘀𝘆𝘀𝘁𝗲𝗺.
The AI didn’t just output decisions.
It showed why, suggested alternatives, and allowed real-time overrides.
That transparency turned the model from a black box into a decision partner.
This mirrors what we see in enterprise AI projects:
In practice, the gap isn’t model capability.
It’s whether human expertise is 𝗰𝗮𝗽𝘁𝘂𝗿𝗲𝗱 𝗶𝗻 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱 𝘄𝗮𝘆𝘀 𝘁𝗵𝗮𝘁 𝗺𝗮𝗸𝗲 𝘁𝗵𝗲 𝘀𝘆𝘀𝘁𝗲𝗺 𝗿𝗲𝗹𝗶𝗮𝗯𝗹𝗲 𝗼𝘃𝗲𝗿 𝘁𝗶𝗺𝗲.
This is where AIxBlock is relevant:
• We help build 𝗵𝗶𝗴𝗵-𝗾𝘂𝗮𝗹𝗶𝘁𝘆 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗱𝗮𝘁𝗮
• Run 𝗲𝘅𝗽𝗲𝗿𝘁-𝗹𝗲𝗱 𝗮𝗻𝗻𝗼𝘁𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝘃𝗮𝗹𝗶𝗱𝗮𝘁𝗶𝗼𝗻
• Strengthen model reliability with 𝗵𝘂𝗺𝗮𝗻 𝗿𝗲𝘃𝗶𝗲𝘄 𝗹𝗼𝗼𝗽𝘀
Better AI outcomes depend on data quality, expert validation, and structured human feedback - not just the model itself.
Because the real advantage isn’t building AI systems.
It’s building AI systems that learn from human expertise at scale.
Curious how your team ensures human expertise informs AI decisions today?




English
@AIxBlock The AI industry talks a lot about model evaluation, but much less about data supply chain integrity.
If identity, process, and environment aren’t controlled, the dataset becomes a black box.
That’s risky when the dataset is literally shaping the model’s behavior.
English
𝗜𝗳 𝘆𝗼𝘂 𝗿𝗲𝗹𝘆 𝗼𝗻 𝗤𝗔 𝘁𝗼 𝗰𝗮𝘁𝗰𝗵 𝗯𝗮𝗱 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗱𝗮𝘁𝗮, 𝘆𝗼𝘂𝗿 𝗺𝗼𝗱𝗲𝗹 𝗶𝘀 𝗮𝗹𝗿𝗲𝗮𝗱𝘆 𝗰𝗼𝗿𝗿𝘂𝗽𝘁𝗲𝗱.
The AI data annotation industry is built on a trust model that doesn’t scale.
Here’s the standard industry flow
• contributor passes a qualification test
• gets access to paid tasks
• platform assumes the same person does all future wor
• quality spot-checks catch issues weeks later
→ the gap between “pass” and “audit” is where fraud thrives.
Because nothing stops a qualified contributor from:
• Hiring someone cheaper to do the actual work
• Sharing credentials with multiple people
• Delegating tasks to unqualified assistants
• Built an “AI agent” to work for them
Most vendors treat this as an acceptable loss rate:
“We’ll catch low performers through quality metrics and remove them.”
↳ By then, you’ve already paid for corrupted data and may have trained on it.
AIxBlock platform is built to close the gap with continuous verification during work
↳ biometric re-authentication in-session
↳ liveness verification
↳ device fingerprinting to reduce credential transfer
↳ behavioral anomaly intelligence to detect automation abuse + drift
→ control the work, not just the output.
If you’re evaluating vendors for high-stakes AI, contact AIxBlock - we’ll walk your team through how these controls run end-to-end in production workflows.




