
@tskaerobot @Yuchenj_UW Upload all tax documents. Prompt "prepare my 2025 tax" and your information (like location, single or married, ...). Same as what you would send to CPA. (If you don't know which docs are needed, just ask it)
English
Lequn Chen
49 posts

@abcdabcd987
Faster and cheaper LLM inference.




@Yuchenj_UW Perplexity Computer saved me $14k in tax. It found 2 double taxing errors and 2 form filling errors from my $2000-CPA's draft, which CPA fully agreed. In another thread, I let it compute tax from scratch. It's correct to the cents.

Perplexity is the first to develop custom Mixture-of-Experts (MoE) kernels that make trillion-parameter models available with cloud platform portability. Our team has published this work on arXiv as Perplexity's first research paper. Read more: research.perplexity.ai/articles/enabl…



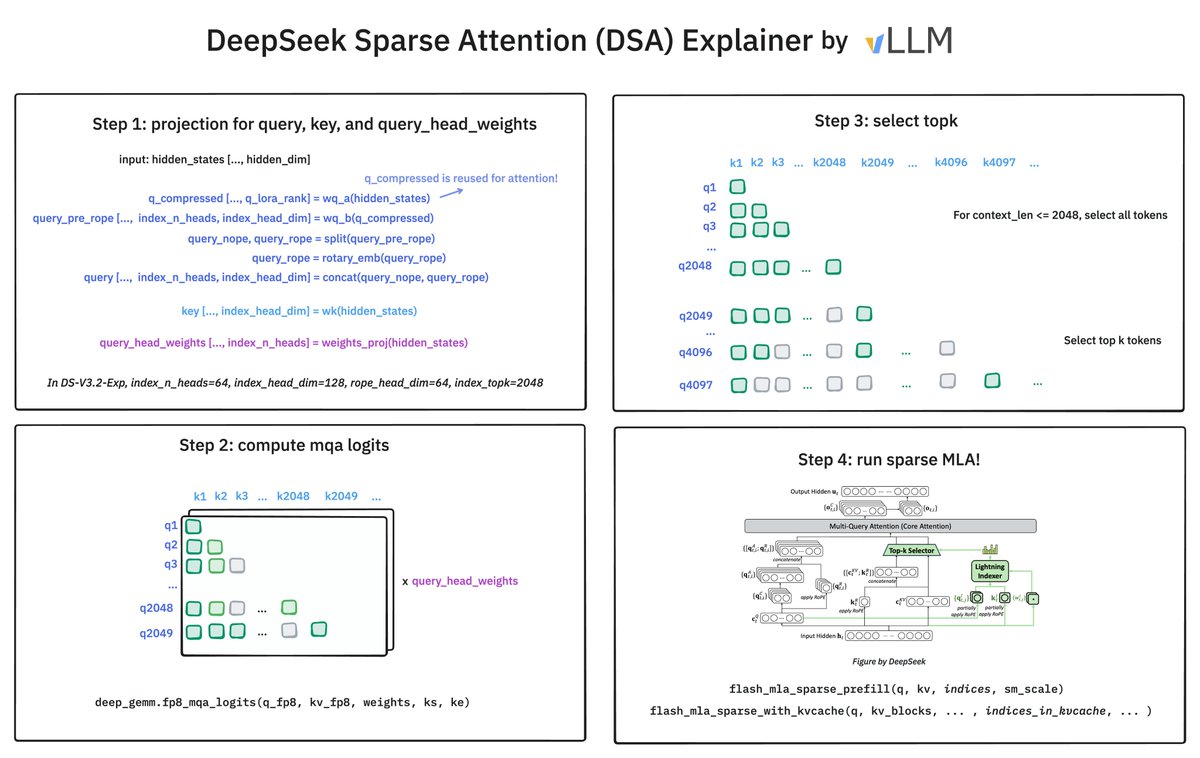
🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n







1.5 seconds is long enough to transfer model weights from training nodes to RL rollout nodes (as opposed to 100s). Here's the full story of how I made it (not just presenting the solution): le.qun.ch/en/blog/2025/0…

1.5 seconds is long enough to transfer model weights from training nodes to RL rollout nodes (as opposed to 100s). Here's the full story of how I made it (not just presenting the solution): le.qun.ch/en/blog/2025/0…

