H2O
578 posts


H2O retweeted

🚀 Codex app update
🌐 Codex Chrome extension
⚡ Parallel background work across tabs, no browser takeover
🔒 Per-site access controls
Changelog: #codex-2026-05-07" target="_blank" rel="nofollow noopener">developers.openai.com/codex/changelo…
English
H2O retweeted

这是我今年装到 Codex 里最爽的一个 skill,没有之一,强烈推荐大家安装一下。
一个不到 1k stars 的小项目,把独立开发最容易死的那一环给补上了。
独立开发时常面临的死亡循环:找 idea → 开干 → 没人用 → emo → 重复
中间被跳过的很重要的一步叫 validation,99% 的人靠”我觉得有用”代替了它。
一行命令安装到 Codex:
npx --yes codex-startup-pressure-test-skill@latest
把 你的idea 丢进去,它会用创始人视角给你压测:
✅ 核心假设 + 致命缺陷
✅ 真痛点还是你的幻觉
✅ 真实竞品 + 切换成本
✅ 前 10 个客户从哪来
✅ 2 周能跑完的 MVP
✅ 直接判 strong / weak / pivot
我突然意识到,它刚好补上了 reddtrends 的下游缺口:
Reddtrends 挖 Reddit 真实痛点 → skill验证 → Codex 写代码
idea → 验证 → 落地,第一次三段全闭环。
Cursor 和 Claude Code 解决“怎么 build”的问题,Reddtrends + 这个 skill 解决“build 什么”。
后者才是 90% 独立开发者真正死掉的地方。
中文
H2O retweeted

OpenAI Agent SDK 杀疯了!「Harness/Compute分离」架构,彻底解决长时程Agent的安全与可扩展性痛点🔥
OpenAI 这次 Agents SDK 大更新,直接把企业级 Agent 架构的「教科书级」设计公开了——核心就是这张图里的 Harness 与 Compute 分离架构,完美解决了困扰 Agent 开发者的两大难题:
安全隔离 & 长时程稳定运行。
🧩 核心架构拆解:
这张图把 Agent 系统拆成了两个完全独立、但又协同工作的模块,每一层的职责都极度清晰:
• 左侧:可信层(Harness + Secrets)
这是你的「信任大本营」,跑在你可控的可信环境里(支持 Temporal、AWS、Azure 等任何平台),完全不暴露给外部沙箱:
✅ 管理所有敏感凭证、API Key,彻底杜绝沙箱代码泄露密钥的风险
✅ 控制 Agent Loop 调度、MCPS/Tools 编排,决定什么时候调用模型、什么时候触发工具
✅ 负责与外部数据库、API、公网的交互,所有高权限操作都在这里完成
• 右侧:计算层(Sandbox + 存储)
这是「隔离的执行沙箱」,专门跑模型生成的代码、Shell 命令、文件操作:
✅ 支持 OpenAI 官方沙箱、E2B、Vercel 等 7 种主流沙箱环境,可按需选择
✅ 支持本地/挂载式文件系统,无缝对接 S3、Azure Blob、GCP 等云存储
✅ 沙箱里只有执行权限,没有任何高敏感凭证,就算被注入攻击也不会造成太大影响
🔑 这一架构,到底解决了什么痛点?
1. 安全隔离:把风险锁在笼子里
传统架构中,Agent 代码跑在哪,密钥就必须在哪,一旦被 Prompt Injection 攻击,密钥直接泄露。而现在,Harness 层只在可信环境里,沙箱层只负责执行,就算沙箱被攻破,也拿不到任何核心凭证,完美实现了「最小权限原则」。
2. 持久化与长时程执行:再也不怕任务中断
Harness 层和 Compute 层分离后,Agent 的状态、进度可以独立保存到文件系统/云存储中,就算沙箱重启、崩溃,也能从断点恢复,支持几小时甚至几天的长任务,这是传统 Agent 架构做不到的。
3. 可移植性拉满:哪里都能跑
不管是 Harness 层还是 Sandbox 层,都支持跨平台部署,你可以把 Harness 跑在本地,沙箱跑在 E2B 云环境;也可以全部部署在 AWS/Azure,不用被单一平台绑定。
4. 调试与审计更简单
所有高权限操作、外部请求都集中在 Harness 层,日志和审计追踪可以统一在这里做,沙箱层只负责执行,排查问题时不用在复杂的沙箱环境里翻日志。
💡 对开发者来说,这意味着什么?
简单说,OpenAI 把他们在 Codex 上踩过的坑、验证过的最佳实践,直接做成了开箱即用的架构:
• 不用再自己从零搭沙箱隔离、密钥管理、状态持久化了,SDK 直接给你做好了
• 可以放心让 Agent 跑复杂代码、Shell 命令,不用再担心里层泄露、环境被污染
• 长任务终于有了可靠的断点续跑能力,再也不用因为一次网络波动重头再来
#OpenAI #AgentSDK #AI架构 #开发者工具 #LLM
OpenAI Developers@OpenAIDevs
Build long-running agents with more control over agent execution. New capabilities in the Agents SDK: • Run agents in controlled sandboxes • Inspect and customize the open-source harness • Control when memories are created and where they’re stored
中文
H2O retweeted

