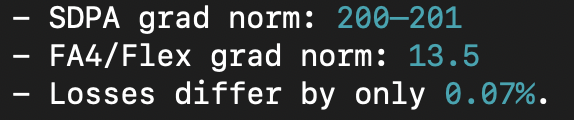
@kalomaze Hmmm open an issue with what you got would be fun to figure out what’s going on
English
driss guessous
553 posts
@drisspg
bytes and nuggets @pytorch https://t.co/gWVJmW741f





🏆 High-Quality CoT Our model doesn't just get answers right, it does so beautifully 🌺 Comprehensibility: structured CoT ⚡ Token-Efficient: Solves AIME using < half the tokens of baselines 🌟 Reproducible: 100K of our traces distilled into Qwen-32B beat 800K of DeepSeek-R1





We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.