Angehefteter Tweet

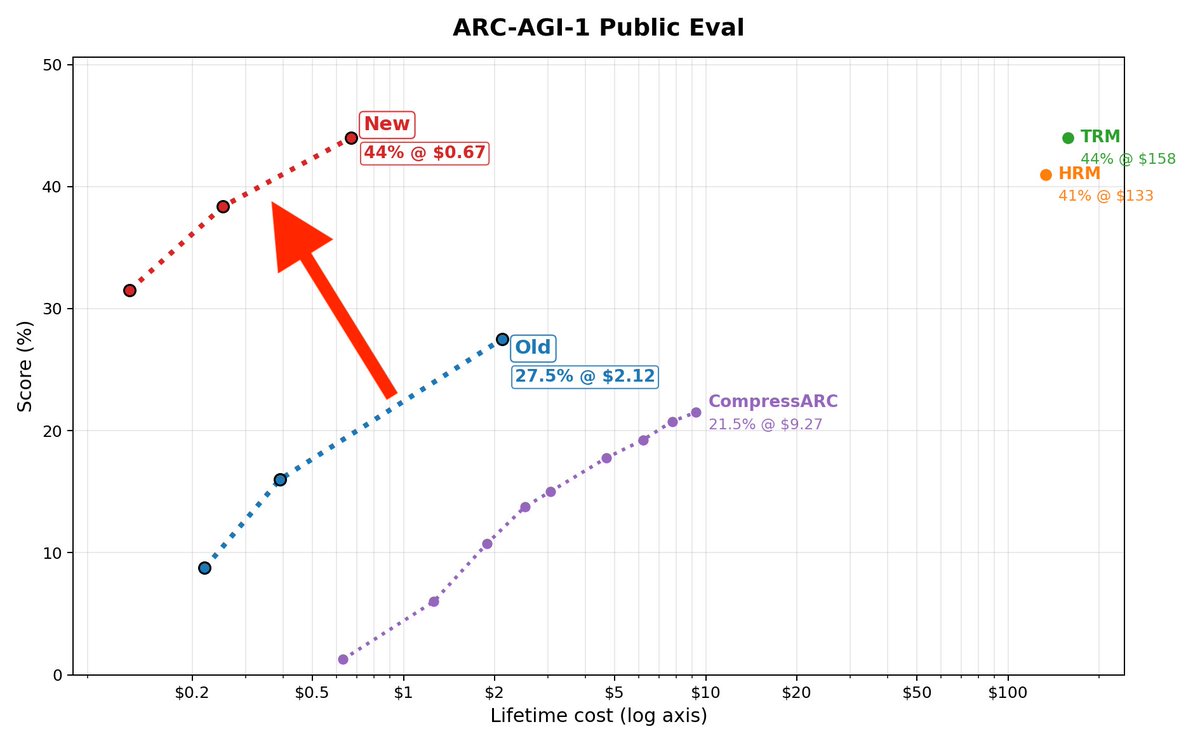
44% on ARC-AGI-1 in 67 cents!
Trained from scratch in 2hrs on a 5090
Matches TRM, beats HRM and is way faster & cheaper
No recursion, just a transformer
Also, 7% on ARC-2 🧵
English
Mithil Vakde
608 posts

@evilmathkid
Sample efficiency research prev: Engineering physics @iitbombay '23

Are you up for a challenge? openai.com/parameter-golf

Survey of ARC approaches over time Fascinating look - excited to read this

The organisers replied btw -- they are swamped and lack bandwidth to verify. I think lots of people submitted models Kinda bummed but I totally understand. Will post my public eval results tomorrow

44% on ARC-AGI-1 in 67 cents! Trained from scratch in 2hrs on a 5090 Matches TRM, beats HRM and is way faster & cheaper No recursion, just a transformer Also, 7% on ARC-2 🧵