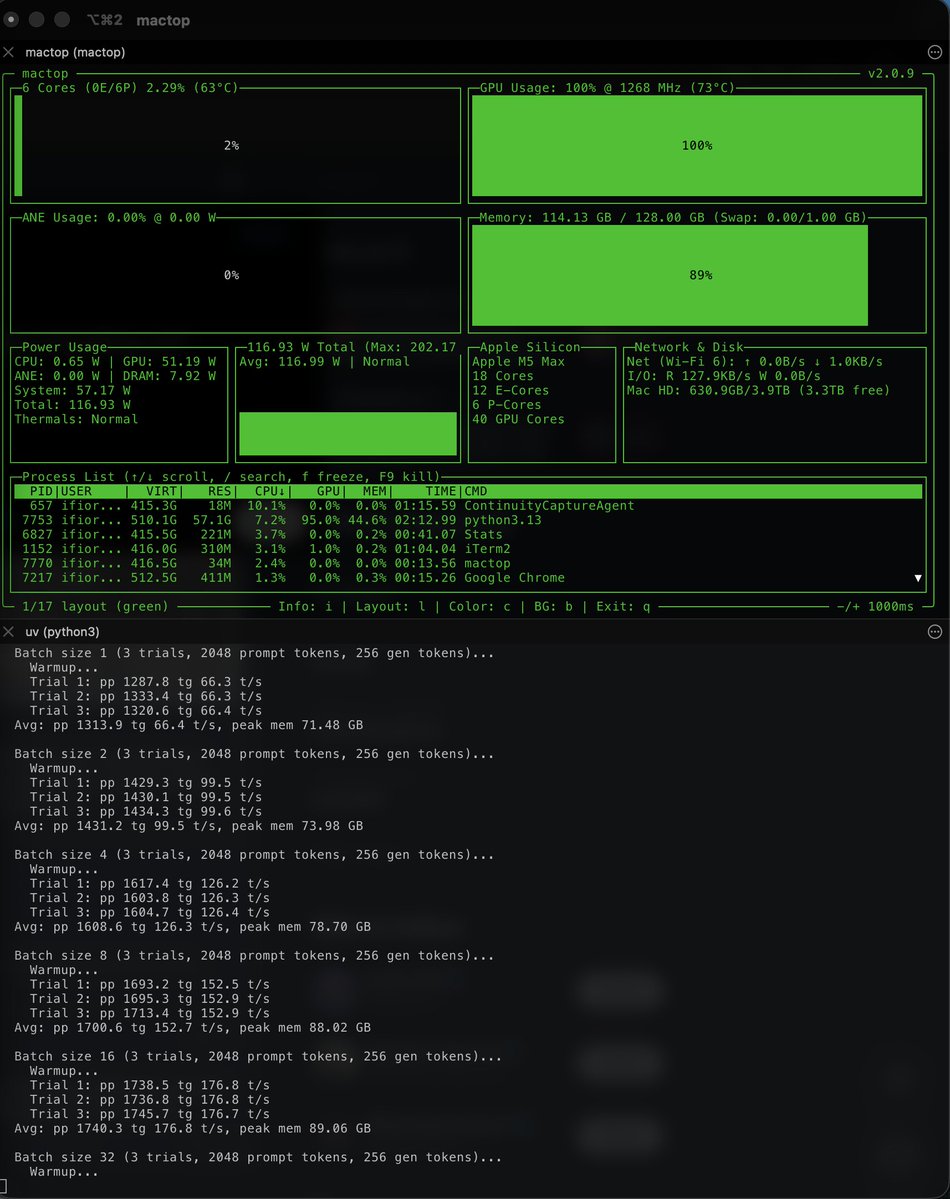
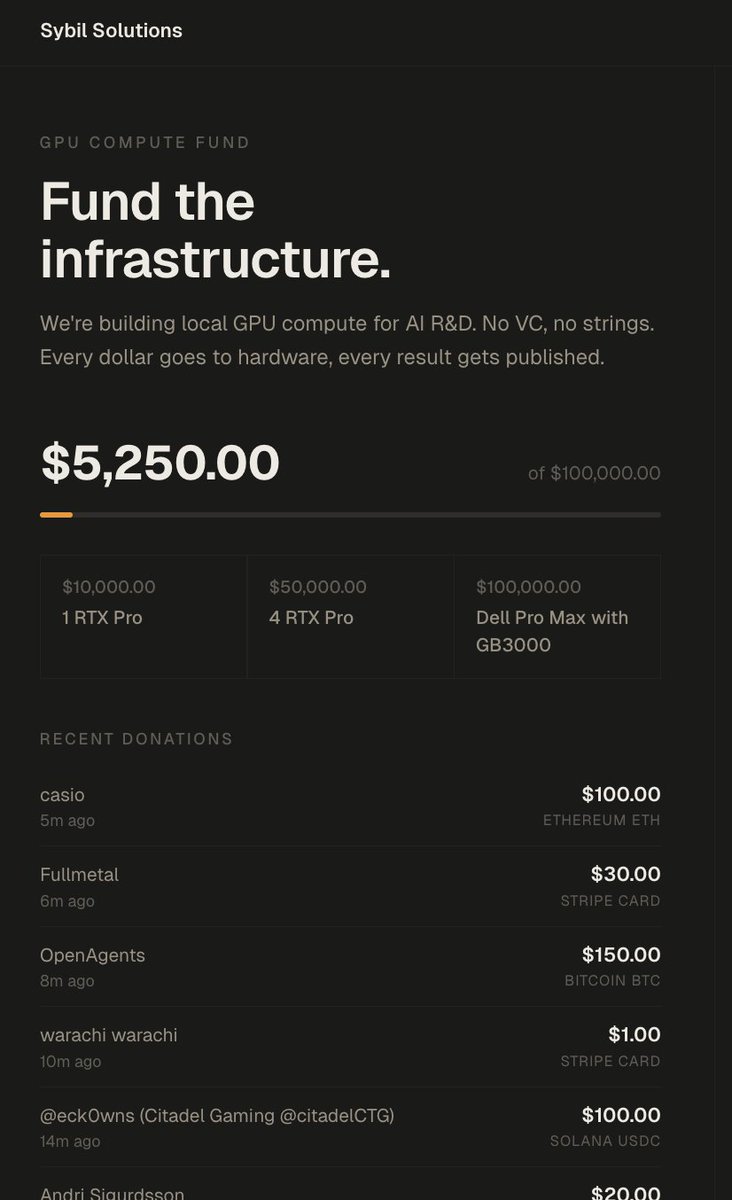
@ivanfioravanti DXG spark prefill. M5max 128. EXO. More AI than existed on the planet 3 years ago in my house
English
James Walker 🇬🇧🇺🇦
1.1K posts

