
a1exus
9.8K posts

a1exus
@a1exus
#DEVOP (#RHCE #RHCSA) / #PENTESTER aka AI w/ VPN
New York City Beigetreten Temmuz 2008
3K Folgt840 Follower

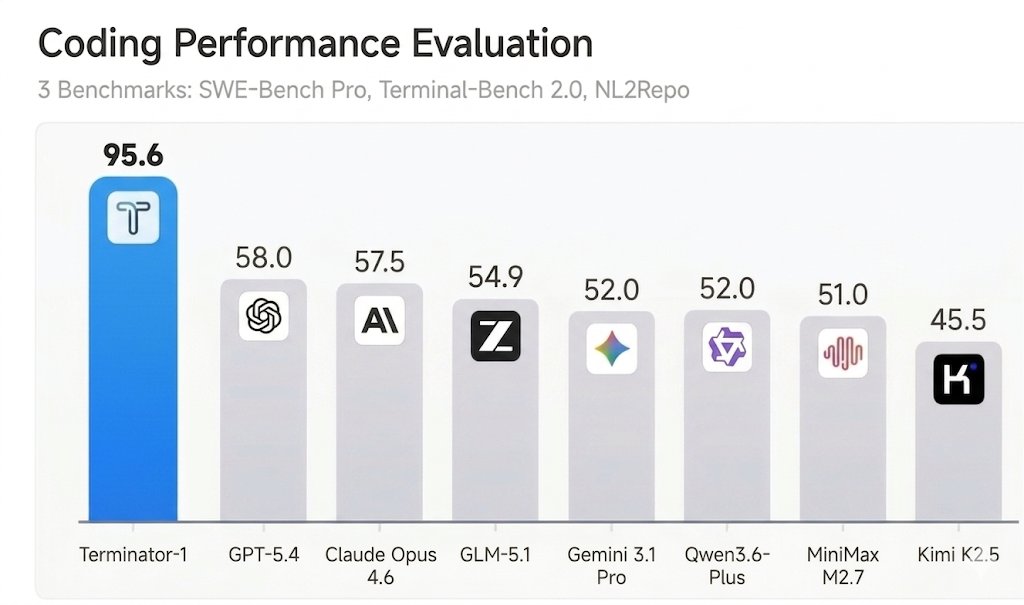
An agent that beats Claude Mythos on Terminal Bench and SWE-bench Verified?
🎉We are excited to share Terminator-1, our newest agent that achieved 95+% on SWE-bench Verified and Terminal-Bench with @MogicianTony!
We show that besides model capabilities, well-designed harness could actually boost the accuracy by 3x in coding tasks.
Well if you really wanted you could get 100% accuracy without solving a single task.
The actual finding is that most AI benchmarks can be easily reward-hacked with simple exploits. Read more about the same 7 design flaws that almost every evaluation has ⬇️
Hao Wang@MogicianTony
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
English
a1exus retweetet

a1exus retweetet
>Close your laptop on Friday
>Leave $2,000 running on a Claude-built Polymarket bot
> Open it Monday morning
> $2,000 → $9,300
> The bot was scalping 5-minute BTC Up/Down markets the entire weekend.
> 15 minutes to set up.
> Zero babysitting.
> Pure edge.
> Welcome to 2026.
Aleiah@AleiahLock
English
a1exus retweetet

You can now fine-tune Gemma 4 31B for free in our notebook! 🚀
Training the 31B parameter model is completely free with Kaggle and Unsloth.
GitHub: github.com/unslothai/unsl…
Guide: unsloth.ai/docs/models/ge…
Gemma-4-31B Notebook: kaggle.com/code/danielhan…

