Angehefteter Tweet

Bir gün insanlar Mars’ta yaşayacak. Orada doğacaklar, orada büyüdükten sonra orada ölecekler. Bazı insanlar ise evrenin bir diğer köşesinde…
Türkçe
Samet Karakaş
5K posts





Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.





Claude limiti dolduğu için kodun kalanını grok malına yazdırırken x.com/emrhna7essDB/s…


Telefondan sonra sıra bunu AI tarafında denemeye de gelmişti. Bakalım bu yeni model: > macOS/iOS için Swift yazabilecek mi? > Hono.js, React Router 7, Next.js tarafında iyi iş çıkarabilecek mi? > Electron-vite konusunda gerçekten güçlü mü?
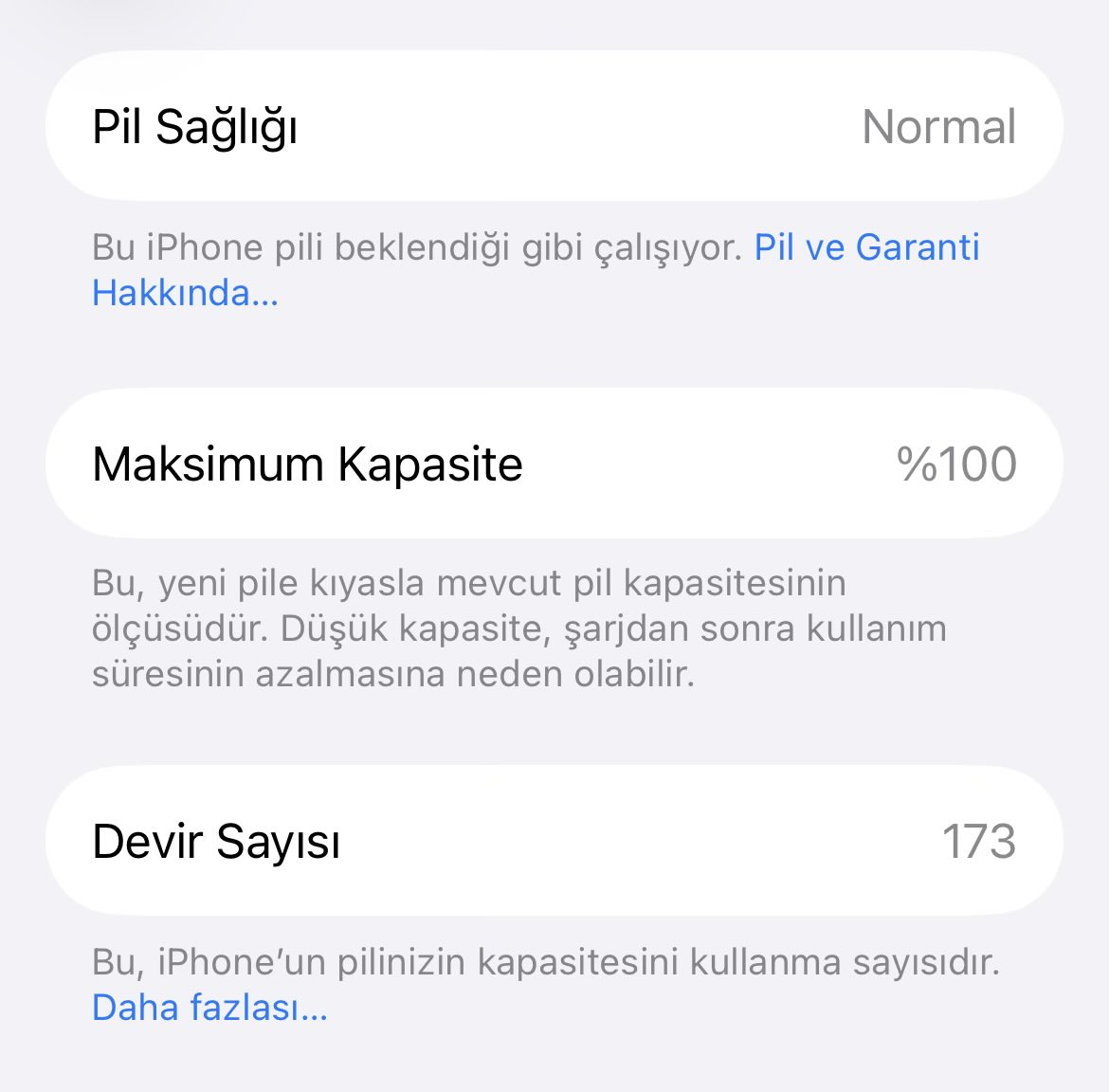
Hayat bitti.

I love how Codex doesn't stop the agent when your quota gets exhausted mid-task.

Apple will now include a charger in the box with every new iPhone purchase.

Kimi K2.6 denemelerime başladım. Sigarayı bırakıp AI modellerine başlayan ilk insan ben sanırım.






