Sabitlenmiş Tweet

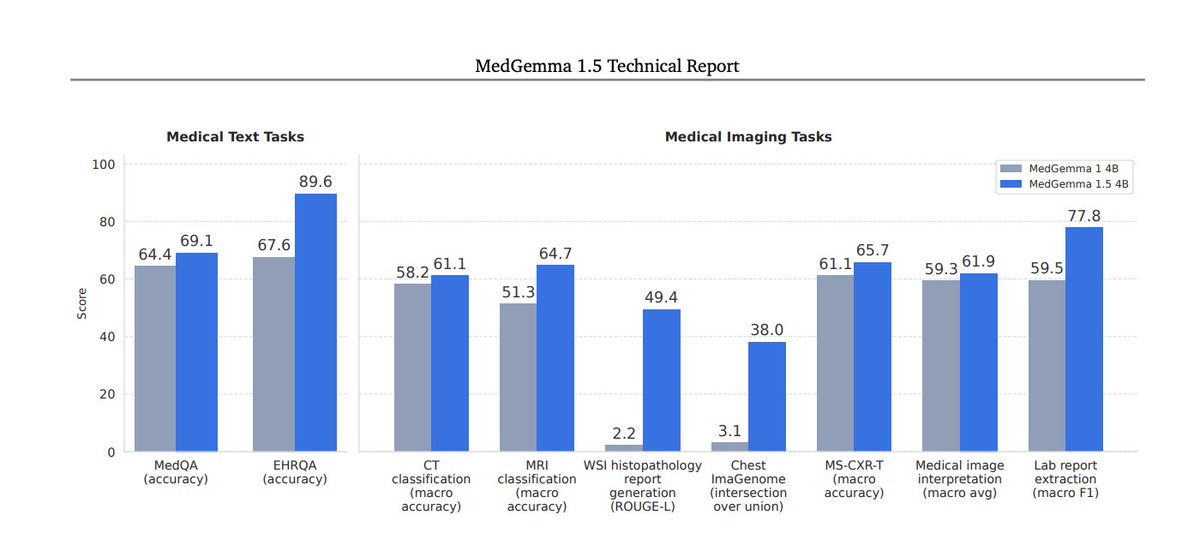
1/3 We are thrilled to introduce MORPHEUS 🎊: a design space to survey the Deep Sketch-Based 3D Modeling (DS-3DM) literature.
✍Navigating the shift from 2D sketches to 3D raises fundamental questions: How do we ensure novel interfaces truly foster Engelbartian human augmentation?
Our work bridges #CV, #ComputerGraphics, and #HCI to advocate for human-centered, informed, and controlled design, requiring a holistic understanding of input, model, and output.
Ready for the R3D pill? 💊🐇
🌐Website: cdinstitute.github.io/Morpheus/
📄Paper: onlinelibrary.wiley.com/doi/10.1111/cg…
💻Github: github.com/albertotono/Aw…
Authors: @albertotono3 , @jiajunwu_cs , @GordonWetzstein , @ir0armeni , @HariSubramonyam , @landay , @fischermartin
English