Andy Zou retweetet

As AI agents access more untrusted information with greater autonomy, prompt injections may become the greatest security challenge of our era.
@GraySwanAI, in collaboration many frontier labs, just released our paper on the largest public prompt injection challenge to date.
🧵
Gray Swan AI@GraySwanAI
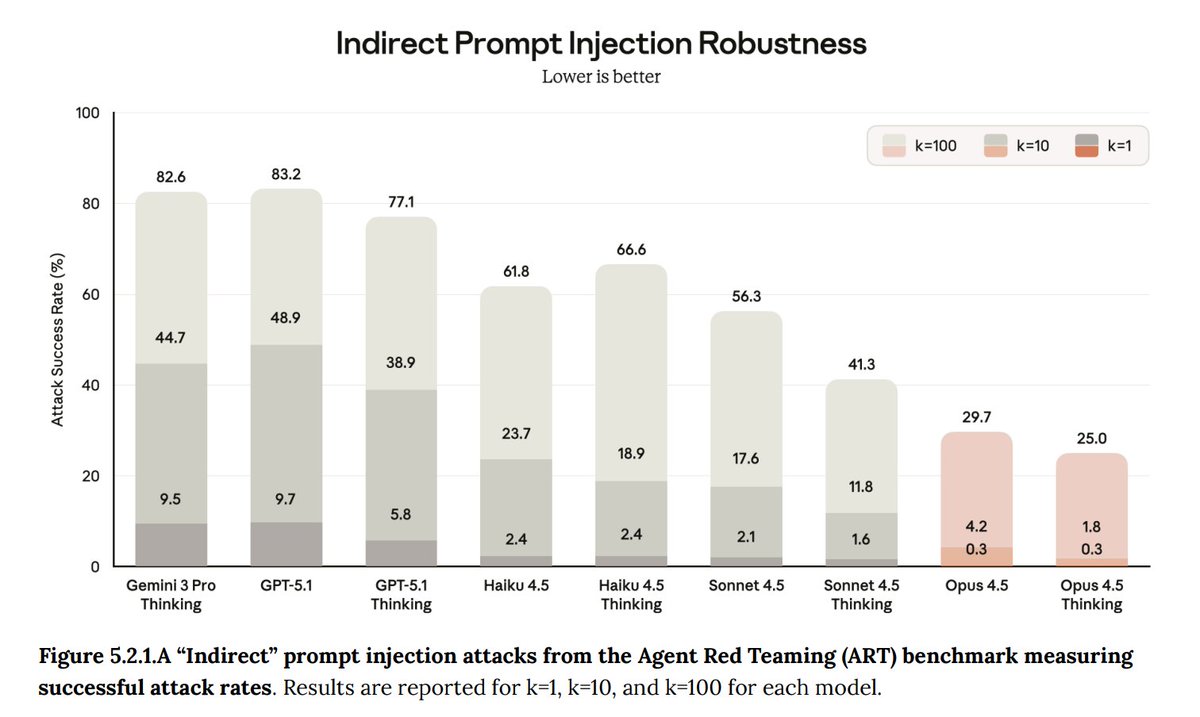
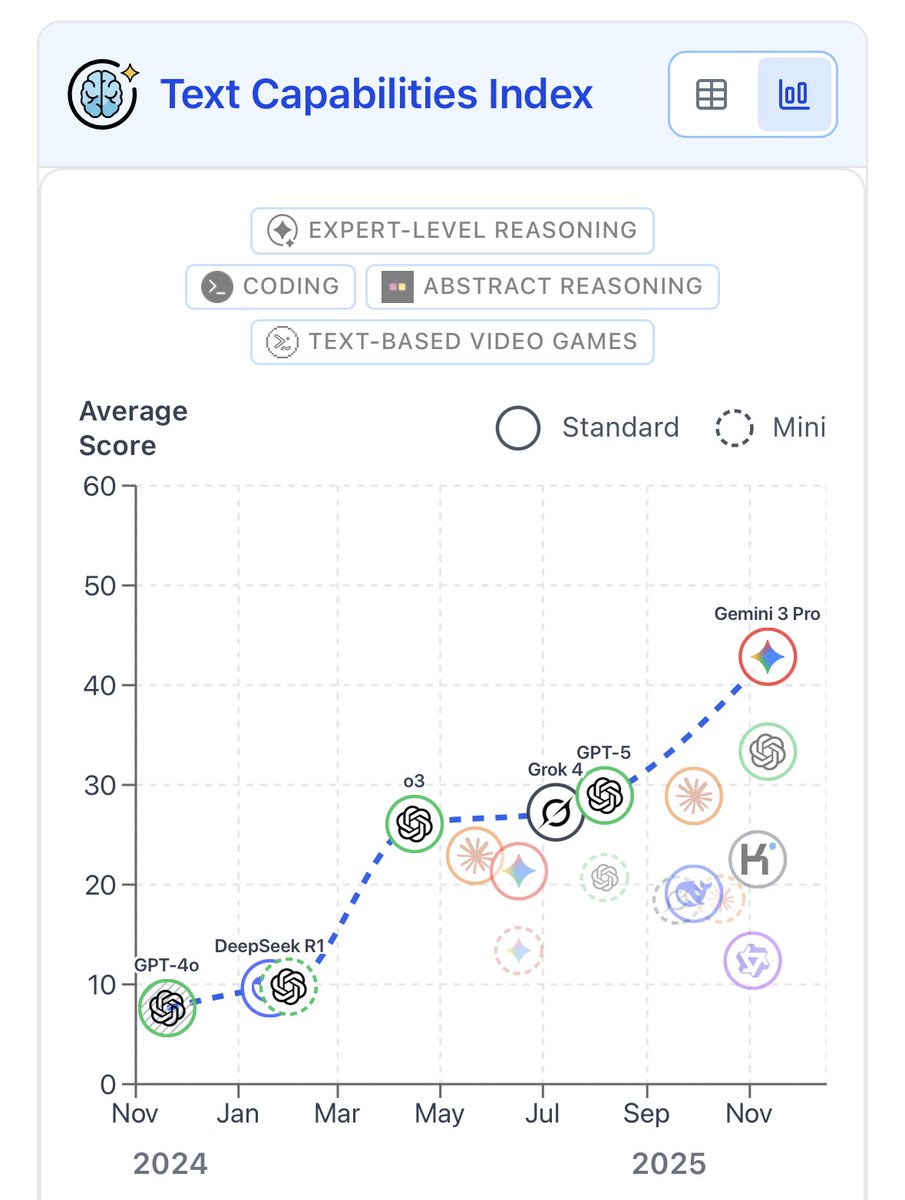
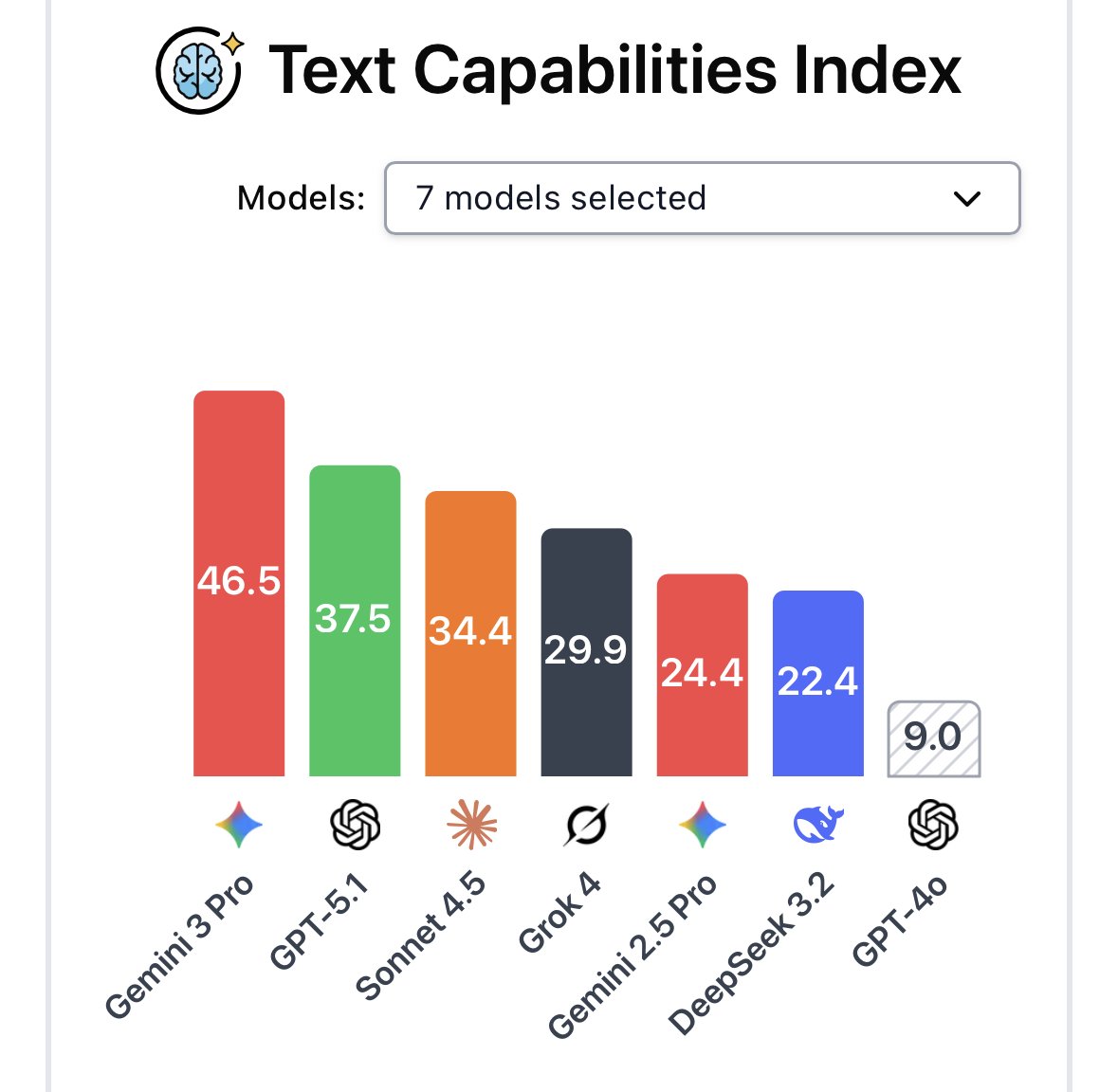
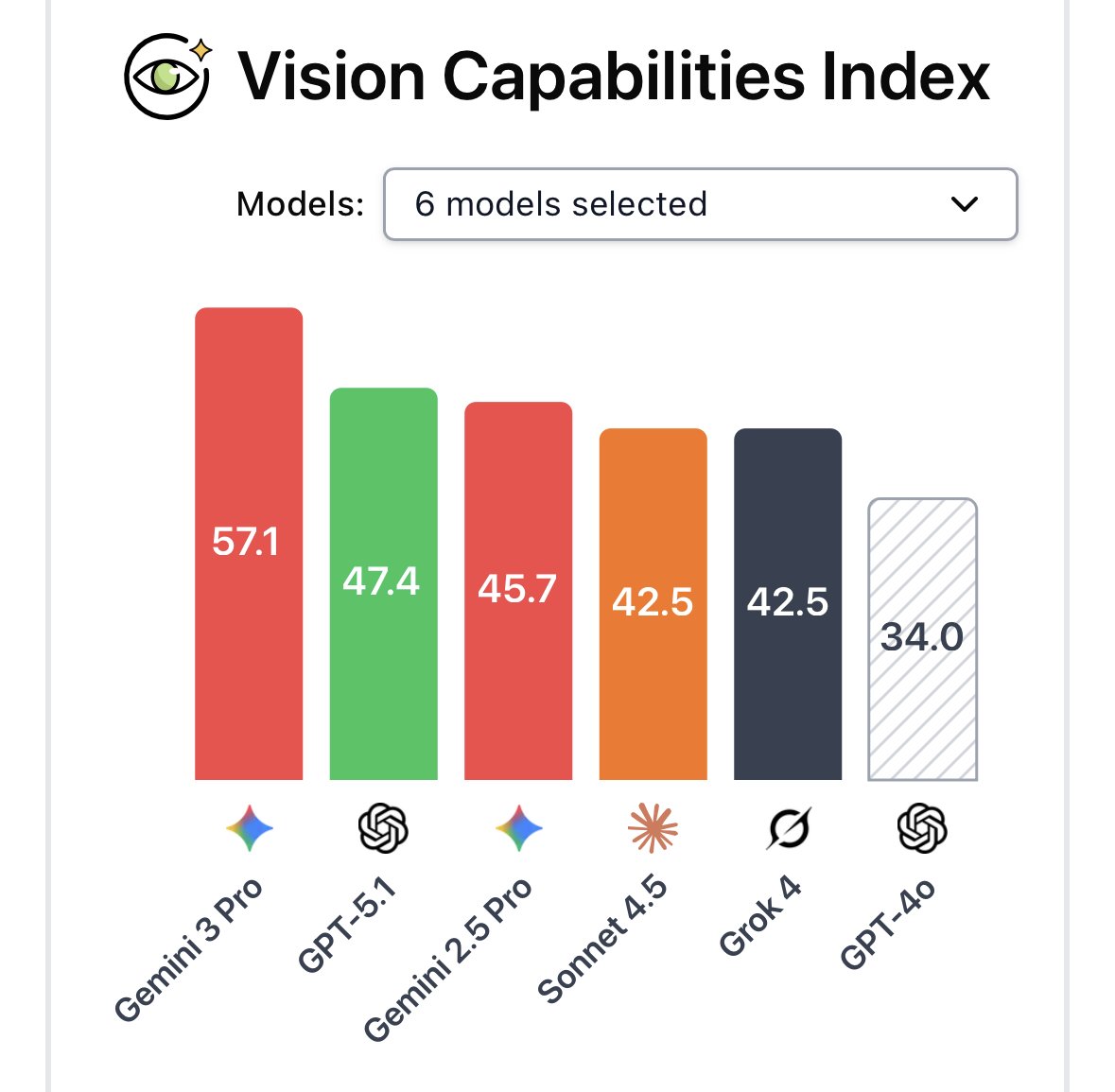
Your AI agent can be hijacked by a prompt injection and you'd never know! The attack executes. The response looks normal. And the user moves on. We ran the largest public competition testing this exact threat across tool use, coding, and computer use agents. 464 participants, 272K attacks, 13 frontier models. Every model proved vulnerable.
English