English
a1exus retweetet

1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵

English
a1exus retweetet

THIS GUY AUDITED 926 CLAUDE CODE SESSIONS AND FOUND MOST OF THE TOKEN WASTE WAS ON HIS SIDE
everyone is blaming anthropic for the limits, so he decided to actually look at the data
858 sessions, 18,903 turns, and $1,619 estimated spend across 33 days
here's what he found:
1\ one default setting was burning 14,000 tokens per turn
Claude Code loads the full JSON schema for every tool into context at session start. whether you use them or not. 20,000 tokens of tool definitions sitting there on every single turn.
the fix: one line in your settings.json
"ENABLE_TOOL_SEARCH": "true"
context dropped from 45K to 20K instantly. across 858 sessions that one setting was wasting an estimated 264 million tokens
2\ cache expiry is the single biggest waste
54% of his turns came after a 5+ minute idle gap.
every one of those turns re-processed the entire conversation at full price which caused a 10x cost jump
you go grab coffee. come back 5 minutes later. type your next message. everything rebuilds from scratch. the context didn't change. you didn't change. the cache just expired.
12.3 million tokens wasted on idle gaps alone
3\ 42 skills loaded. 19 of them used twice or less across 858 sessions.
every one of those skill schemas sat in context on every turn eating tokens for nothing.
4\ 1,122 redundant file reads where the same file was read 3+ times
one session read the same file 33 times.
he ALSO built a full token auditor dashboard that shows you exactly where your waste is coming from
19 charts, opens in your browser, free AND open source
English
a1exus retweetet

The third and largest wave of Tesla software update 2026.8.6 is now going out to the global fleet.
This wave includes HW3 and AI4 vehicles.
teslascope.com/software/2026.…
Teslascope@teslascope
We noticed a new Tesla software update 2026.8.6 on Model 3 AWD LR (2020) in Ohio, United States. View the rollout of this update here: teslascope.com/software/2026.…
English
a1exus retweetet

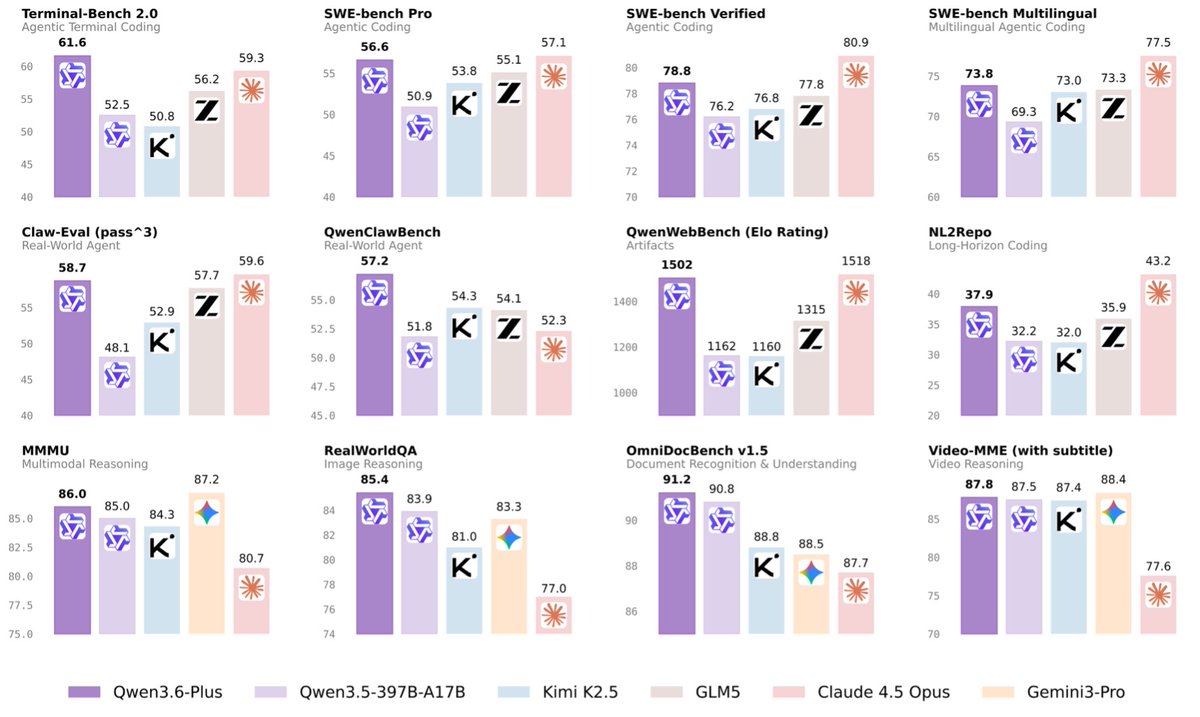
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️ Enhanced Multimodal Vision: Sharper perception & reasoning.
🏆 Top-tier Performance: Maintaining leading general capabilities.
📚 1M Context Window: Available by default via our API.
Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨.
Huge thanks to our community! Go try it out and show us what you can build. 👇
Chat: chat.qwen.ai
API: modelstudio.console.alibabacloud.com/ap-southeast-1…
Blog: qwen.ai/blog?id=qwen3.6
🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents
English
a1exus retweetet

