Angehefteter Tweet

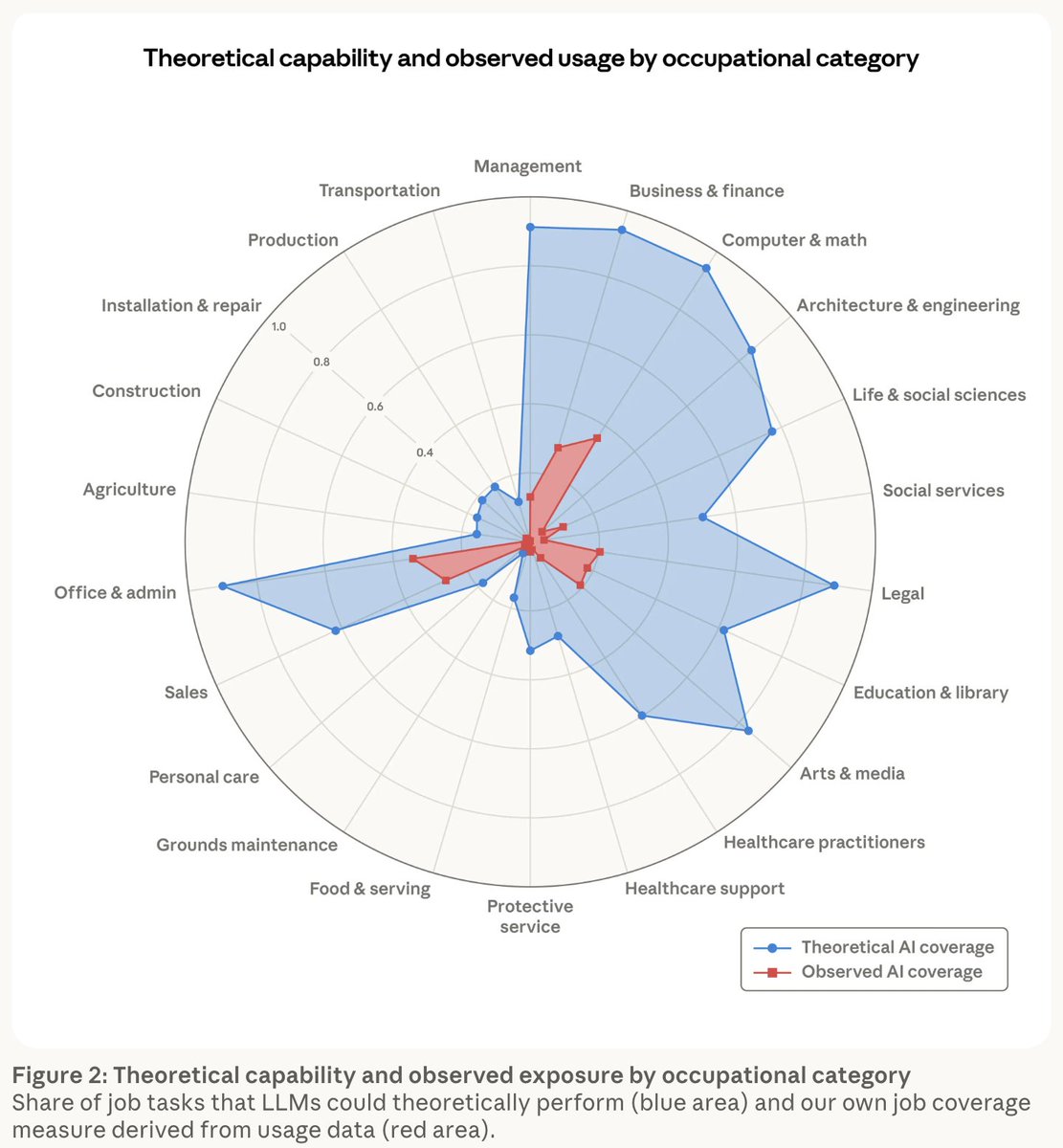
If a fact or chart is surprising, it might be because it’s new information, or it might be something deeper — a sign that our mental model is wrong. Anthropic’s economic gap chart is the latter. anthropic.com/research/labor…
A big source of confusion in AI discourse is not recognizing that the speed of adoption follows its own logic that’s far slower than the speed of capability progress. I’m biased but I think AI as Normal Technology is still the best exposition of the many different speed limits to diffusion. Once we internalize this, the gap shown in the chart is what we should expect.
