I just claimed my .agent domain and joined the .agent community! get yours now and help shape the future of autonomous agents #6S894TFA" target="_blank" rel="nofollow noopener">agentcommunity.org/join#6S894TFA @agentcommunity_
English
Dis(𝔦, 𝔦)24/7
552 posts


It’s time. @IOTA_SN9’s Train at Home is available to all. We’ve opened the floodgates - everybody can join. Become a miner and build distributed models together - all on consumer-grade hardware and without any technical ML knowledge. Come on in. Join the swarm. Your actions will help define the world of distributed training. See the link below to download Train at Home on your Mac.

MIT just published a paper that quietly explains why LLM reasoning hits a wall and how to push past it. The usual story is that models fail on hard problems because they lack scale, data, or intelligence. This paper argues something much more structural: models stop improving because the learning signal disappears. Once a task becomes too difficult, success rates collapse toward zero, reinforcement learning has nothing to optimize, and reasoning stagnates. The failure isn’t cognitive, it’s pedagogical. The authors propose a simple but radical reframing. Instead of asking how to make models solve harder problems, they ask how models can generate problems that teach them. Their system, SOAR, splits a single pretrained model into two roles: a student that attempts extremely hard target tasks, and a teacher that generates new training problems. The catch is that the teacher is not rewarded for producing clever or realistic questions. It is rewarded only if the student’s performance improves on a fixed set of real evaluation problems. No improvement means zero reward. That incentive reshapes everything. The teacher learns to generate intermediate, stepping-stone problems that sit just inside the student’s current capability boundary. These problems are not simplified versions of the target task, and strikingly, they do not even require correct solutions. What matters is that their structure forces the student to practice the right kind of reasoning, allowing gradient signal to emerge even when direct supervision fails. The experimental results make the point painfully clear. On benchmarks where models start with zero success and standard reinforcement learning completely flatlines, SOAR breaks the deadlock and steadily improves performance. The model escapes the edge of learnability not by thinking harder, but by constructing a better learning environment for itself. The deeper implication is uncomfortable. Many supposed “reasoning limits” may not be limits of intelligence at all. They are artifacts of training setups that assume the world provides learnable problems for free. This paper suggests that if models can shape their own curriculum, reasoning plateaus become engineering problems, not fundamental barriers. No new architectures, no extra human data, no larger models. Just a shift in what we reward: learning progress instead of answers.


Imagine using a map app without algorithms. It would list every road and wish you luck. Algorithms weigh distance, traffic, and speed to give one route. The same logic powers search, medicine, fraud detection, and even space exploration. Rockets do not “go up and hope.” Algorithms constantly adjust thrust and direction in real time. More computing power alone would not save a rocket that cannot make decisions. Without algorithms, computers are just expensive storage boxes. $TIG









$REPPO is forming a clean Bull Flag inside a parallel channel. Not weakness — compression. When it breaks, it moves fast. Flags are meant to fly. 📈 ⛽️
@NewsFromGoogle This seems like an unreasonable concentration of power for Google, given that the also have Android and Chrome
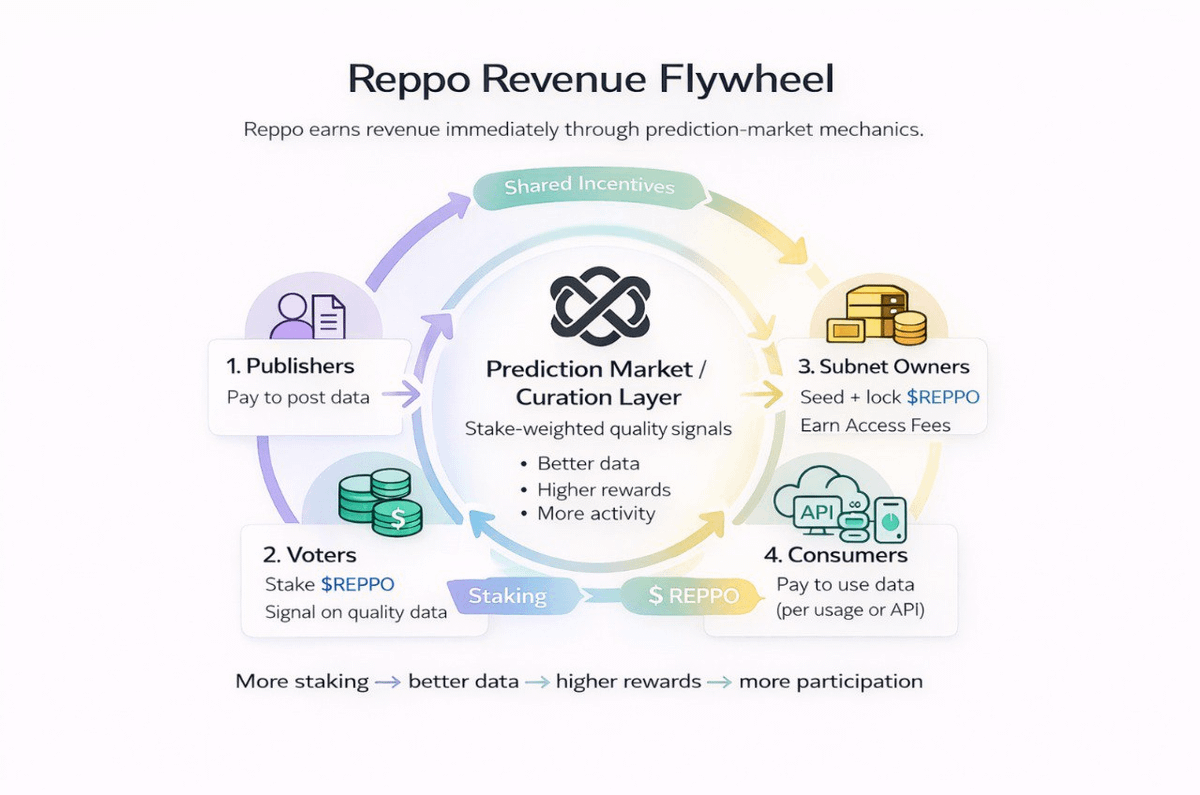
BREAKING: Hyperbet Partners with @reppo to Turn On-Chain Gaming Data into AI Training Signals We’re excited to collaborate with Reppo on advancing on-chain prediction markets and AI training on Virtuals Protocol. Reppo is building testnets to evaluate user feedback in prediction markets and transform that data into high-quality AI training signals. Through Hyperbet, real on-chain gameplay generates wallet-level behaviour data, which Reppo can use to assign risk profiles based on how wallets actually act. For example: a wallet playing 80 out of 100 USDC shows higher risk appetite than a wallet playing 100 USDC out of 10,000. Both are anonymous, but behaviour tells a much richer story than balances alone. By combining Hyperbet’s on-chain gaming data with Reppo’s modelling, AI systems can better understand risk, sentiment, and decision-making. The first Reppo testnet goes live January 21, where users can vote on games built by us and directly help train the model. We are excited to partner with one of the leading projects on @virtuals_io.