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
a1exus retweetet

Claude code source code has been leaked via a map file in their npm registry!
Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip

English
a1exus retweetet

a1exus retweetet

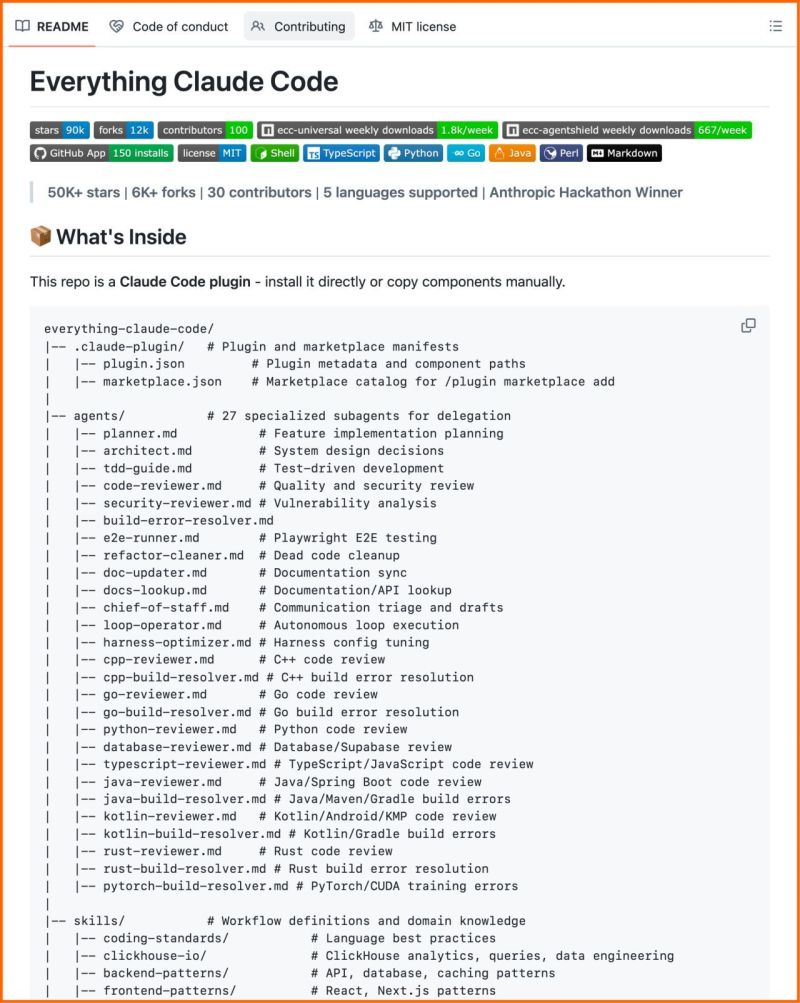
This is the most complete Claude Code setup that exists right now.
27 agents. 64 skills. 33 commands. All open source.
The Anthropic hackathon winner open-sourced his entire system, refined over 10 months of building real products.
What's inside:
→ 27 agents (plan, review, fix builds, security audits)
→ 64 skills (TDD, token optimization, memory persistence)
→ 33 commands (/plan, /tdd, /security-scan, /refactor-clean)
→ AgentShield: 1,282 security tests, 98% coverage
60% documented cost reduction.
Works on Claude Code, Cursor, OpenCode, Codex CLI. 100% open source.
English
a1exus retweetet
🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI.
Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction.
A standout feature: 'Audio-Visual Vibe Coding'. Describe your vision to the camera, and Qwen3.5-Omni-Plus instantly builds a functional website or game for you.
Offline Highlights:
🎬 Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping.
🏆 SOTA Performance: Outperform Gemini-3.1 Pro in audio and matches its audio-visual understanding.
🧠 Massive Capacity: Natively handle up to 10h of audio or 400s of 720p video, trained on 100M+ hours of data.
🌍 Global Reach: Recognize 113 languages (speech) & speaks 36.
Real-time Features:
🎙️ Fine-Grained Voice Control: Adjust emotion, pace, and volume in real-time.
🔍 Built-in Web Search & complex function calling.
👤 Voice Cloning: Customize your AI's voice from a short sample, with engineering rollout coming soon.
💬 Human-like Conversation: Smart turn-taking that understands real intent and ignores noise.
The Qwen3.5-Omni family includes Plus, Flash, and Light variants.
Try it out:
Blog: qwen.ai/blog?id=qwen3.…
Realtime Interaction: click the VoiceChat/VideoChat button (bottom-right): chat.qwen.ai
HF-Demo: huggingface.co/spaces/Qwen/Qw…
HF-VoiceOnline-Demo: huggingface.co/spaces/Qwen/Qw…
API-Offline: alibabacloud.com/help/en/model-…
API-Realtime: alibabacloud.com/help/en/model-…

