Angehefteter Tweet

Incredibly honored to present our work at #Eurographics2026 here in beautiful Aachen! 🇩🇪
Huge thanks to @EurographicsC, @CDInstitut and @StanfordEthics for the support and the scholarship that made this trip possible.
I’m beyond thrilled to be part of such an amazing research community passionate about Sketch-to-3D.
Thank you all for having us and for the fantastic questions and discussions today. 🎨✨
You can check out our slides here: cdinstitute.github.io/Morpheus/
Finally, I want to take a moment to deeply thank my incredible collaborators who pushed me toward the finish line. This work simply wouldn't have been possible without you: @jiajunwu_cs, @ir0armeni, @HariSubramonyam, @GordonWetzstein, @landay & @fischermartin 🙏👏
Soon, I will present my PhD research at the EG PhD Consortium, if you're around the conference, I'd love to connect!
#cv #hci #graphics
Alberto Tono@albertotono3
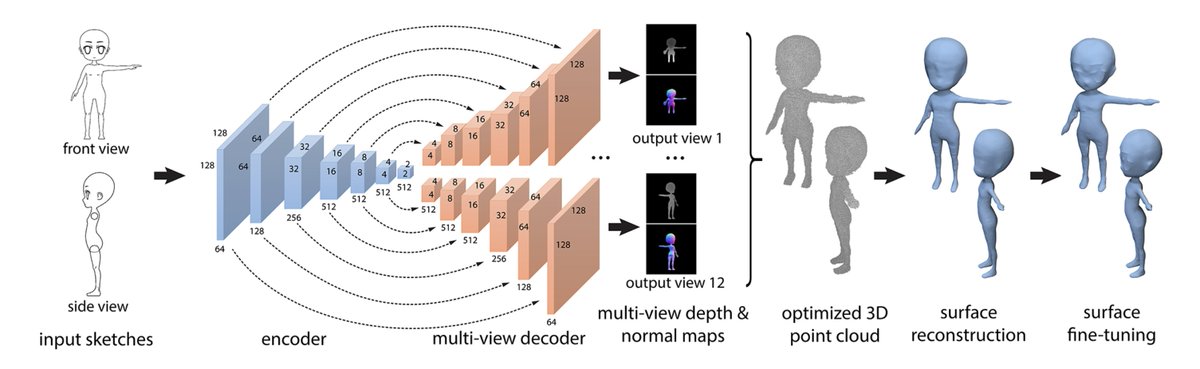
1/3 We are thrilled to introduce MORPHEUS 🎊: a design space to survey the Deep Sketch-Based 3D Modeling (DS-3DM) literature. ✍Navigating the shift from 2D sketches to 3D raises fundamental questions: How do we ensure novel interfaces truly foster Engelbartian human augmentation? Our work bridges #CV, #ComputerGraphics, and #HCI to advocate for human-centered, informed, and controlled design, requiring a holistic understanding of input, model, and output. Ready for the R3D pill? 💊🐇 🌐Website: cdinstitute.github.io/Morpheus/ 📄Paper: onlinelibrary.wiley.com/doi/10.1111/cg… 💻Github: github.com/albertotono/Aw… Authors: @albertotono3 , @jiajunwu_cs , @GordonWetzstein , @ir0armeni , @HariSubramonyam , @landay , @fischermartin
English