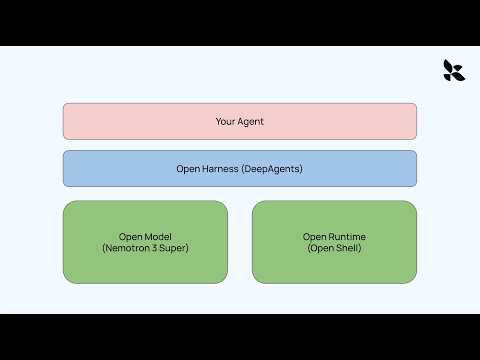
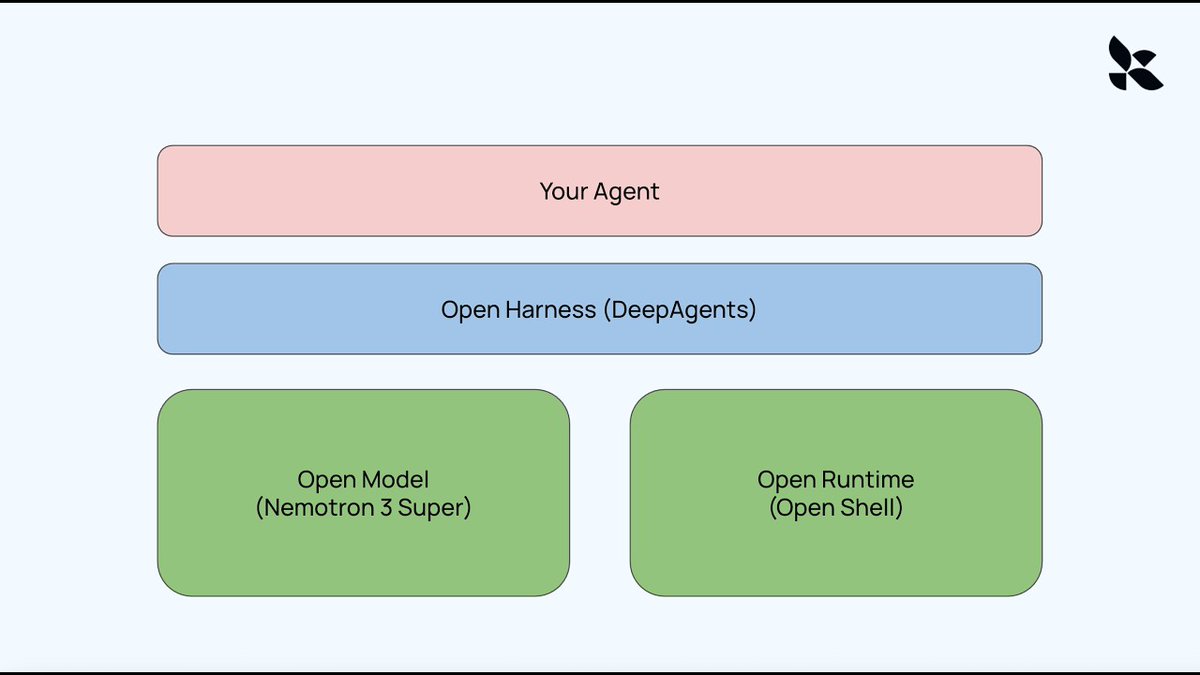
Pinned Tweet

I see a lot of feminized passive aggression, hatred and resentment that pervades so much of the modern content for consumption that's generated. Everything from movies released to series on network TV. The content machine. All further exploitation to generate revenue, ironically.
English