Most people are operating at about 10% of their actual potential. Not because they're lazy or stupid. Because they've been conditioned to use their minds in a very narrow way.
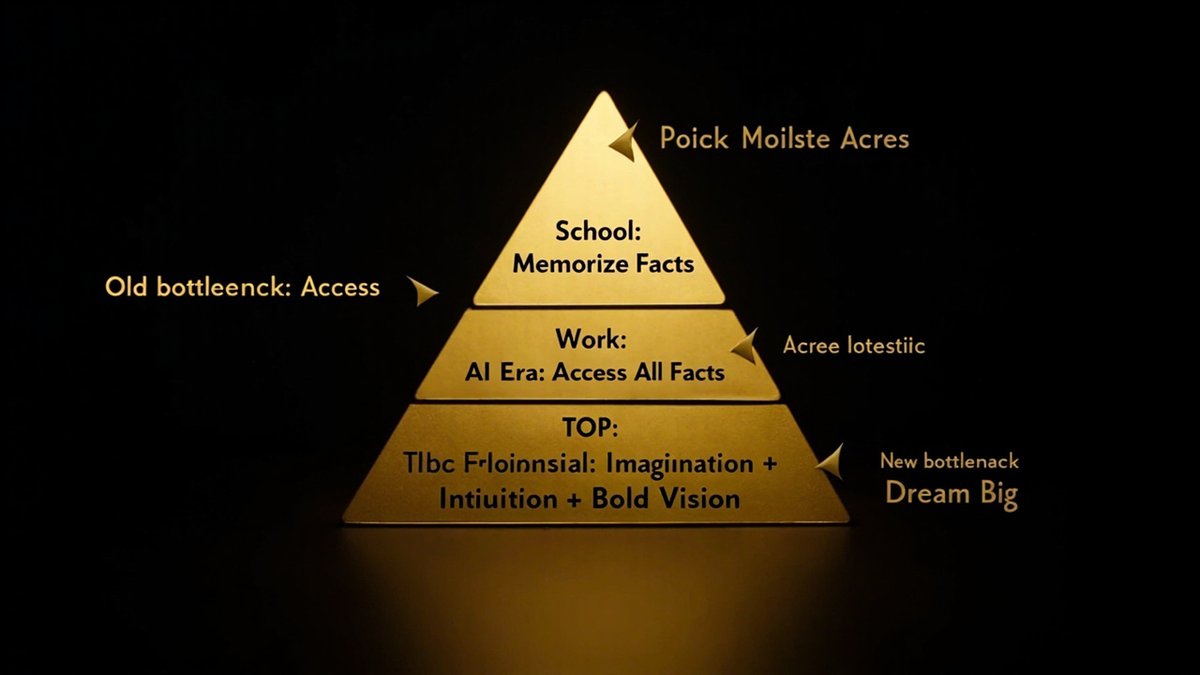
Think about how we train children in school. Sit still. Memorize facts. Repeat back what you were told. Don't ask why—just absorb. We train people to be receivers, not generators. To store information, not to create with it.
But the human mind is capable of so much more. It can perceive patterns that don't exist yet. It can hold a vision of the future and pull it into the present. It can connect ideas from completely unrelated domains and create something genuinely new.
The bottleneck was always access to information. That barrier is gone now. AI can surface any knowledge instantly. The new bottleneck is imagination. The new bottleneck is the courage to think what no one else is thinking.
The people who will thrive in this next era aren't the ones who memorized the most. They're the ones who can dream the biggest and have the nerve to pursue it.
English