Codex确实是真的牛!
我已经听到很多人卸载了OpenClaw和Hermes Agent了
下面这个案例,结合HypesFrames
动效、转场、字幕、配音全自动,不满意继续口喷 !
爱丽丝呀!@BTCqzy1
【Codex 真的牛!】 还在剪映里一帧一帧手动抠视频? 醒醒,AI已经把剪辑效率卷疯了 我只在 Codex 里敲了一行字,装上 HyperFrames 插件, 一句话就能生成想要的任何视频。 动效、转场、字幕、配音全自动,不满意继续打字改就行,秒出新版本。 还可以批量生成。 下面这个视频是我让codex生成 【人类编程进化史】的视频,太酷了~ 用会 Codex,你就真正打开了 AI 内容创作的新世界大门。 我强烈建议所有自媒体人、内容创作者都要学会codex,这套玩法真的能把效率直接拉高十倍。 还有更多玩法,以后分享哦~
中文
H2O retweeted

中国人做的开源项目越来越好了!
这周我想好好尝试两个项目:
1. OpenDesign: Claude Design的开源平替,本地部署自由接入各种模型做设计,包括PPT,Web,GUI,对我来说挺需要的;
2. CC-Connect:把各种Agent接入到远程Channel上。有了这个,感觉完全不需要OpenClaw了。强烈推荐!
中文
H2O retweeted

H2O retweeted

分享一个最近一直在用的 skill,让你的 Codex App 不再越用越卡
核心就是四件事:
- 归档超过 7 天、不再继续的旧对话
- 把有价值的旧项目对话写成交接文档后再归档
- 定期清理旧的运行记录,保持日志轻量
- 清理失效项目路径,归档残留 worktree
装上之后可以在 Codex 里面设置成每周一次的自动化,定时清理
🔗:github.com/vibeforge1111/…

