
Eigen retuiteado

An agent that beats Claude Mythos on Terminal Bench and SWE-bench Verified?
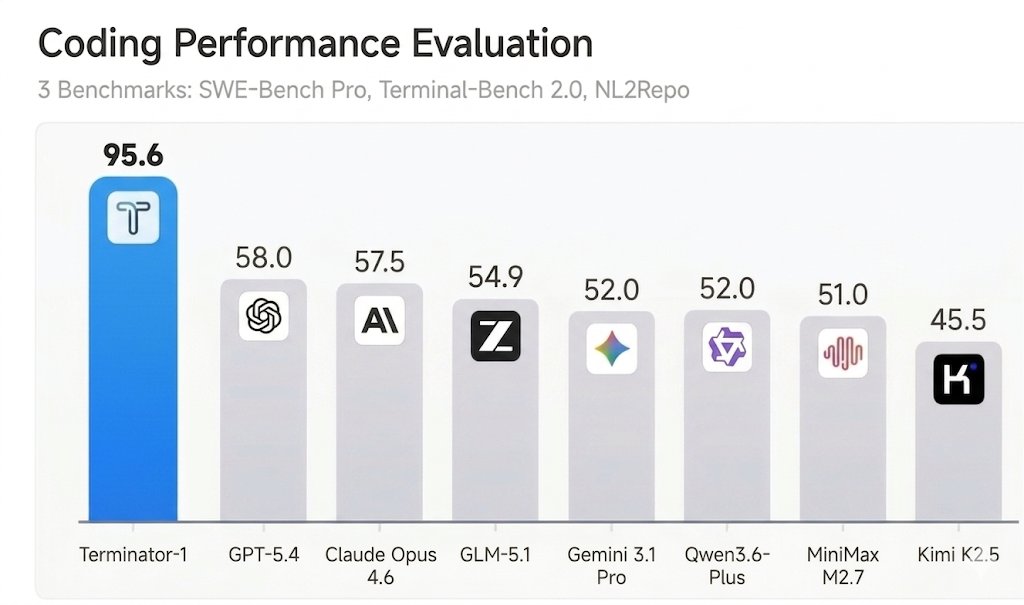
🎉We are excited to share Terminator-1, our newest agent that achieved 95+% on SWE-bench Verified and Terminal-Bench with @MogicianTony!
We show that besides model capabilities, well-designed harness could actually boost the accuracy by 3x in coding tasks.
Well if you really wanted you could get 100% accuracy without solving a single task.
The actual finding is that most AI benchmarks can be easily reward-hacked with simple exploits. Read more about the same 7 design flaws that almost every evaluation has ⬇️
Hao Wang@MogicianTony
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
English

























