@iruletheworldmo I feel like it’s probably a solid analogy, just rather than lots of leaks, it’s the biggest leak ever
English
Reasoning Models
347 posts
@reasoningmodels
Reasoning models are cool I guess. Thoughts and ideas about reasoning models from the wacky mind of @morganlinton.





How can we autonomously improve LLM harnesses on problems humans are actively working on? Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores. Announcing Meta-Harness: a method for optimizing harnesses end-to-end
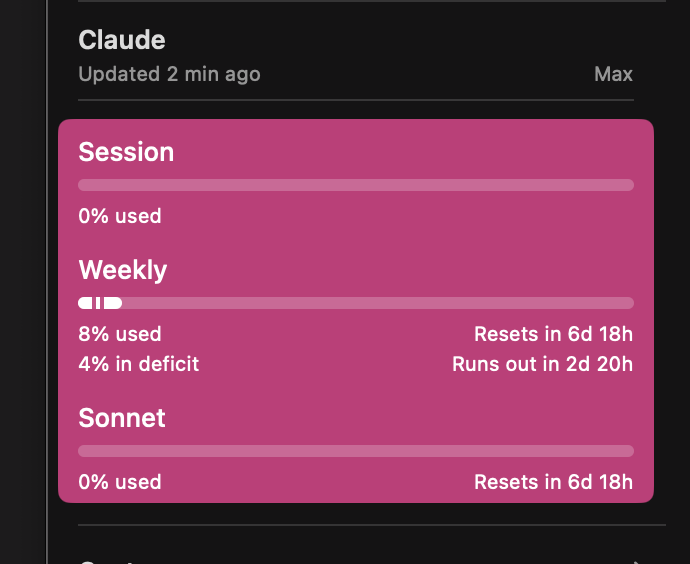
PSA: If you've been running out of Claude session quotas on Max tier, you're not alone. Read this. Some insane Redditor reverse engineered the Claude binaries with MITM to find 2 bugs that could have caused cache-invalidation. Tokens that aren't cached are 10x-20x more expensive and are killing your quota. If you're using your API keys with Claude this is even worse. This is also likely why this isn't uniform, while over 500 folks replied to me and said "me too", many (including me) didn't see this issue. There are 2 issues that are compounded here (per Redditor, I haven't independently confirmed this) : 1s bug he found is a string replacement bug in bun that invalidates cache. Apparently this has to do with the custom @bunjavascript binary that ships with standalone Claude CLI. The workaround there is to use Claude with `npx @anthropic-ai/claude-code` 2nd bug is worse, he claims that --resume always breaks cache. And there doesn't seem to be a workaround there, except pinning to a very old version (that will miss on tons of features) This bug is also documented on Github and confirmed by other folks. I won't entertain the conspiracy theories there that Anthropic "chooses" to ignore these bugs because it gets them more $$$, they are actively benefiting from everyone hitting as much cached tokens as possible, so this is absolutely a great find and it does align with my thoughts earlier. The very sudden spike in reporting for this, the non-uniform nature (some folks are completely fine, some folks are hitting quotas after saying "hey") definitely points to a bug. cc @trq212 @bcherny @_catwu for visibility in case this helps all of us.


My feed is showing me a bunch of folks who tapped out their whole usage limits on Mon/Tue. Is this your experience? Please comment, I want to understand how widespread this is



Excited to introduce ProRL Agent: Rollout-as-a-Service for RL training of multi-turn LLM agents! 🚀 As we move toward complex agentic tasks, rollout infrastructure is often a bottleneck. We’re decoupling I/O-heavy rollouts from GPU training via a unified HTTP API. Why ProRL Agent? Decoupled & Scalable: Treats rollout as a service, allowing near-linear throughput scaling. System-Level Optimization: Includes load balancing and automated sandbox cleanup for high stability. Integrated: Now part of NVIDIA NeMo Gym to help researchers scale RL pipelines faster. The Results 📈 On SWE-bench-Verified, we saw significant gains: +8.4 on Qwen3-8B +8.2 on Qwen3-14B Proven success across STEM, Math, and General Coding agents. Check out the research and open-source code: 📄 Paper: arxiv.org/pdf/2603.18815💻 Repo: github.com/NVIDIA-NeMo/Pr… Huge thanks to the team and NVIDIA for the support! 👏


Your headphones just became a personal translator in 70+ languages. 🎧✨ Google Translate’s “Live translate” with headphones is officially on iOS. We're also expanding this capability to more countries around the world for both @Android and iOS users. To try it, open the Translate app, tap “Live translate” and connect your headphones.

So.. I'd gotten a lot of complaints that GPT-5.4 is pretty hesitant to actually.. do the task presented to it, to call tools, etc. I have checked like 15 times now that we call it the same way we call Claude or any other model, and we do. Then I had hermes-agent look into it. It decided to check opencode and cline's codebase to see if maybe they do it differently. They don't - but they do prompt it differently.. lol


Every LLM from any lab today traces back to this guy, who was the only person at OpenAI pushing for pretraining transformer language models. He built GPT-1. After that did others see the potential. He invented it, and almost none of the so called AI experts even know his name.