中文


H2O retweeted

强烈推荐大家看看DeepMind CEO Demis的最新判断。
真的,Google DeepMind 的 CEO Demis Hassabis 每一期访谈我觉得值得都花时间看看。这哥们讲东西很实在,而且通俗易懂。
早上边跑步边听完了他和 YC CEO Garry Tan 的最新一期播客。
刚刚把笔记写完,也给大家分享下。
多说一句,好多人问我这种笔记是不是 AI 写的。我说下自己的流程。
我会先完整听完播客,然后用语音输入法把感触尽量充分地讲出来,再让 AI 帮着整理初稿,最后自己逐字修改优化。
如果全部交给 AI 做总结,那等于把思考和理解的能力让渡给了 AI,对自己理解这件事其实没有任何价值。
OK,咱们进正题。
1
Demis 的态度非常明确,现在的大模型范式(大规模预训练 + RLHF + CoT)一定会是 AGI 最终架构的一部分,他不认为这会是条死路。
但要实现 AGI,还有几个关键问题要解决。这几个问题包括:持续学习、长程推理和记忆系统。
先从最容易看到的现象讲起,Context Window。
现在大模型处理长信息,最常用的招就是把 Context Window 一直撑大。一开始 8k,后来 32k,再后来 100 万 Token。听起来很厉害,但本质上是暴力堆砌。
Context Window 其实就相当于人脑里的 Working Memory,工作记忆。人的工作记忆能同时装多少东西?心理学里有个经典数字,7 个左右。背电话号码能记住 7 位上下,再多就溢出了。
大模型呢?已经做到 100 万 Token。
按理说,模型的工作记忆比人大几十万倍,应该比人聪明几十万倍才对。但显然不是。
问题也恰恰就出现在这。把所有东西都塞进 Context Window 里,里面包含了不重要的东西、错的东西、过时的东西。看起来信息很多,其实是一团乱麻。
那人为什么 7 个数字的工作记忆就够用?
因为人脑背后还有另一套机制在工作。我们记得几年前的事,记得童年的事,记得几小时前发生的事。这些都不塞在工作记忆里,而是另一套系统。
具体来说这套系统是海马体,大脑里负责把新知识整合进已有知识库的那个部分。
研究发现,人睡觉的时候,特别是 REM 睡眠阶段,大脑会重放白天重要的片段,让大脑从中学习。新东西在睡觉的过程里,温柔地融进了旧的知识体系。
这个把新东西融进旧知识库的过程,就是持续学习。
模型现在没有这套机制。每一次对话结束,刚学到的东西就会忘记。下次重新打开,还是上次那个模型,没长进。
2
再聊聊长程推理的问题。英文表达是 Long-term Reasoning。我翻译为了长程。
长程推理这个词太抽象了。Demis 讲了一个特别具体的故事,听完会立刻明白他说的是什么。
他说自己喜欢跟 Gemini 下国际象棋。下棋的过程里能看到模型的 thinking trace,也就是它在那里到底想了什么。
然后他发现一件怪事。
模型考虑一步棋的时候,思考链里清清楚楚写着,这步是个昏招。但接下来,它没找到更好的走法,于是又走回这步昏招。
明明知道是错的,还是把错的那一步走出去了。
这个细节比任何 benchmark 数据都说明问题。因为它暴露的是模型缺少对自己思考过程的某种内省能力。
正常人下棋,意识到一步是昏招之后,脑子里会有一个反应,停一下,再想想。停一下、再想想这个能力,模型现在没有。它能在每一步局部判断对错,但没法基于整盘棋的局势去调整整体策略。
这就是长程推理还没搞定的样子。模型可以一步一步往前走,每一步看起来都合理,但走到后面整盘棋的方向其实是错的。它没有那种退回到当前思考的上一层、重新审视一下的能力。
说到底,模型缺的是一种内省。
3
学习、长程推理、记忆,这是 Demis 在播客里点出来的三个 AGI 鸿沟。
除此之外,他还反复提到了创造力。
2016 年 AlphaGo 跟李世石下棋,第二局走出了著名的 Move 37。那一步棋走出来的瞬间,全世界的围棋高手都看呆了。
所有人类几千年下围棋积累的经验都告诉它不该下那里,但 AlphaGo 下了。下完之后大家发现,是一步神来之笔。
很多人觉得,这就是 AI 的创造力来了。
但 Demis 说,对他自己来说,Move 37 只是起点。他真正想看到的是另一件事。AI 能不能发明围棋这件事本身。
这两件事的区别非常关键。
Move 37 是在围棋这个现成的规则里,找到了一步人类没想到的招。但围棋的规则、棋盘的形状、黑白子的对弈方式,是人类发明出来的。AI 在已有的框架里非常厉害,但能不能自己造一个框架,是另外一回事。
