@dontbanjake @LottoLabs But I feel Lotto. It’s a beautiful way of procrastination
English
Apptor
643 posts

@apptor_at
Trying to keep up with AI trends on X. Building https://t.co/a6nLgWcYmx as a side hustle.





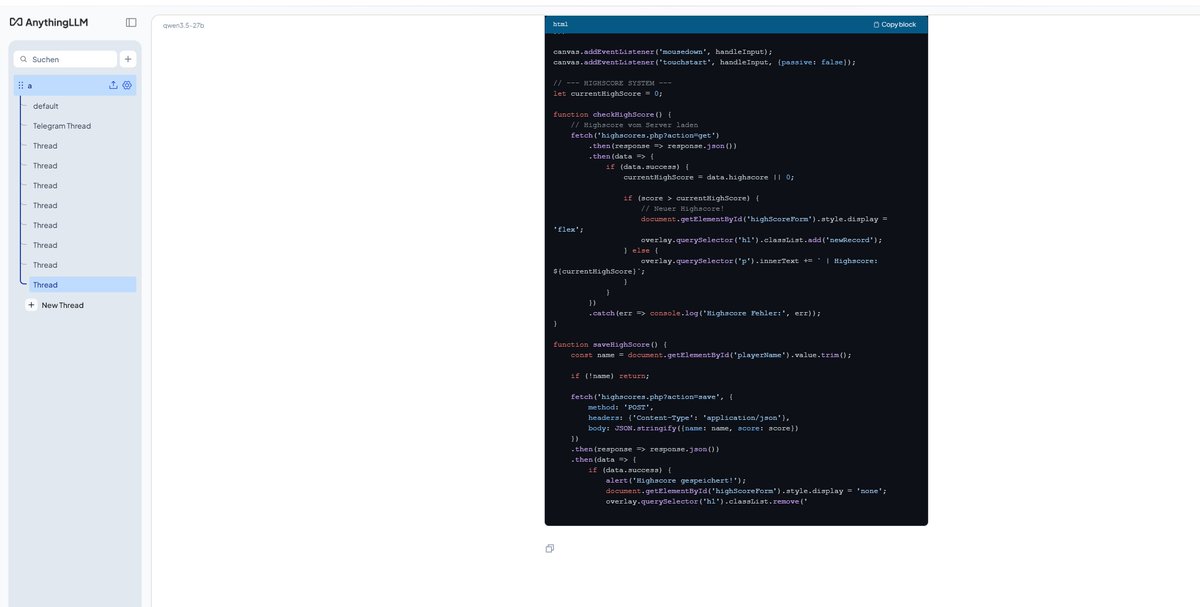
4090 datapoint, WSL2 Ubuntu CUDA 13.2, your exact flags + Q4_K_M: ./llama-server -m Qwen3.6-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 three warm runs on "yo" with thinking auto, system fully idle: - run 1: 42.83 tok/s - run 2: 43.18 tok/s - run 3: 43.33 tok/s - avg ~43.1 tok/s VRAM at 262k provisioned: 23.0GB / 1.1GB free of 24GB. tighter than your 21/3 split — WSL2 + cuda driver reserves eating ~2GB of headroom. native linux would likely give that back. so 4090 + WSL2 = +8.3% over your 3090 native baseline. roughly tracks the bandwidth gap (1008 vs 936 GB/s). bare metal linux on a 4090 should land higher still — would estimate 45-48 tok/s range for someone running native. side observation worth flagging: a single youtube tab in chrome dropped these numbers to ~39.9 tok/s in earlier runs. ~7-8% throughput cost from the browser competing for CPU/scheduling on the WSL side. anyone running this on a daily-driver PC should close everything before measuring.



.@vonderleyen "The European #AgeVerification app is technically ready. It respects the highest privacy standards in the world. It's open-source, so anyone can check the code..." I did. It didn't take long to find what looks like a serious #privacy issue. The app goes to great lengths to protect the AV data AFTER collection (is_over_18: true is AES-GCM'd); it does so pretty well. But, the source image used to collect that data is written to disk without encryption and not deleted correctly. For NFC biometric data: It pulls DG2 and writes a lossless PNG to the filesystem. It's only deleted on success. If it fails for any reason (user clicks back, scan fails & retries, app crashes etc), the full biometric image remains on the device in cache. This is protected with CE keys at the Android level, but the app makes no attempt to encrypt/protect them. For selfie pictures: Different scenario. These images are written to external storage in lossless PNG format, but they're never deleted. Not a cache... long-term storage. These are protected with DE keys at the Android level, but again, the app makes no attempt to encrypt/protect them. This is akin to taking a picture of your passport/government ID using the camera app and keeping it just in case. You can encrypt data taken from it until you're blue in the face... leaving the original image on disk is crazy & unnecessary. From a #GDPR standpoint: Biometric data collected is special category data. If there's no lawful basis to retain it after processing, that's potentially a material breach. youtube.com/watch?v=4VRRri…

✨ I can now generate 3d assets for my drone sim at drone.pieter.com directly from Cursor (sponsor of #vibejam) I need buildings that you'd see in a war torn city, like warehouses in ruins, broken down abandoned houses, bombed out bridges etc. Nano Banana Pro or 2 can generate them really well and then you can put them in an image-to-3d model and you get a GLB or FBX That one you can then import into your @ThreeJS game, the models might be big though, in my case like 16MB, so I ask it to compress it and make it more low poly so it loads fast ThreeJS then loads the individual GLBs on page load and puts them in my drone sim somewhere randomly, I think I should remove some of the grass and match the sandy color of the ruins though to make it fit in more