English
Your ASR worked in testing. Then live calls exposed the real problem.
Bad production performance often comes from weak speech training data for ASR. Not enough real-world coverage, poor speech data collection services, too much channel noise, and hidden accent skew.
Read the blog:
🔗aixblock.io/blogs/speech-t…
#AIxBlock #ASR #VoiceAI #SpeechRecognition
English
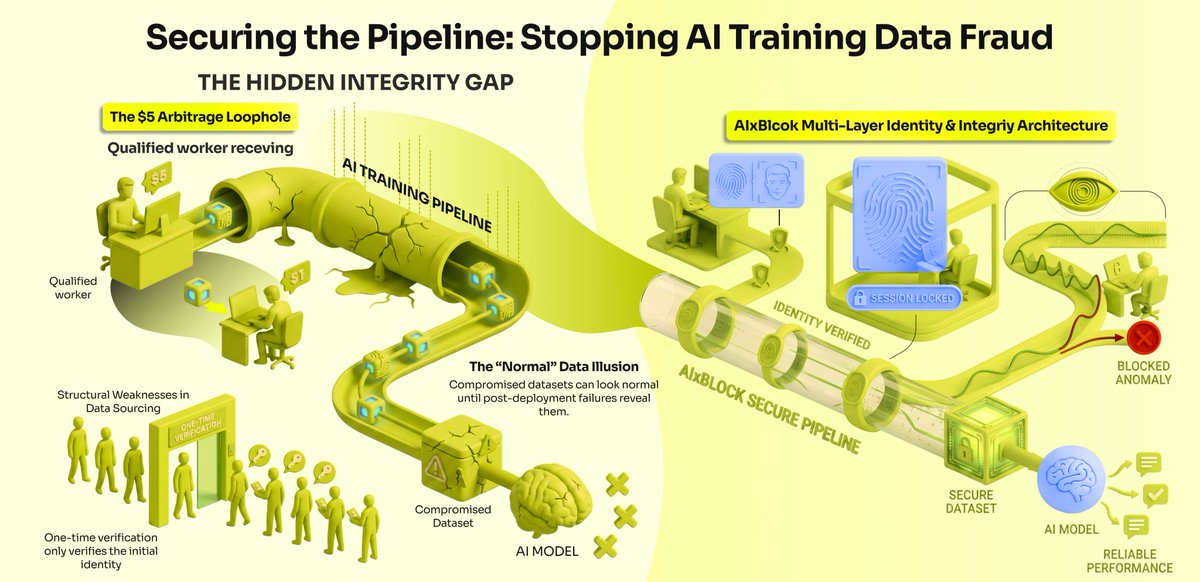
The AI training data industry has a structural trust gap: the person who passes qualification isn’t always the person doing the work, which quietly corrupts training data.
So instead of relying on after-the-fact QA, we’re now offering continuous identity and session verification to keep the right contributor behind every label.
English
𝗪𝗲 𝗮𝗿𝗲 𝗛𝗶𝗿𝗶𝗻𝗴: 𝗟𝗕𝟬𝟭_ 𝗘𝗻𝗴𝗹𝗶𝘀𝗵 𝗖𝗼𝗱𝗲-𝘀𝘄𝗶𝘁𝗰𝗵𝗶𝗻𝗴 𝗥𝗲𝗰𝗼𝗿𝗱𝗶𝗻𝗴 𝗣𝗿𝗼𝗷𝗲𝗰𝘁
We are looking for native speakers of Danish, Norwegian, Chinese, Korean, Arabic, or Thai who are fluent in English to participate in a unique recording project.
𝗠𝗼𝗿𝗲 𝗱𝗲𝘁𝗮𝗶𝗹𝘀 𝗯𝗲𝗹𝗼𝘄 👇
#AIJobs #DataAnnotation #MultilingualAI #RemoteWork #AIxBlock




