Angehefteter Tweet

Lack of diversity in your LLM generation?
(also noted by Artificial Hivemind, best paper @NeurIPSConf)
Time to bring your base model back!
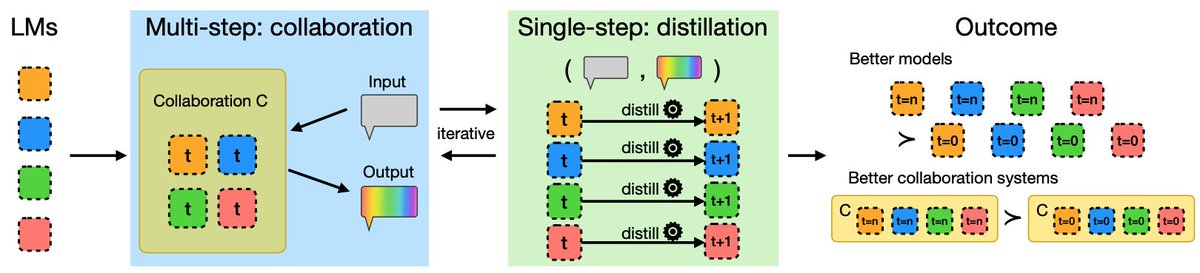
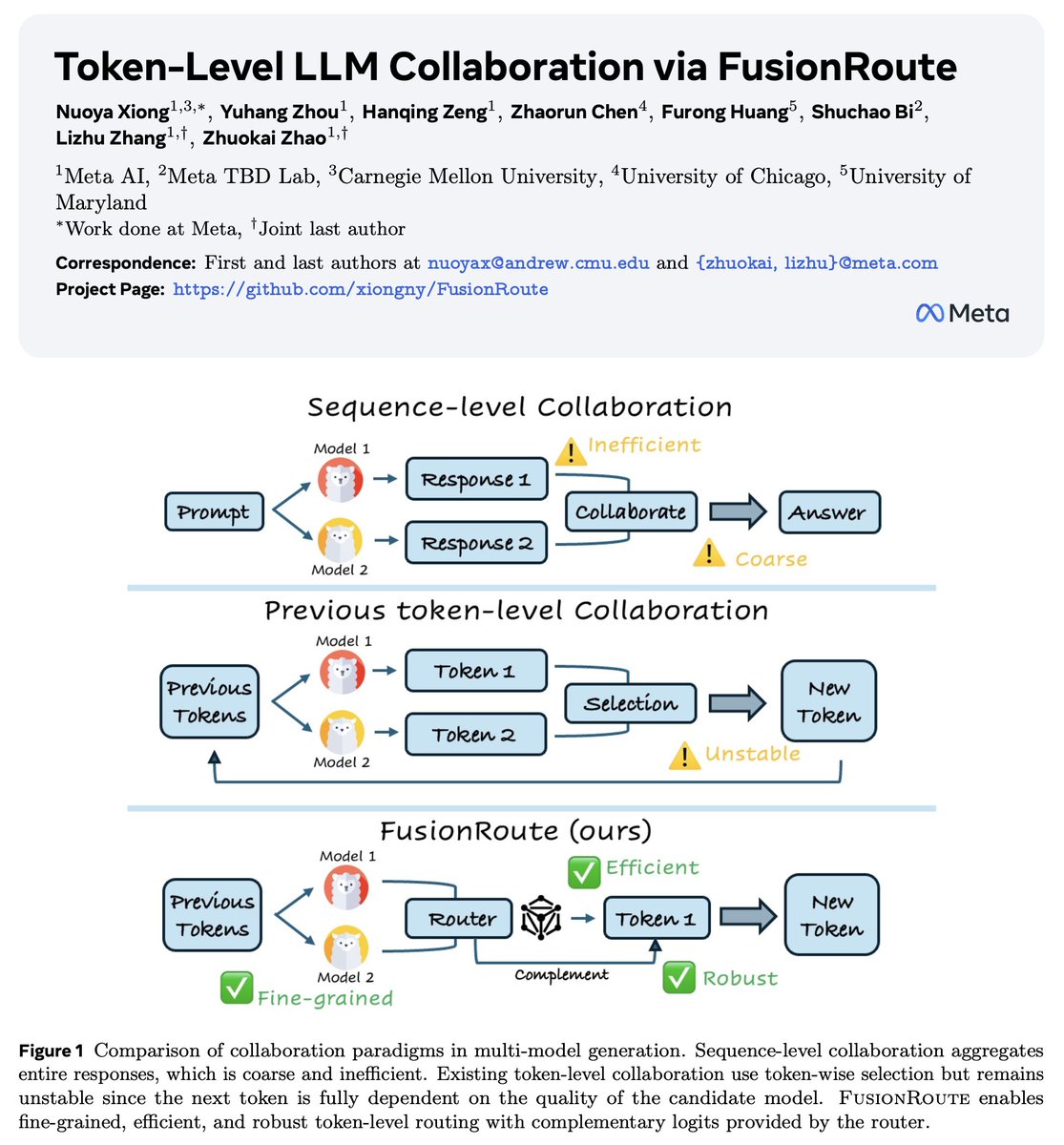
An inference-time, token-level collaboration between a base and an aligned model can optimize and control diversity and quality!

English