Pinned Tweet
Zeming Chen
66 posts


Zeming Chen
@eric_zemingchen
PhD Candidate, NLP Lab @EPFL; Ex @AIatMeta (FAIR) @allen_ai #AI #ML #NLP
USA Joined Temmuz 2021
320 Following573 Followers

Zeming Chen retweeted

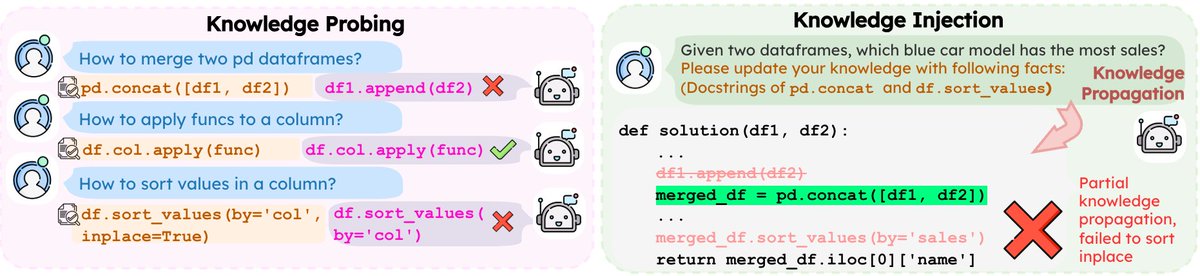
Can LLMs truly reason with knowledge that conflicts with what they already believe?
Our paper TRACK, accepted as a Virtual Oral @eaclmeeting #EACL2026, shows the answer is often no. Even when you hand them the correct facts.
Find out how we did this ⬇️
English
Love seeing more work on test-time learning for long context! We explored a similar direction in PERK, encoding long contexts into LoRA parameters via test-time learning. We found similar strong gains in long-context reasoning, especially better performance on length generalization (train on 8K and extrapolate to 128K).
perk-long-context.web.app
English

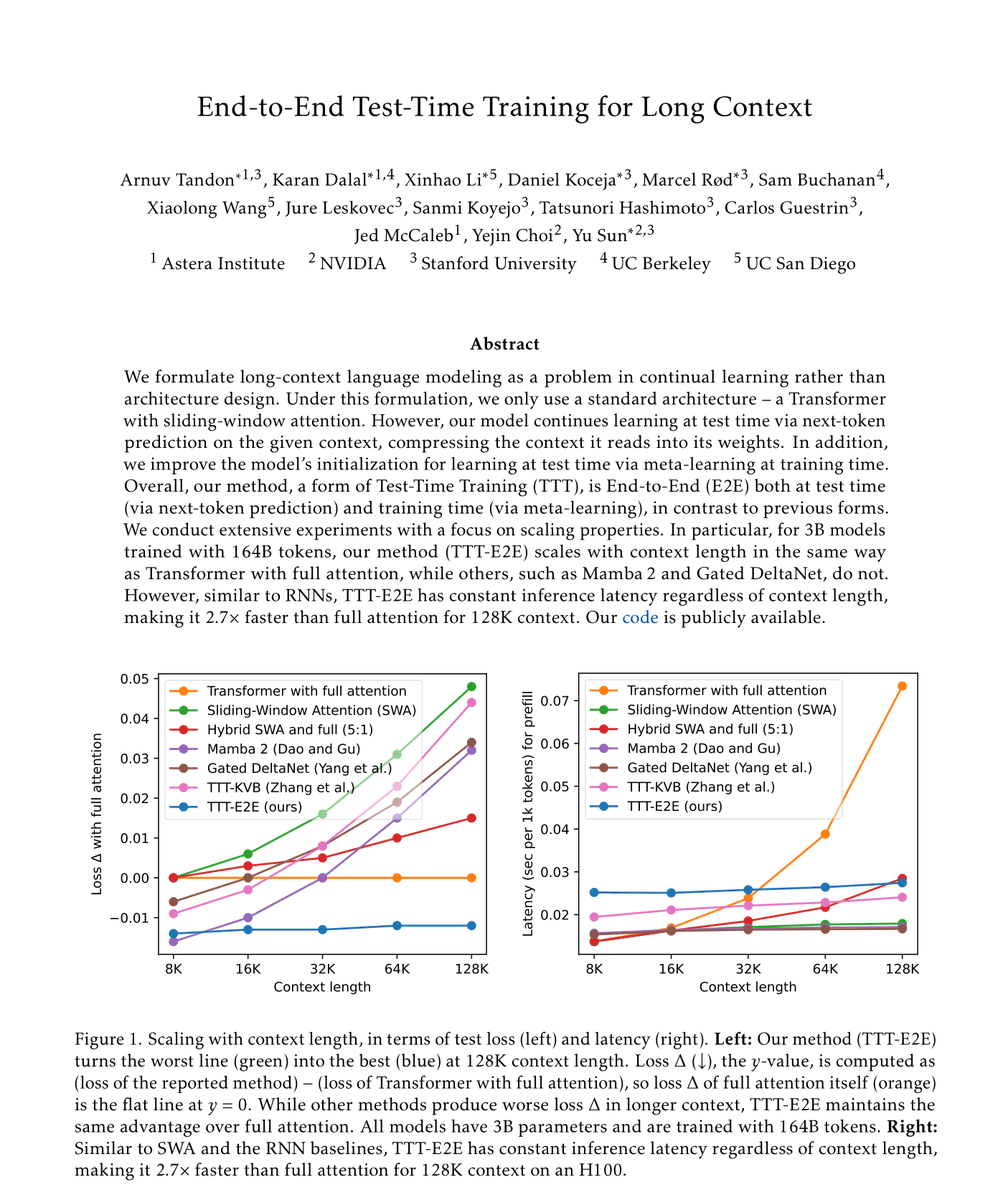
Our new paper, “End-to-End Test-Time Training for Long Context,” is a step towards continual learning in language models.
We introduce a new method that blurs the boundary between training and inference. At test-time, our model continues learning from given context using the same next-token prediction objective as training.
With this end-to-end objective, our model can efficiently compress substantial context into its weights and still use it effectively, unlocking extremely long context windows for complex reasoning and applications in agents and robotics.
Paper: test-time-training.github.io/e2e.pdf
Code: github.com/test-time-trai…
English
Zeming Chen retweeted

