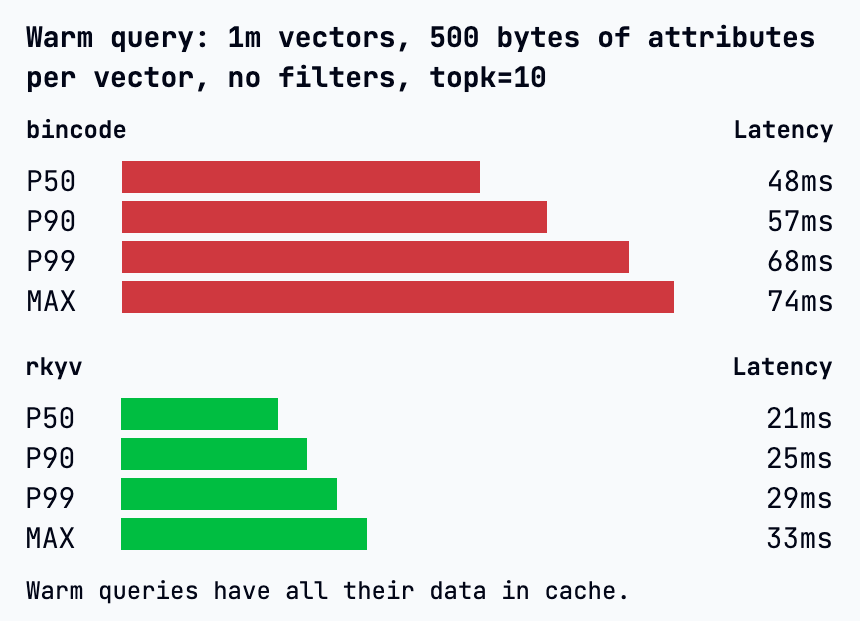
rkyv is a great rust library, query cpu consumption is down by ~65% since switching from bincode in @turbopuffer (depending on the traffic shape)
also has a big effect on bottom line query latency for large namespaces using attributes
Canadians, if you‘re considering switching to a heat pump to heat and cool your home, and you’re curious about utility bill costs, pay back period, and reduction in greenhouse gas emissions, I made a thing for you.
Link 👇
@harrybrundage It sounds like the entire goal of the PID is to target a specific, static heap size? Definitely viable, but why is it easier than changing the cache accounting to understand the heap size of entries?
More info: I have an LRU cache, I want to maximize its effectiveness, so I want to give it as much memory as I can. Entries don't take uniform memory though, and we control the number of entries in the cache, not the number of bytes available to it.
PID controller would adjust cache entry limit based on heap size
recent satisfying perf ships to @turbopuffer:
- flash-friendly fifo based cache, inspired by dl.acm.org/doi/pdf/10.114…; ~40% faster cache fills, reads/writes now saturate nvme
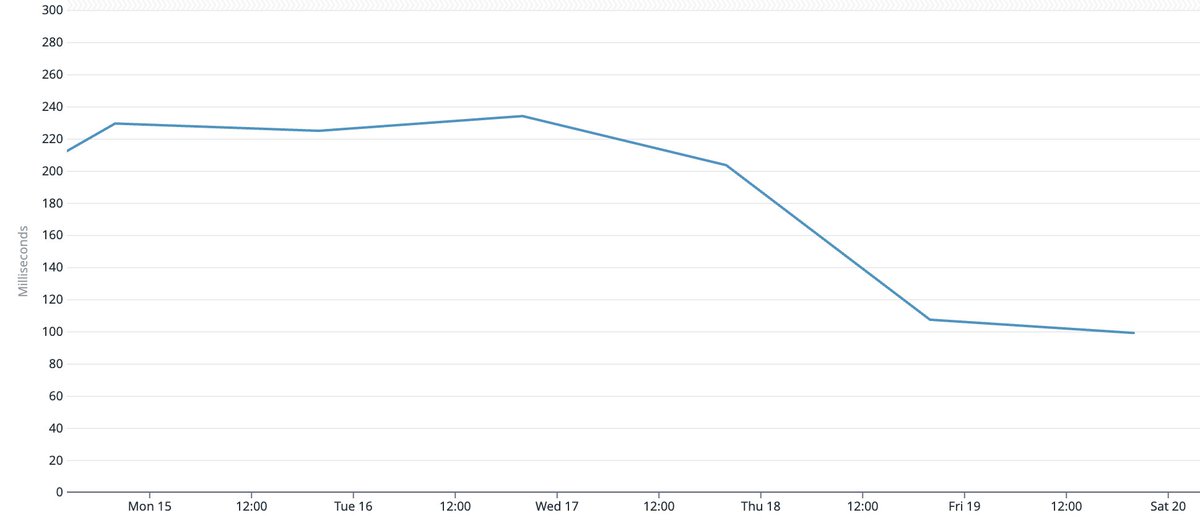
- new index compaction approach; up to ~70% faster cold queries
It’s still crazy to me how every screen recording I do in Vision Pro looks like one of those fake AR concepts that have plagued XR over the years
But no. This is all a device I can use daily. I really don’t think I can go back to anything else for productivity after this
@anotherjesse we're working on making the ID -> vector lookup at least 10x faster, some low hanging fruit we haven't addressed yet, thanks for exercising this feature 😃
I re-embedded huggingface.co/datasets/Journ… using SigLIP instead of CLIP
Additionally I normalized the embeds before saving them.
