
fairseq retweeted

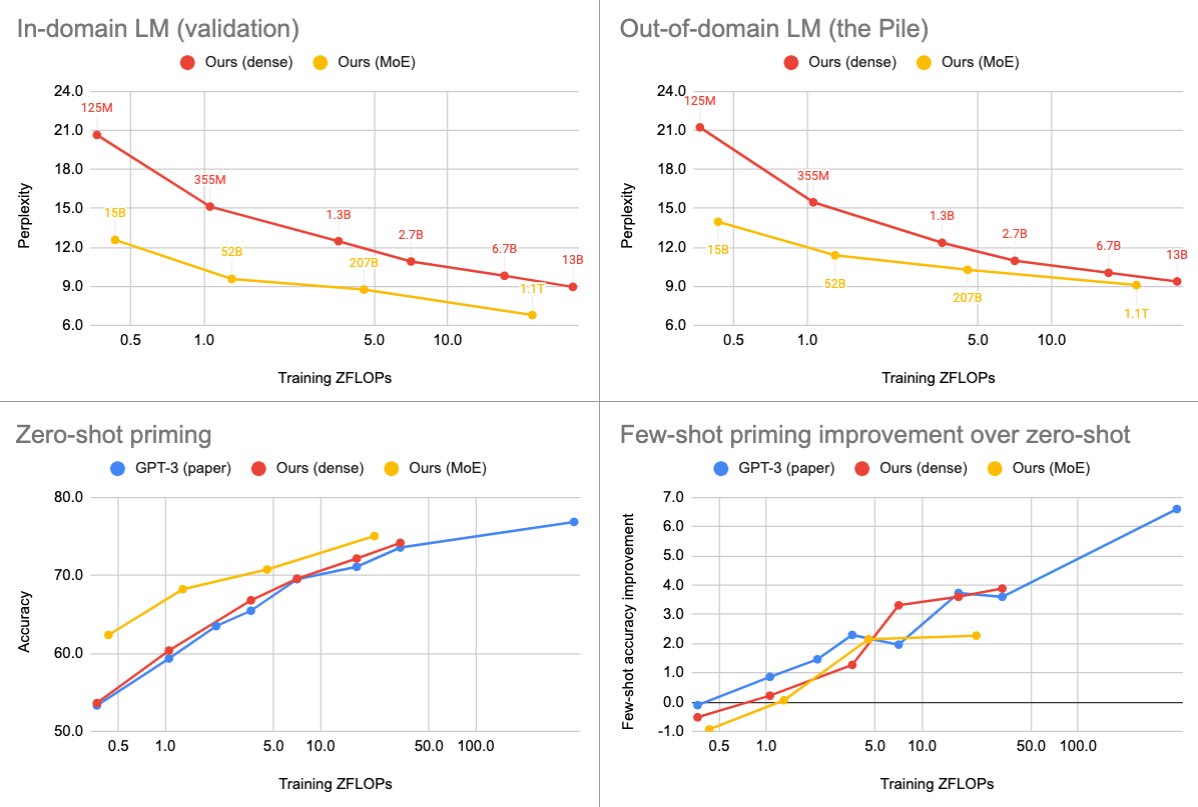
We are releasing a family of dense and MoE language models with up to 13B and 1.1T parameters. We find that MoEs are more efficient, but the gap narrows at scale and varies greatly across domains and tasks.
Paper: arxiv.org/abs/2112.10684
Models & code: github.com/pytorch/fairse…
English





