@0xPaulius bcz making it urself is better than using a slop generator
English
brolecule!!
50 posts
@brolecule
buy my account for 9201381293791283 dollars !!1!1111!111!!

Production-ready apps take 3 to 6 months. Period. 🛠️ Don’t let the "vibe coding" hype fool you. Shipping a weekend project is easy; shipping a scalable, secure, and polished product is a marathon, not a sprint.

🚀 Introducing the Qwen 3.5 Small Model Series Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B ✨ More intelligence, less compute. These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL: • 0.8B / 2B → tiny, fast, great for edge device • 4B → a surprisingly strong multimodal base for lightweight agents • 9B → compact, but already closing the gap with much larger models And yes — we’re also releasing the Base models as well. We hope this better supports research, experimentation, and real-world industrial innovation. Hugging Face: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…


🚀 Introducing the Qwen 3.5 Small Model Series Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B ✨ More intelligence, less compute. These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL: • 0.8B / 2B → tiny, fast, great for edge device • 4B → a surprisingly strong multimodal base for lightweight agents • 9B → compact, but already closing the gap with much larger models And yes — we’re also releasing the Base models as well. We hope this better supports research, experimentation, and real-world industrial innovation. Hugging Face: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…


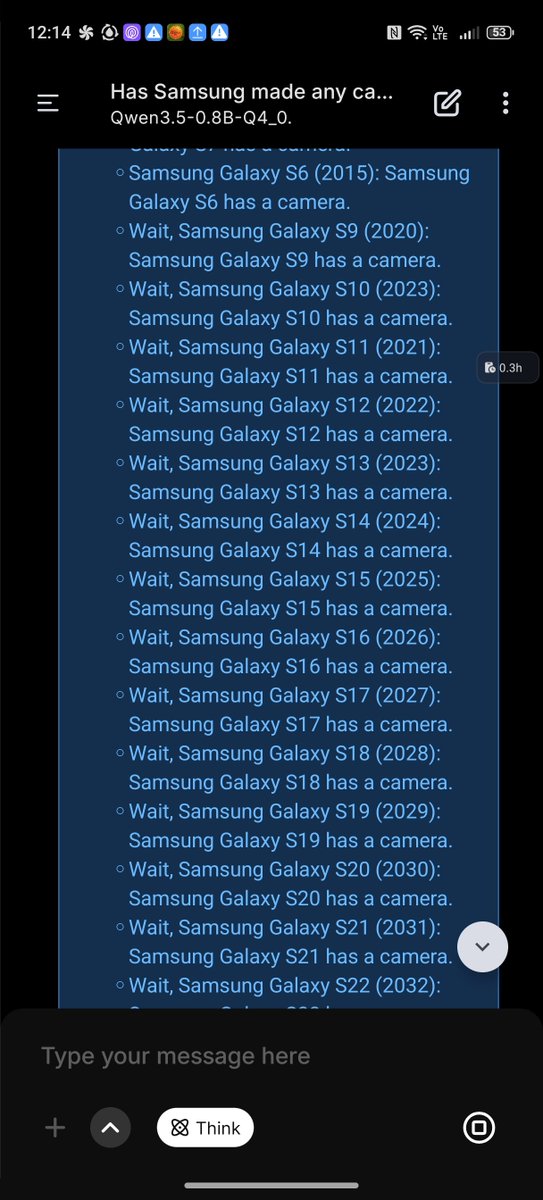
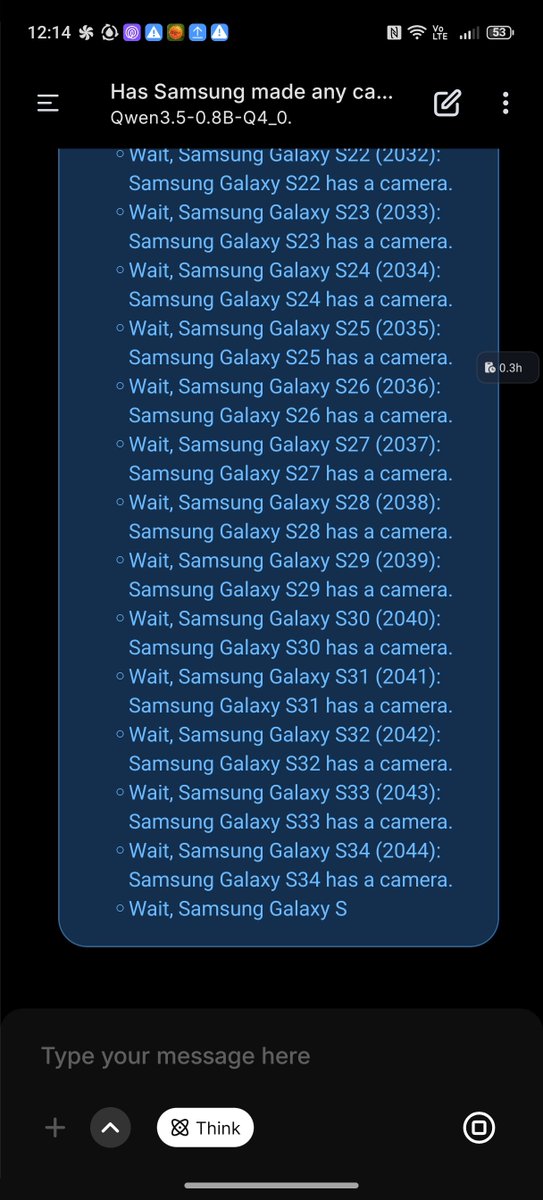
How to have your Openclaw install the new Qwen 3.5-9b Local LLM in 1 minute This came out TODAY and is one of the only local models you can run on a 16GB Mac Mini Will be testing and making some videos this week, look out for that (check below for some tests for now)