English
Deadlines don’t kill AI projects.
𝗥𝗲𝘄𝗼𝗿𝗸 𝗱𝗼𝗲𝘀.
And multilingual data is where rework hides.
One locale mismatch.
One inconsistent guideline.
One “close enough” transcript pass.
And suddenly you’re paying twice - plus delaying launch.
𝗨𝘀𝗲 𝗰𝗮𝘀𝗲 #𝟯 — 𝗨𝘁𝘁𝗲𝗿 𝟮.𝟬 (𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗺𝘂𝗹𝘁𝗶𝗹𝗶𝗻𝗴𝘂𝗮𝗹 𝘀𝗽𝗲𝗲𝗰𝗵 𝗮𝘁 𝘀𝗰𝗮𝗹𝗲)
Client: a 𝗙𝗼𝗿𝘁𝘂𝗻𝗲 𝟭𝟬𝟬 global enterprise software leader.
They needed multilingual speech training data across 𝟵 𝗹𝗼𝗰𝗮𝗹𝗲𝘀/𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 for real business conversations:
customer support • sales calls • product demos • technical support • feedback
The plan said 𝟴 𝗺𝗼𝗻𝘁𝗵𝘀.
We delivered in 𝟭𝟲 𝘄𝗲𝗲𝗸𝘀.
𝗛𝗮𝗹𝗳 𝘁𝗵𝗲 𝘁𝗶𝗺𝗲 — without sacrificing linguistic accuracy.
How we de-risked delivery:
1. Locked scope early
Locale + UNI code mapping (zh-TW, pl-PL, nl-NL, fr-CA, es-MX, tr-TR)
2. Ran collection by locale
Targeting 𝟭,𝟱𝟬𝟬–𝟮,𝟬𝟬𝟬 𝗵𝗼𝘂𝗿𝘀 𝗽𝗲𝗿 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲
3. Kept utterances consistent
Short clips: 6–30s
4. Held transcription to enterprise standards
Verbatim + coherent across domains
5. Used skilled linguist review
Contextual accuracy, not “literal but wrong”
6. Delivered across production domains
Support/sales/demo/tech support—consistently
7. De-risked timeline with a clear execution plan
So quality didn’t slip under pressure
Result: planned for 𝟴 𝗺𝗼𝗻𝘁𝗵𝘀 (𝟯𝟮 𝘄𝗲𝗲𝗸𝘀) → delivered in 𝟭𝟲 𝘄𝗲𝗲𝗸𝘀.
—
If you’re running multi-locale speech programs and want an 𝗮𝘂𝗱𝗶𝘁-𝗿𝗲𝗮𝗱𝘆 𝗱𝗲𝗹𝗶𝘃𝗲𝗿𝘆 𝗽𝗹𝗮𝗻, contact 𝗔𝗜𝘅𝗕𝗹𝗼𝗰𝗸.
#SpeechAI #EnterpriseAI #MLOps #Multilingual #DataEngineering #AIxBlock




English
Copying and pasting your data strategy across borders doesn't work.
When you expand from the US to the UK or India, you aren't just changing the language.
You are expanding your "Spec Surface Area".
We recently helped a Fortune 10 cloud leader map this territory across 7 distinct markets.
𝗧𝗵𝗲 𝟯 𝗗𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝘀 𝗼𝗳 𝗚𝗹𝗼𝗯𝗮𝗹 𝗗𝗮𝘁𝗮:
𝟭. 𝗧𝗵𝗲 𝗥𝗲𝗴𝘂𝗹𝗮𝘁𝗼𝗿𝘆 𝗦𝘂𝗿𝗳𝗮𝗰𝗲: It’s not enough to label "ID Numbers." You must validate specific formats—like the 10-digit NHS number in the UK vs. the 12-digit AADHAR in India.
𝟮. 𝗧𝗵𝗲 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗦𝘂𝗿𝗳𝗮𝗰𝗲: Natural language is messy, but engineering pipelines are rigid. We delivered every chat in valid JSON, formatted specifically for Amazon’s Ace Editor.
𝟯. 𝗧𝗵𝗲 𝗖𝘂𝗹𝘁𝘂𝗿𝗮𝗹 𝗦𝘂𝗿𝗳𝗮𝗰𝗲: We used in-country staff to ensure the syntax was natural, not just a translated script.
The result was 1,790 documents and 537,000 tokens that were audit-ready on day one.
Don't just translate your data. Engineer it to the local spec.
If you need help navigating complex PII rules across multiple markets, let’s talk.

English