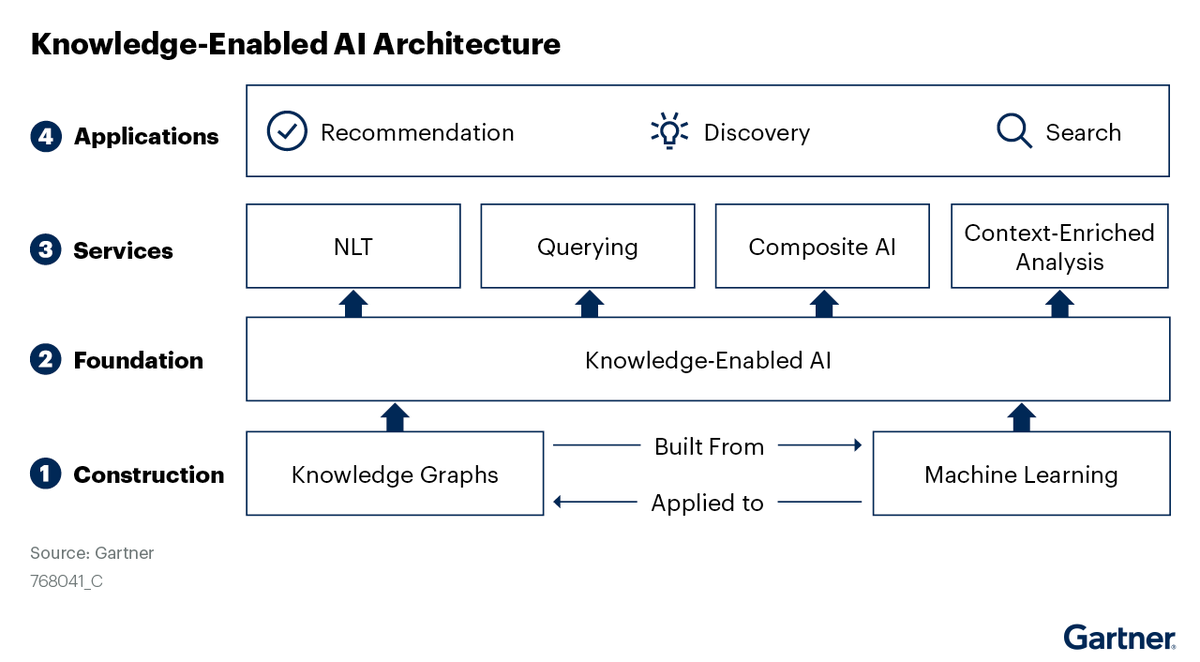
Martynas Jusevičius retweetet

Extraordinary that Trump's allies in Europe are three dictatorships, Russia, Hungary and Belarus
What he loathes is any kind of democracy
Republicans against Trump@RpsAgainstTrump
“I hope he wins and I hope he wins big,” Trump released another video endorsing Hungary’s corrupt, autocratic leader, Viktor Orban, ahead of the April 12 election. Orban is firmly anti-Ukraine, which is why Trump and Putin are working overtime to help him win.
English