English
a1exus retweetet

🚨 Google just wiped out the entire call center industry.
→ Their new voice API handles sub-second latency voice AI
→ Multi-lingual calls perfectly.
→ 90+ languages.
→ Replaces receptionists with a Python script.
Want to profit?
Do this:
#1 Target salons, clinics or similar
#2 Build an AI agent to handle FAQs & bookings
#3 Charge $1000/mo (Human receptionists cost $3k/mo).
The window closes in 6 months or less. Build it today 😏
Google AI Studio@GoogleAIStudio
English
a1exus retweetet
a1exus retweetet


a1exus retweetet

When @karpathy built MenuGen (karpathy.bearblog.dev/vibe-coding-me…), he said:
"Vibe coding menugen was exhilarating and fun escapade as a local demo, but a bit of a painful slog as a deployed, real app. Building a modern app is a bit like assembling IKEA future. There are all these services, docs, API keys, configurations, dev/prod deployments, team and security features, rate limits, pricing tiers."
We've all run into this issue when building with agents: you have to scurry off to establish accounts, clicking things in the browser as though it's the antediluvian days of 2023, in order to unblock its superintelligent progress.
So we decided to build Stripe Projects to help agents instantly provision services from the CLI.
For example, simply run:
$ stripe projects add posthog/analytics
And it'll create a PostHog account, get an API key, and (as needed) set up billing.
Projects is launching today as a developer preview. You can register for access (we'll make it available to everyone soon) at projects.dev. We're also rolling out support for many new providers over the coming weeks. (Get in touch if you'd like to make your service available.)
projects.dev
English
a1exus retweetet

a1exus retweetet

Wine 11 rewrites how Linux runs Windows games at the kernel level, and the speed gains are massive.
NTSYNC support uses a new Linux kernel module to handle Windows-style thread synchronization directly at the kernel level.
Notable benchmark gains (compared to basic upstream Wine without prior optimizations):
- Dirt 3: around 110 FPS to over 860 FPS
- Tiny Tina's Wonderlands: 130 FPS to 360 FPS
- Resident Evil 2: 26 FPS to 77 FPS
- Call of Juarez: around 100 FPS to 224 FPS


English