How does this square with the “AI is the most rapidly adopted technology” narrative and all the graphs that are frequently shared to push that view? Unfortunately they lump together too many kinds of “AI use” to really tell us anything meaningful. On the one hand there are many marginal uses of AI (such as using chatbots instead of traditional search) that are being quickly adopted. But what will make a true economic impact are deeper changes to workflows that incorporate verification and accountability, manage the risk of deskilling, and are accompanied by organizational changes that take advantage of productivity improvements. Those changes happen at human timescales and are barely getting started. And that’s not even accounting for regulatory barriers.
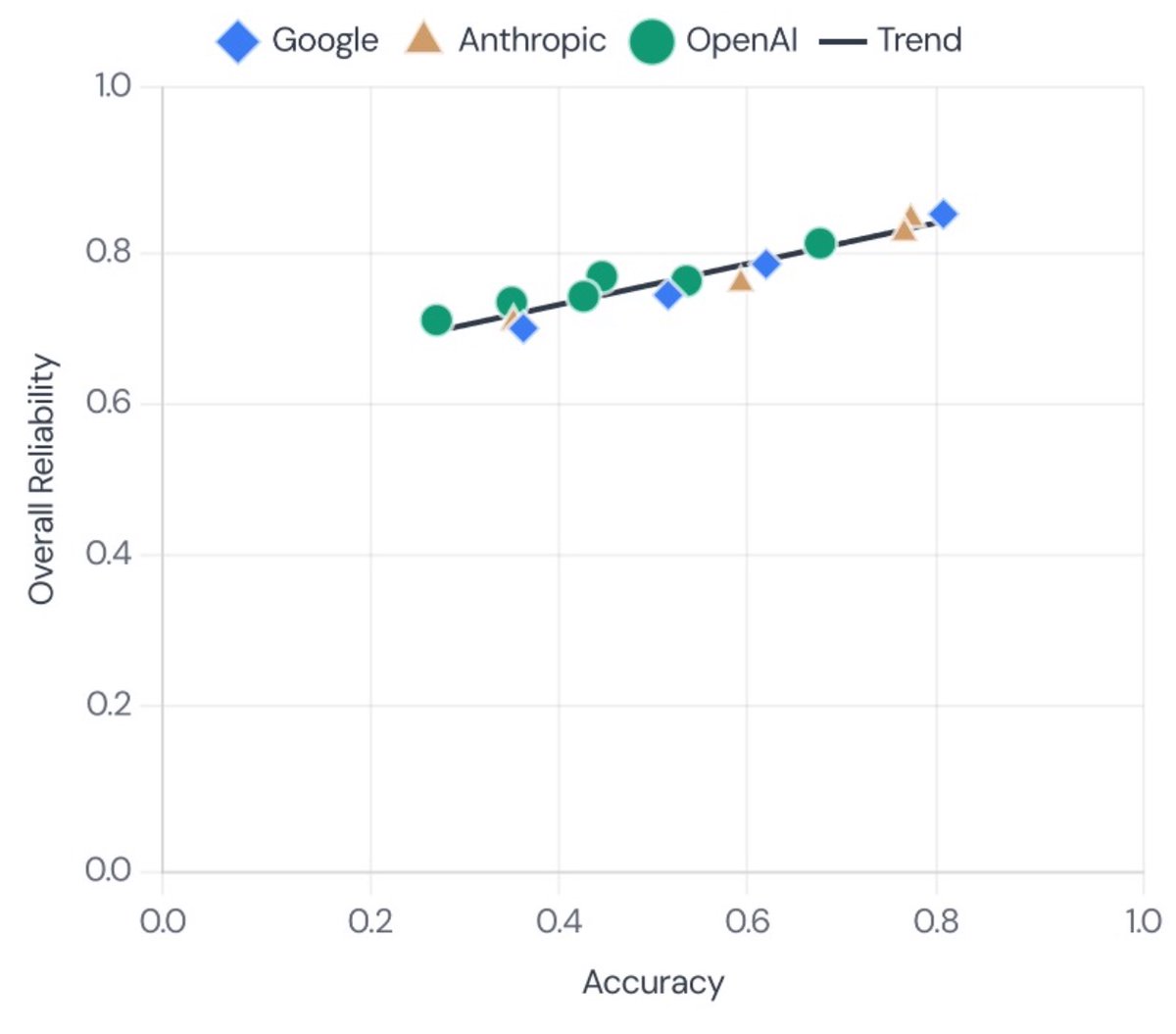
Finally, I’m also not sure how credible the “theoretical capability” estimates are. In particular, I don’t think they account for the capability-reliability gap, for which the AI community didn’t even have measurements until our work two weeks ago normaltech.ai/p/new-paper-to…
English