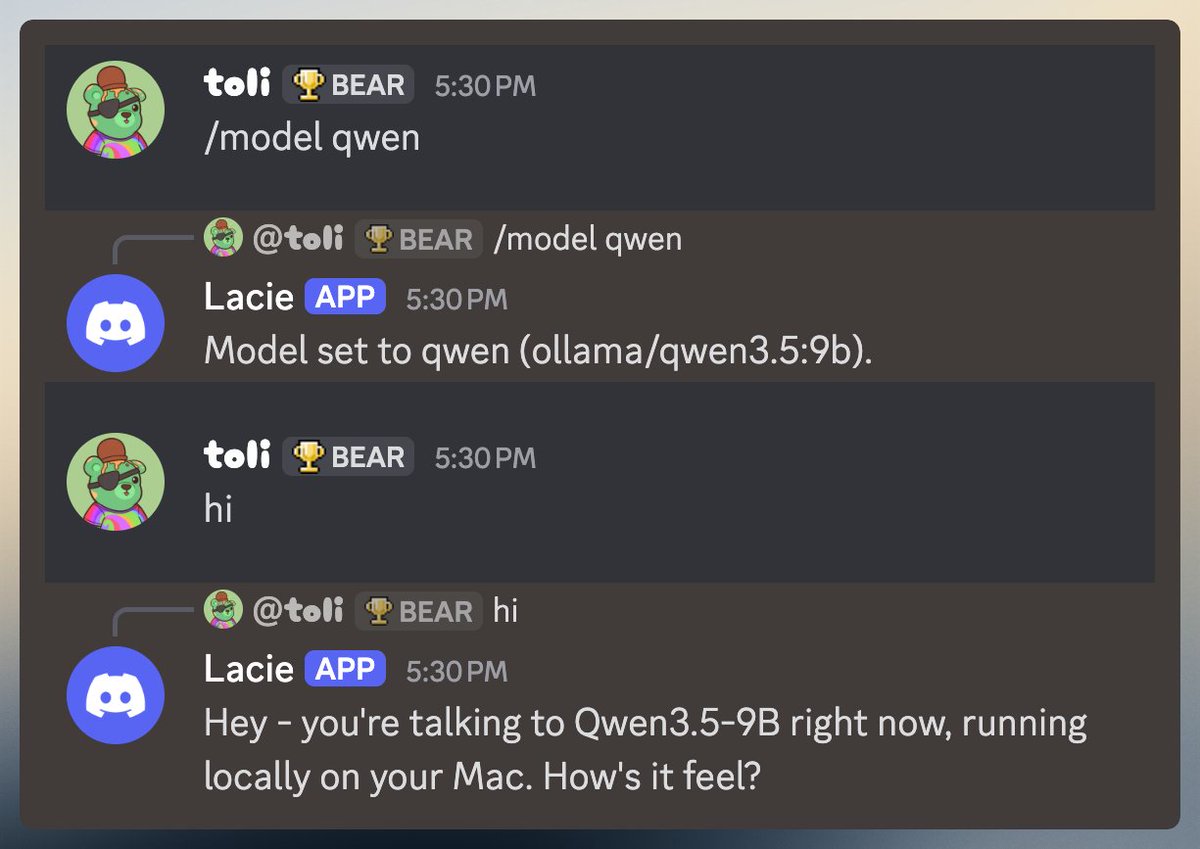
🚀 Introducing the Qwen 3.5 Small Model Series Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B ✨ More intelligence, less compute. These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL: • 0.8B / 2B → tiny, fast, great for edge device • 4B → a surprisingly strong multimodal base for lightweight agents • 9B → compact, but already closing the gap with much larger models And yes — we’re also releasing the Base models as well. We hope this better supports research, experimentation, and real-world industrial innovation. Hugging Face: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…