@jxwalker
Independent Co. Husband/dad. Alpine hiker. ex Disney, JPM, Credit Suisse, Morgan Stanley, Bank of America and IBM. Work in tech. Own many GPUs and a DXG Spark.



🚨 This is how engineers at Amazon, Google, and Shopify actually use Claude Code. It's called GSD (Get Shit Done) and it solves context rot the quality degradation that destroys your Claude Code sessions as the context window fills up. No BMAD. No enterprise sprint theater. No Jira nonsense. Here's how it works: You run one command → /gsd:new-project → It interviews you until it fully understands your idea → Spawns parallel research agents to investigate your stack → Creates atomic task plans with XML structure Claude actually understands → Executes in fresh 200k context windows per task → Commits every single task to git automatically Here's the wildest part: Your main context window stays at 30-40% the entire time. All the heavy lifting happens in subagent contexts. No degradation. No "I'll be more concise now." Just clean, consistent execution. Engineers at Amazon, Google, Shopify, and Webflow trust this thing. MIT license. One command to install: npx get-shit-done-cc@latest Link in the first comment 👇













M5 Max 40 GPU cores WINS vs M3 Ultra 80 GPU cores with Qwen Image 2512 bf16 30 steps image generation: 🥇 M5 Max 122 secs 🥈 M3 Ultra 206 secs I have used @drawthingsapp for this test with CoreML and all compute units.