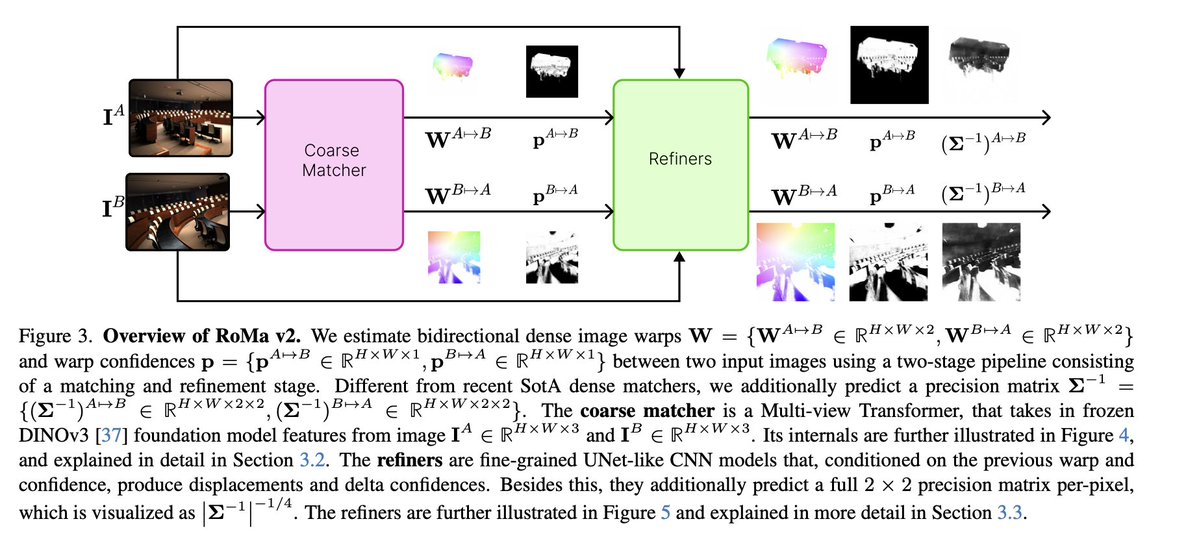
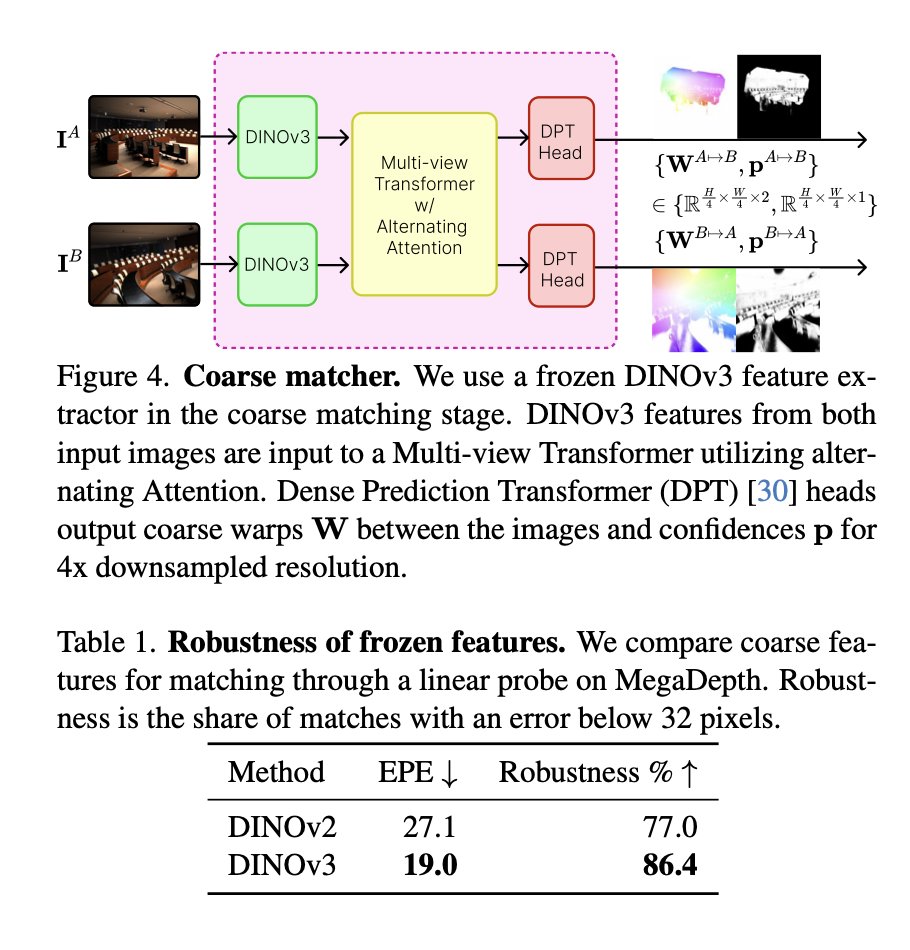
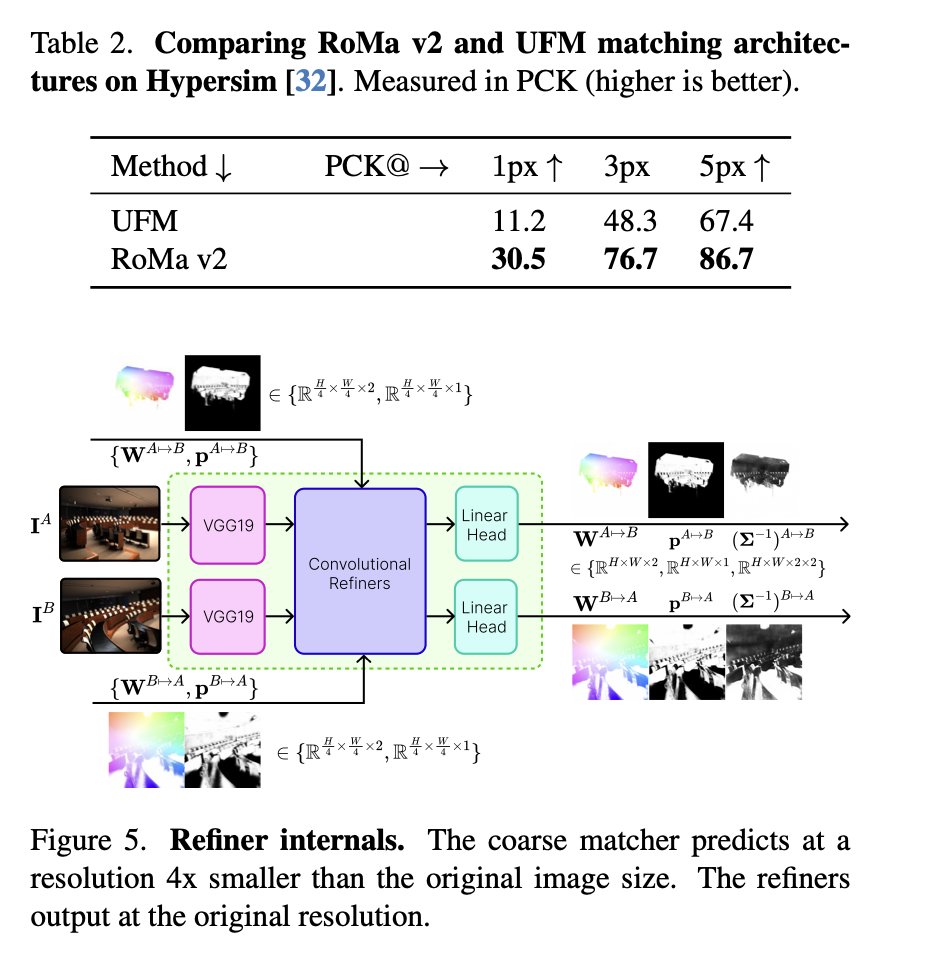
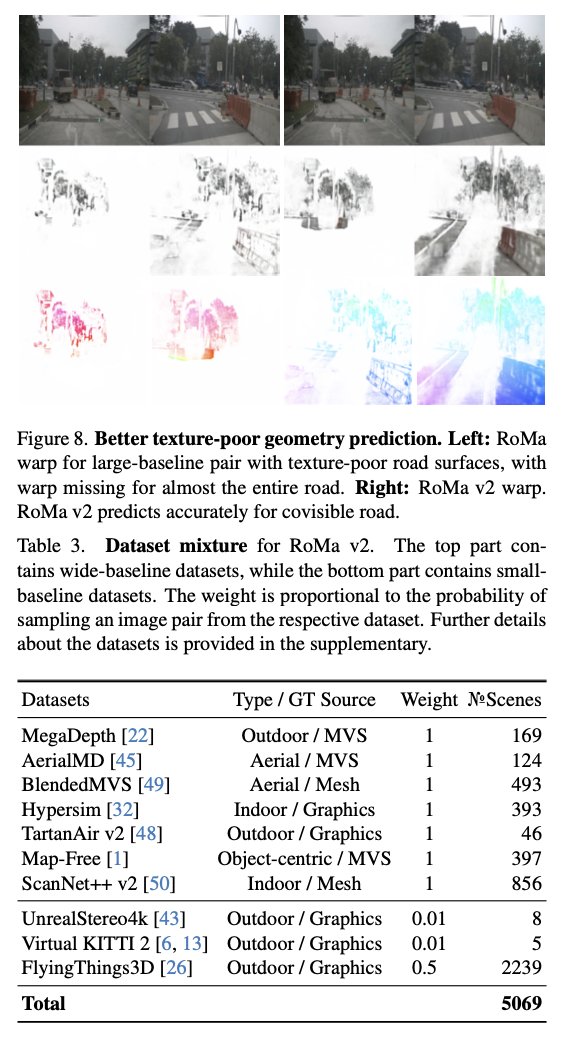
Angehefteter Tweet

[1/6] Recent models like DUSt3R generalize well across viewpoints, but performance drops on aerial-ground pairs.
At #CVPR2025, we propose AerialMegaDepth (aerial-megadepth.github.io), a hybrid dataset combining mesh renderings with real ground images (MegaDepth) to bridge this gap.
English