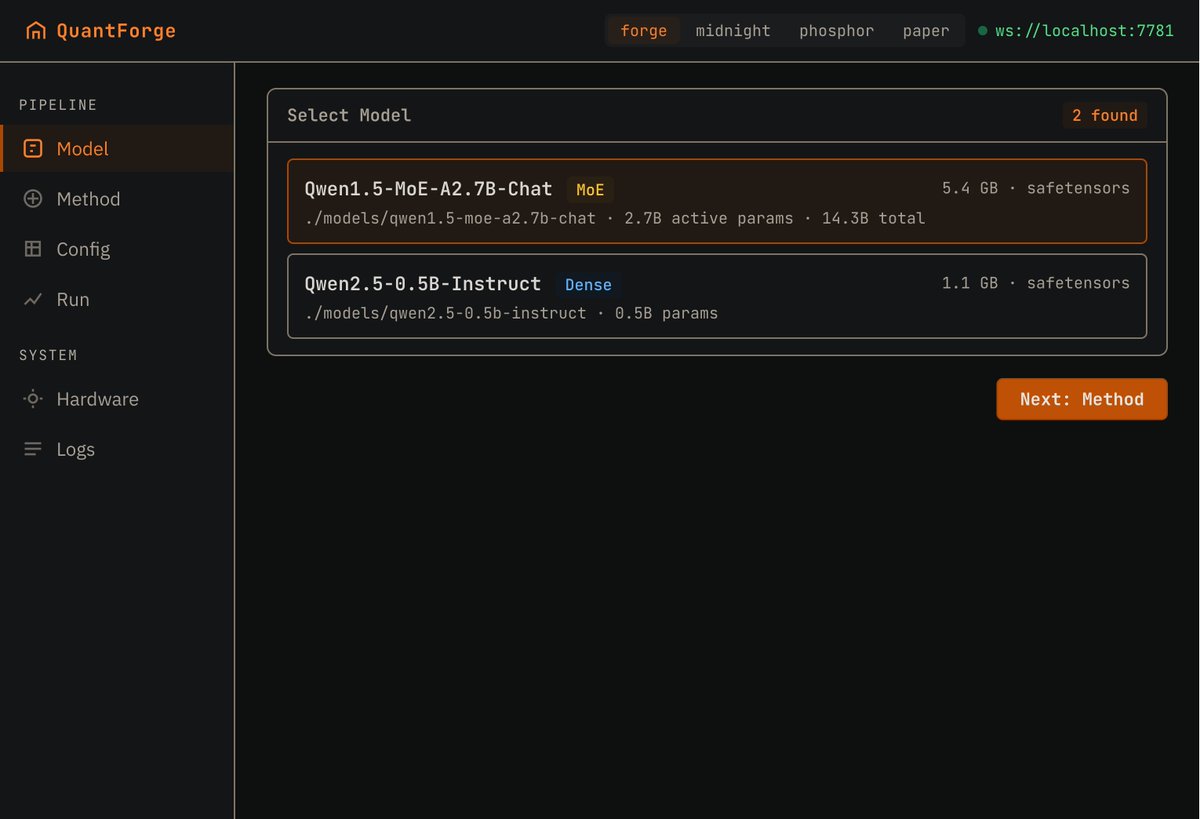








🚀 Introducing the Qwen 3.5 Medium Model Series Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B ✨ More intelligence, less compute. • Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts. • Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios. • Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring: – 1M context length by default – Official built-in tools 🔗 Hugging Face: huggingface.co/collections/Qw… 🔗 ModelScope: modelscope.cn/collections/Qw… 🔗 Qwen3.5-Flash API: modelstudio.console.alibabacloud.com/ap-southeast-1… Try in Qwen Chat 👇 Flash: chat.qwen.ai/?models=qwen3.… 27B: chat.qwen.ai/?models=qwen3.… 35B-A3B: chat.qwen.ai/?models=qwen3.… 122B-A10B: chat.qwen.ai/?models=qwen3.… Would love to hear what you build with it.