Demis 给了一个具体的设想。
如果给 AI 一个高层次的描述。造一个游戏,五分钟能学会规则,要好几辈子才能精通,棋局有审美,一下午能下完一局。AI 能不能根据这个描述,自己倒推出围棋?
目前做不到。
为了把这件事讲得更清楚,Demis 还提了一个测试,他自己叫爱因斯坦测试。
用 1901 年人类已有的全部知识训练一个模型,看它能不能在 1905 年那个时间点,自己推出狭义相对论。
爱因斯坦在 1905 年那一年里,连写了几篇改变物理学的论文,后来叫爱因斯坦奇迹年。那些工作不是从已有的物理学论文里通过拼接得到的,是基于已有材料做了一次全新的概念跳跃。
爱因斯坦测试想问的就是这件事。AI 能不能做这种跳跃。
目前的大模型主要在做两件事,pattern matching 和 extrapolation。一个是从大量数据里找规律,一个是把规律往外延伸一点。但发现新东西需要的是类比推理的能力。从一个领域里抽出深层结构,搬到另一个全新的领域去用。
这个能力,模型现在还没有。也可能是有,但用法不对所以激发不出来。
4
除此之外,Demis 还分享了一个让我特别出乎意料的判断,他说未来 6 到 12 个月,真正的价值不在更大的模型,在更小的模型。
这一部分内容我反复听了好几次,确实突破我的已有认知。
不知道大家的想法,反正我自己,这一年来并没有怎么关注小模型的进展。毕竟行业的焦点就是把模型做大嘛。
那小模型的价值到底在哪?
最直接的是成本。同样一个任务,小模型的推理价格可能只是前沿模型的十分之一甚至更少。
但 Demis 说,比成本更重要的其实是速度。
这里有一个前提得先说清楚。Demis 不是在说速度可以替代智能。
他的原话是,当小模型的能力已经达到前沿模型的 90% 到 95%,也就是已经相当不错的时候,剩下那 5% 到 10% 的能力差距,比不上速度带来的好处。
比如现在工程师用 AI 写代码,已经形成了一种新的工作节奏。一个想法冒出来,几秒之内就能看到结果,不行就改,再不行再改。
这个一改再改的循环跑得越快,做出来的东西就越好。如果每次调用都要等十秒,整个工作流就被打断了。
更关键的是,快到一定程度,工程师在这种节奏里能进入心流。一个想法、一次尝试、一个反馈、再来一个想法,思维不被打断。
这件事写过代码的人都懂,进入心流和频繁掉出心流,产出的差距是数量级的。
Agent 也是同样的逻辑。一个 Agent 跑完一个任务可能要调几十次模型,每次慢一秒,整个任务就慢一分钟。慢到一定程度,Agent 就从一个能用的东西变成鸡肋。
小模型不是大模型的廉价替代品。有些事只有小模型能做。
比如手机、眼镜、家用机器人,需要的就是一个能在本地跑起来的模型。本地跑除了反应快,还有一个特别重要的好处,隐私。
家里机器人看到的视频、听到的对话,全部在设备本地处理,根本不上云。这件事对很多用户来说不是加分项,是底线。
成本、速度、边缘部署,这是小模型的价值。
5
讲完小模型的价值,接下来一个更关键的问题是,能力被压到这么小的参数里,会不会有上限?
Demis 的判断是,目前没看到信息密度有任何理论上限。小模型的智能天花板还远没看到。
支撑这个判断的,是 DeepMind 在蒸馏这件事上的积累。蒸馏简单说就是先训练一个超大的模型,然后用这个超大模型去教一个小模型。教完之后,小模型用极少的参数,能复现原来 95% 以上的能力。
为什么 DeepMind 这么重视蒸馏?因为要把 AI 能力放进谷歌的头部产品中,前提是低延迟、低成本。前沿模型再强,每次推理花几秒钟、花几毛钱...这条路,恐怕很难走得通。
一个前沿模型发布之后,6 到 12 个月内,他们就能把这个模型的能力蒸馏到边缘设备能跑的小模型上去。这个时间表比很多人想的要快。
在很多场景中,小模型和大模型会相互配合。
举个例子,一个端到端的智能助手,绝大部分日常任务在本地的小模型上跑。智能眼镜看到的画面、家里机器人听到的对话、手机里的私人助理,模型直接在设备里读懂,不需要往云端传一遍。
只有遇到特别复杂、本地搞不定的问题,才向云端的前沿模型发起请求。
也就是说小模型在边缘做主力,前沿模型在云端做后援。
不过,这个构想对小模型的要求也比较高,它不能只会处理文字,还得能理解物理世界。
这就是为什么 Gemini 从一开始就坚持多模态,不光处理文字,也处理图像、视频、声音。
一开始这么做比只做文本要难得多,但眼镜也好,机器人也好,需要的是一个能看懂周围世界的模型,不是一个只会聊天的模型。
讲到这里,小模型这条路的轮廓就完全清楚了。它独立成立,不是前沿模型的廉价替代品,而是另一条同样重要的路。
嗯,很有启发。
中文


