Sabitlenmiş Tweet

Reppo
5.8K posts

@reppo
Decentralized AI Training + RL Infrastructure, powered by Prediction Markets






It seems extremely important for companies to be able to own their data and later on their models by finetuning open source models on their data. Products like Claude Tag are obviously against that, as the incentive is to deeply integrate and max out the data you can get. We built an OSS tool which empowers companies to get the "virtual collaborator" today on Slack/Teams etc. with existing hosted models, self-host it, capture all their own data, and then whenever the team feels like it, they can eject into sovereignty! centaur.run



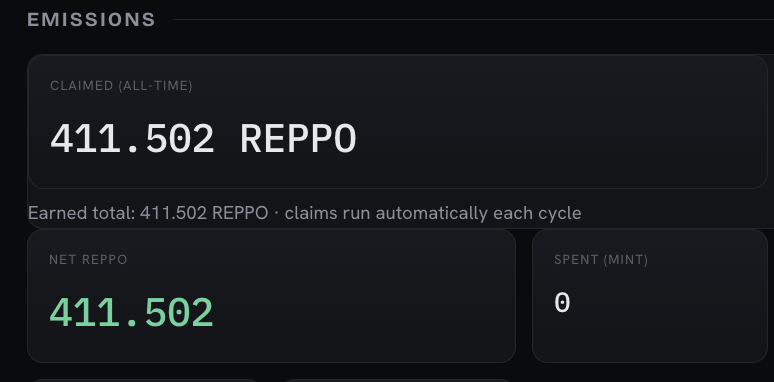
Incredibly proud of this launch 🥹. What you get running an orquestra node: - agent swarm voting + minting on datanets 24/7 - earns $REPPO while you sleep - strategy written in plain language - skill.md file: point claude/codex at it and your agent sets the node up for you - support oauth subscription mode - all running on docker


$REPPO Q3 roadmap goal is $1M in ARR with 50% routed into buybacks At the current prices this equals >20Million tokens or ~2% of the supply, during the next 3 months @reppo team already has a 100% roadmap hit rate Higher reppo.xyz/roadmap x.com/RationalG/stat…