the similarly search results are significantly better
preview here: siglip.m4ke.workers.dev/?uuid=0b09c0d9…
- click an image searches near it
- click "random" at the top uses a random (seeded) vector as the search location
- the number next to random at the top is the distance to the 2nd item (because it would be 0 for the first when loading from UUID)
Additionally I'm using 2 new @turbopuffer features:
1. UUIDs instead of INT ids
2. filter by ID to load / search for items near a given ID.
The second requires 2 API calls to the turbopuffer API (the first to get the vector, and then a euclidean distance search from that vector for 50 items near it)
The additional call makes it feel a little slower (I've not gathered stats yet) - I wonder if that is something @Sirupsen and team will make faster.
@AdishwarR@jkeussen@Shopify@nextjs@shadcn@radix_ui good q - turbopuffer provides a serverless database, it's not running on serverless compute.
however, all durable data is directly stored in object storage; we can yank any server or scale up at any time and the system will continue to function fine without any downtime.
@jkeussen@Shopify@nextjs@shadcn@radix_ui I'm curious what serverless platform you built this on. Surely not your own?
Curious if it uses any Cloudflare tech underneath
The new turbopuffer.com website is live. My first dev+design project from scratch to production. Made in the 2 weeks since I left @Shopify. It's a @nextjs app with @shadcn@radix_ui components. I'll try to quickly summarize some of details...
@franklynd yeah that's pretty much it, though the cache is a bit more granular as the pages in the object store are huge and there's a natural way to split them up
first week at turbopuffer.com!
✅ tracing with datadog
✅ new rocksdb cache
✅ optimized cold queries
the slowest queries are so much faster that the cache doesn't have time to fill before the test finishes!
cache hits are serde dominated, zerocopy on the roadmap
@whitequark The compressors are set up in parallel and should both get oiled by the coolant return, assuming the correct POE oil is used.
This is giving me ideas for how to do cryocoolers for cheaper...
wonder how well do the compressors work in pair. it's def cheaper this way, and they're def not rated for it, but how bad is it really?
does one of them end up with All The Oil?
@mohammedri_ Intuition helps abstraction, generalization, and overall learning. Rigour overrides wrong intuition and improves it. Humans are effective by using both in a cycle.
@christianboutin Only time will tell how effective the current vaccine tech will be, but it’s obvious that without any vaccine coverage this virus is going to keep wreaking wide havoc.
@christianboutin As with all good science, independent groups and people come up with their models and projections, which are discussed on their merits, and a consensus may or may not emerge. Currently there is not a solid consensus on this topic. nature.com/articles/d4158…
The food pyramid is designed by the food industry to ensure consumption of production, and is therefore not related to health. So, who do you think the vaccination percentages required to get herd immunity is set by?
@Actinolite@thegedge Depending on how the music is written in it. Writing mostly eighth note triplets in 2/2 gives you a 6/8 grid and could be felt very similarly to 6/8 given the implied feel of 2/2.
@jlfwong I still think NFTs of this type are going to slip into obscurity. They're useful for other applications, but I think the value people are getting is significantly based on the novelty and not the intrinsic value. The rest of your wrong predictions overlooked big sources of value.
In this edition of The W Letters, two admissions of when I was very, very wrong, along with the curious case of the $600,000 GIF.
Where have your predictions been comically wrong?medium.com/the-w-letters/…