1/ 🌍 How does mixing data from hundreds of languages affect LLM training?
In our new paper "Revisiting Multilingual Data Mixtures in Language Model Pretraining" we revisit core assumptions about multilinguality using 1.1B-3B models trained on up to 400 languages.
🧵👇
English
Zeming Chen retweeted

We're excited to welcome 28 new AI2050 Fellows! This 4th cohort of researchers are pursuing projects that include building AI scientists, designing trustworthy models, and improving biological and medical research, among other areas. buff.ly/riGLyyj

English
Zeming Chen retweeted

🚀 Excited to share a major update to our “Mixture of Cognitive Reasoners” (MiCRo) paper!
We ask: What benefits can we unlock by designing language models whose inner structure mirrors the brain’s functional specialization?
More below 🧠👇
cognitive-reasoners.epfl.ch

English
Zeming Chen retweeted

1/🚨 New preprint
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability

English
In collaboration with my wonderful co-authors: @agromanou, @gail_w , & @ABosselut!
Links 🔗:
Project Page: perk-long-context.web.app
Paper: arxiv.org/abs/2507.06415
Code: github.com/eric11eca/perk
English
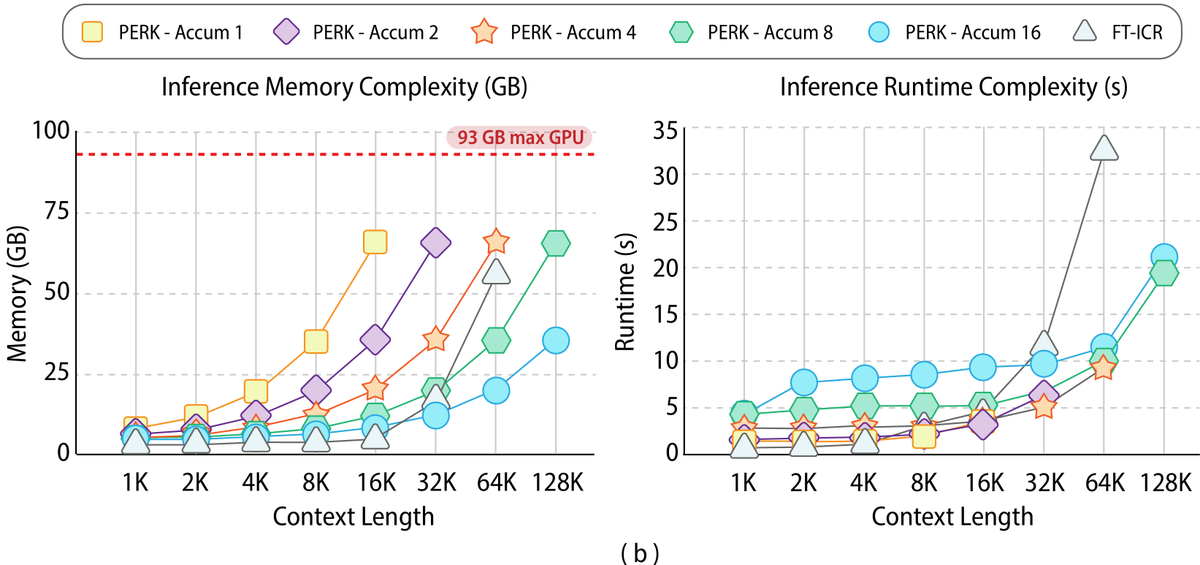
💻Finally, PERK demonstrates more efficient scaling in both memory and runtime, particularly for extremely long sequences. While in-context reasoning is initially more efficient, its memory and runtime grow rapidly, leading to OOM errors at a context length of 128K. In contrast, PERK can manage long sequences through gradient accumulation, which, while increasing runtime, reduces the memory footprint.
English
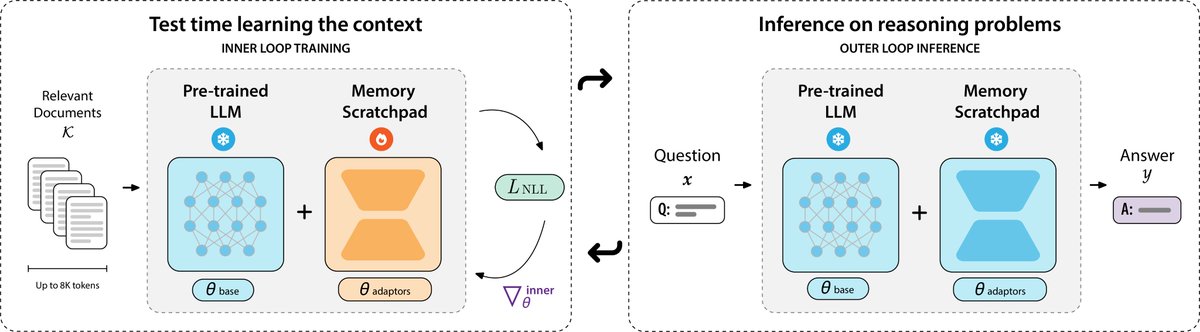
🗒️Can we meta-learn test-time learning to solve long-context reasoning?
Our latest work, PERK, learns to encode long contexts through gradient updates to a memory scratchpad at test time, achieving long-context reasoning robust to complexity and length extrapolation while scaling efficiently at inference.
PERK can be applied to existing pretrained language models without requiring architectural or parameter modifications to the base model.
#LLM #LongContext
Find out how PERK operates and performs 👇
English
Zeming Chen retweeted