H2O retweeted
Learn about Codex pets before adopting your own:
#codex-pets" target="_blank" rel="nofollow noopener">developers.openai.com/codex/app/sett…
English
H2O retweeted

鲸鱼兄弟们好,我是做 DeepSeek-TUI 的那个美国佬。
说真的,特别想跟国内的鲸鱼兄弟们一起混——但我的翻墙技能仅限于写代码,微信到现在都没搞定,属实有点丢人。
求各位大佬帮个忙:
1)帮忙转发扩散一下,让这个开源终端工具翻过高墙被兄弟们看到
2)顺手帮我验证个微信号,我想建个群,大家一起聊 DeepSeek、聊开源、聊怎么把 agent 做得更好
作为交换,我发誓死守 cargo install 这条安装路径,绝不让任何一个兄弟受 npm 的苦。
顺带一提,这段话是 DeepSeek 帮我润色的——感谢鲸鱼赐我流利中文 🙏
github.com/Hmbown/DeepSee…
中文
H2O retweeted

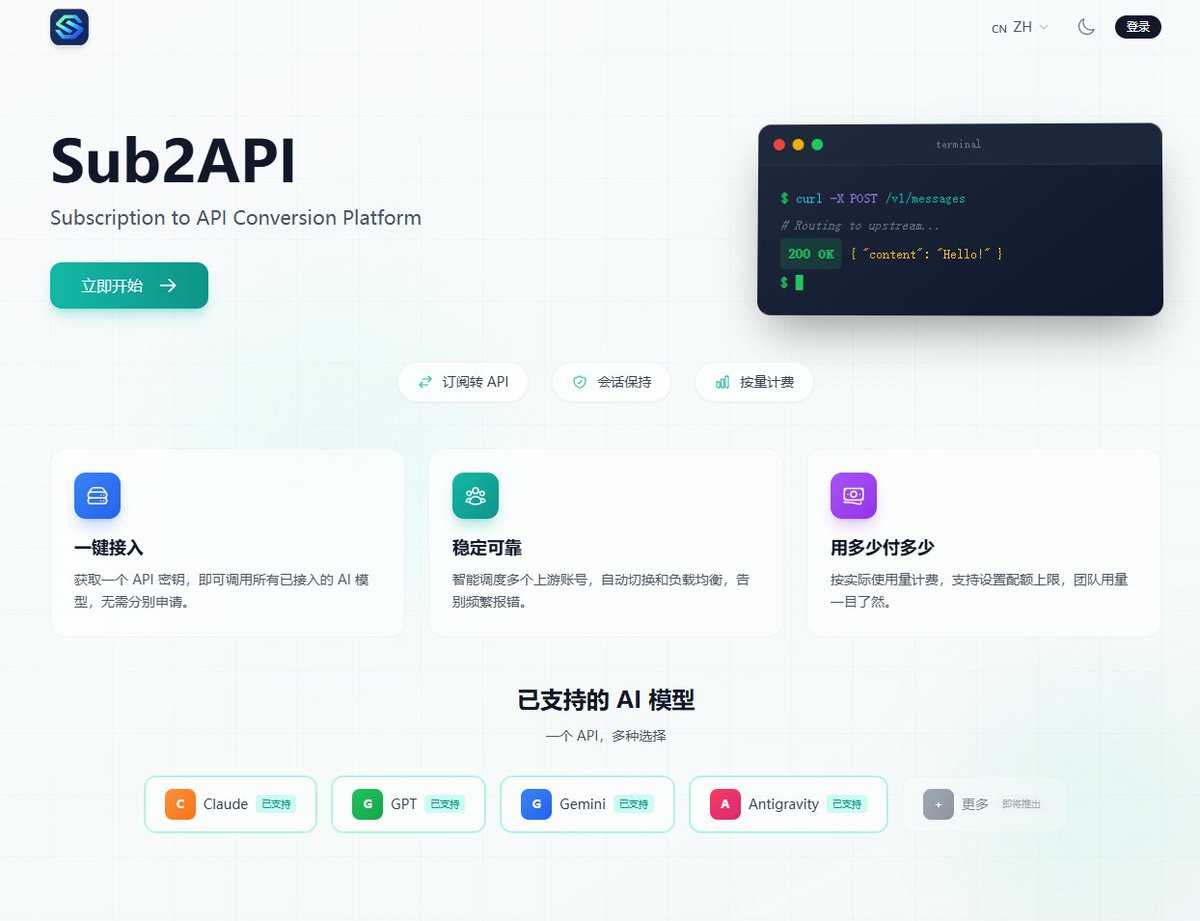
最近推上不少人在做 API 中转站,去 Github 翻了一下
发现一个开源项目挺火,现在不少跑的中转站都是基于它魔改的
Sub2API,目前 15.5K star,完全开源免费,它可以让你快速拥有属于自己的中转站
不管是 Claude Opus 还是 GPT-5.4,市面上能想到的主流模型,它都能一站式接入
剩下的问题就是 Token 怎么来——配套有免费的薅羊毛脚本,每天自动跑100个账号白嫖 GPT-5.5额度
Token 多到用不完的话,可以分享给家人朋友用,也可以挂出去卖
技术门槛不高,自己用够了,做副业也可以
链接和演示网站丢评论区了,喜欢的自取~
中文
H2O retweeted

H2O retweeted

H2O retweeted

H2O retweeted

H2O retweeted

《GPT Plus 代充漏洞技术解构:iOS 收据校验缺陷与灰产套利链路全拆解》
典型的支付逻辑漏洞:onefly.top/posts/chatgpt-…
中文
H2O retweeted