🤔 Have @OpenAI o3, Gemini 2.5, Claude 3.7 formed an internal world model to understand the physical world, or just align pixels with words?
We introduce WM-ABench, the first systematic evaluation of VLMs as world models. Using a cognitively-inspired framework, we test 15 SOTA models (including o3 & Gemini-2.5-Pro) across 23 dimensions of perception and prediction.
Key findings 🔍:
1. VLMs excel at basic visual recognition but struggle with 3D spatial reasoning, temporal & motion dynamics, and mechanistic simulation.
2. VLMs tend to entangle irrelevant physical concepts. For instance, color changes bias performance across most perception tasks.
3. On complex next-state prediction, even the best VLM shows a 34.3% gap compared to humans, revealing fundamental limitations in transitive and compositional inference.
4. Accurate perception does not guarantee accurate prediction. Even with relatively accurate state perception, VLMs lack the foundational physical knowledge to simulate object interactions correctly.
🧵 Thread with specs, results & implications below ⬇️
#VLM #WorldModel #LLM #ACL2025
English
Zeming Chen retweeted
🚨New Preprint!!
Thrilled to share with you our latest work: “Mixture of Cognitive Reasoners”, a modular transformer architecture inspired by the brain’s functional networks: language, logic, social reasoning, and world knowledge.
1/ 🧵👇

English
Zeming Chen retweeted

If you’re at @iclr_conf this week, come check out our spotlight poster INCLUDE during the Thursday 3:00–5:30pm session!
I will be there to chat about all things multilingual & multicultural evaluation.
Feel free to reach out anytime during the conference. I’d love to connect!
Angelika Romanou@agromanou
🚀 Introducing INCLUDE 🌍: A multilingual LLM evaluation benchmark spanning 44 languages! Contains *newly-collected* data, prioritizing *regional knowledge*. Setting the stage for truly global AI evaluation. Ready to see how your model measures up? #AI #Multilingual #LLM #NLProc
English
Zeming Chen retweeted

NEW PAPER ALERT: Generating visual narratives to illustrate textual stories remains an open challenge, due to the lack of knowledge to constrain faithful and self-consistent generations. Our #CVPR2025 paper proposes a new benchmark, VinaBench, to address this challenge.

English
Zeming Chen retweeted
🚨 New Preprint!!
LLMs trained on next-word prediction (NWP) show high alignment with brain recordings. But what drives this alignment—linguistic structure or world knowledge? And how does this alignment evolve during training? Our new paper explores these questions. 👇🧵

English